チャーン分析/チャーン予測とは?実際に用いられる手法とPythonでの実装方法


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
サービスをグロースさせるためには当たり前ですがそのサービスが保有する会員数・契約者数を増やすことが大事。
そして、契約増加数は(新規契約数ー解約数)で表現することができます。
サービスローンチ直後は新規契約数をとにかく増やすことに注力するべきですが、ある程度安定した市場になってくると解約数をいかに減らすかが喫緊の問題になってきます。
例えば、日本の3大キャリアは新規契約数を取ることに躍起になり解約数を減らす手段がなかなかワークしていないのが現状です。
既存の顧客のロイヤリティを高めいかに解約数を減らすかが非常に重要になってきているのです。
そんな解約数を減らすために有用なのが「チャーン分析」と呼ばれる手法。
この記事ではそんなチャーン分析の特徴とPythonでの実装を見ていきたいと思います。

目次
チャーン分析とは

それでは、まずチャーン分析とは何なのか見ていきましょう!
以下のYoutube動画でも詳しく解説しています!
チャーン分析のチャーンとは、英語で「かき混ぜる・激しく動く」などの意味。そこからビジネスの世界でチャーンと言うと解約という意味を表します。
すなわちチャーン分析とは解約する顧客を予測するという分析手法。
解約予測なので、チャーン予測とも呼ばれます。
チャーン分析により正確に解約顧客を予測することが出来れば、効率よく解約顧客を減らすことができる可能性が高くなります。
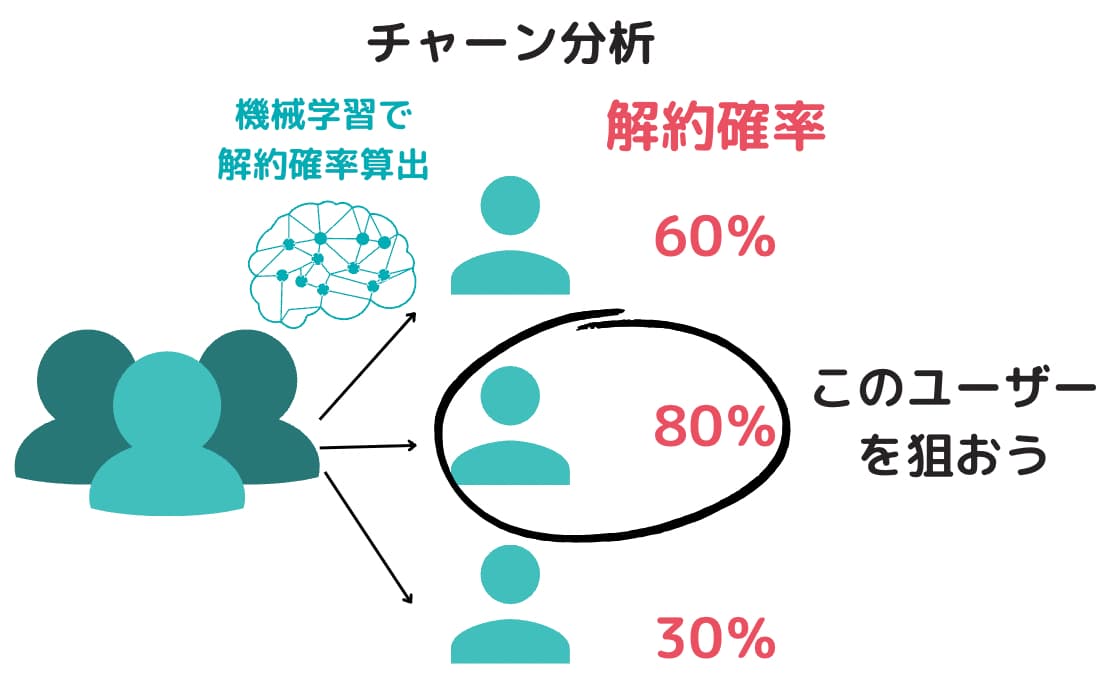
やみくもに解約数を減らそうとするのではなく、このままだと解約してしまいそうな人に対して適切な施策を打つことが可能になるのです。
チャーン分析に用いられる手法

チャーン分析においては予測するだけではなく、どの変数が解約に影響しているかを解釈する必要も出てきます。
分析手法には、精度に重きを置く手法と結果の解釈に重きを置く手法がありますのでそれぞれについて見ていきたいと思います。
ロジスティック回帰分析

ロジスティック回帰分析は、線形重回帰分析の応用であり線形回帰分析を拡張した手法であり、重回帰分析の仲間なので説明変数がどのくらい目的変数に寄与しているかも理解しやすく、今後の施策に活かしやすくなっています。
また、結果は0,1ではなく確率値で表現することが可能なため解約する確率が80%以上と予測された人に施策を打つなどと閾値を決めてアクションを取ることができるのが特徴です。
こちらは、結果の解釈に重きを置く手法。
予測精度だけ見ると、これから紹介する機械学習手法の方が高いことが多いです。
ロジスティック回帰分析に関してもっと詳しく知りたい方はこちらをご覧ください!
ランダムフォレスト
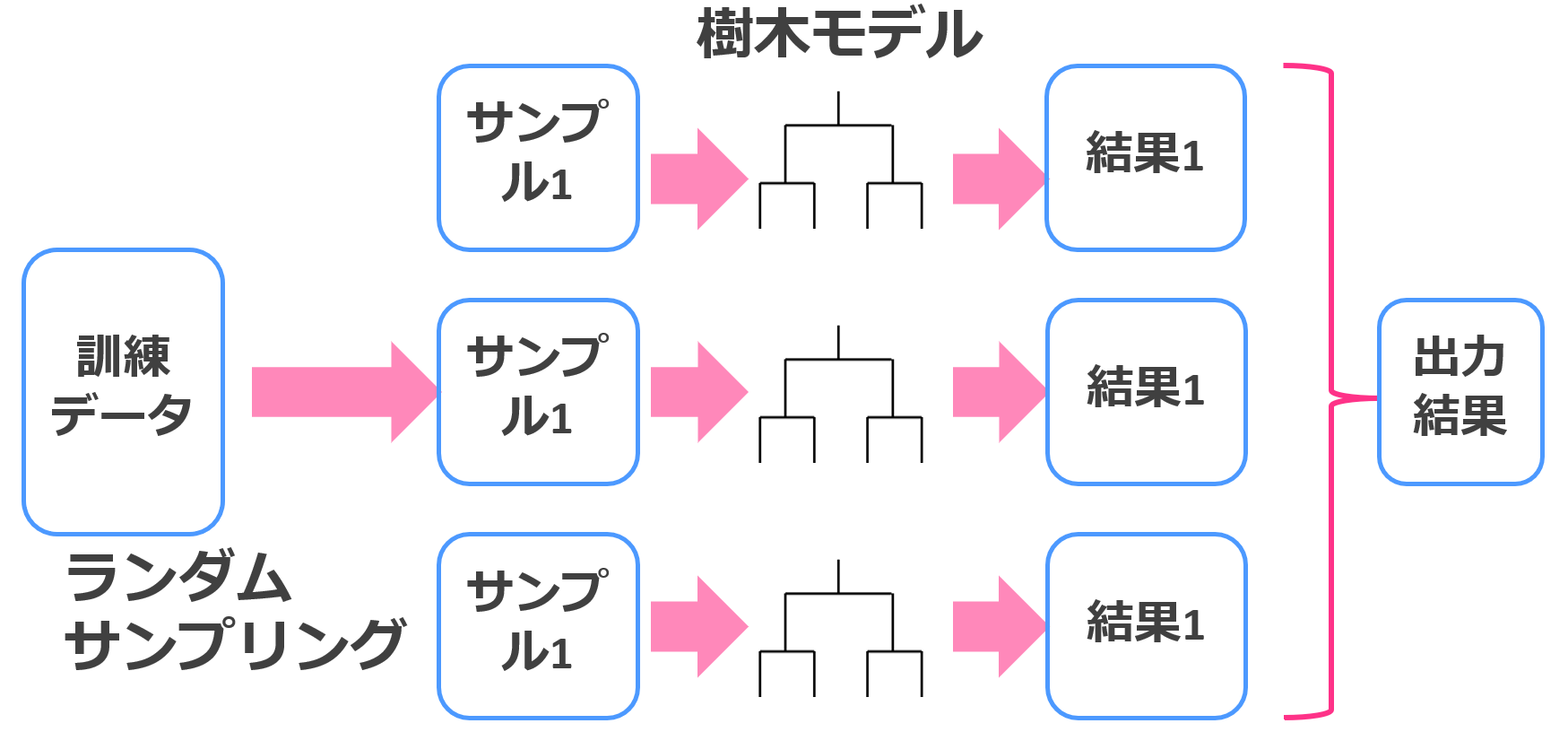
ランダムフォレストは、簡単な実装でかつ高速でそこそこ高い精度をたたき出せる便利な手法。
ざっくり言うと、
決定木をたくさん集めて合体させた手法
です。
決定木は単体だとそれほど強い手法ではありません。
しかし、その決定木をバギングと呼ばれる集団学習法を用いてたくさん集めてくると最強のランダムフォレストが出来上がるんです。
集団学習法は,決して精度が高いとはいえない弱いモデルをたくさん構築し,これらの予測結果を統合することで高い精度を出す方法論です。
ランダムフォレストでは変数重要度を算出することが可能でどの変数が寄与しているかは把握することが可能です。
ランダムフォレストに関してもっと詳しく知りたい方はこちらをご覧ください!

XGBoost
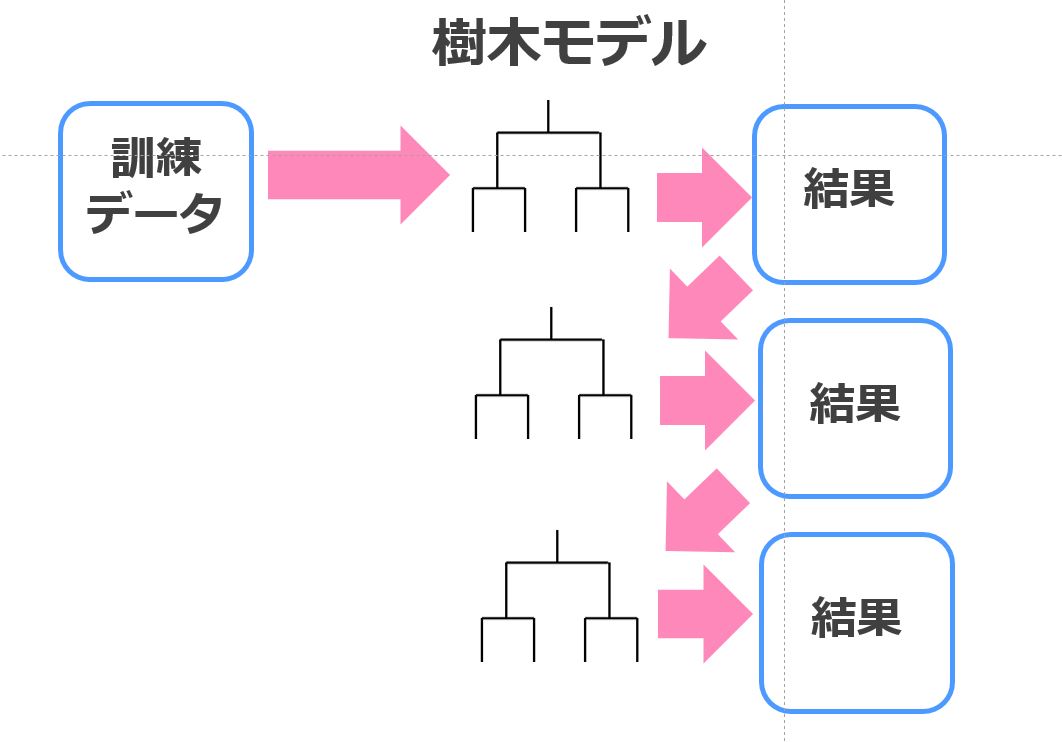
XGBoostもランダムフォレストと同じく決定木を基にした手法です。
ランダムフォレストはアンサンブル学習であるバギングを決定木と組み合わせていますが、XGBoostではアンサンブル学習であるブースティングを決定木と組み合わせています。
バギングは弱い学習器(決定木)が並列で多数決を行うことで効果を発揮するイメージですが、ブースティングは直列でチューニングを行い徐々に改善していくイメージです。
データセットやパラメータにもよりますが、ランダムフォレストよりもXGBoostの方が時間がかかる分精度が高い場合が多いです。
XGBoostでも変数重要度を算出することが可能です。
ただ、どの説明変数がどのくらい変化したら目的変数もどのくらい変化するかを算出するのはロジスティック回帰分析に得意とするところでXGBoostやランダムフォレストでは難しいです。
XGBoostに関して詳しくは以下の記事をご覧ください!

ちなみにXgboostを改良したLightGBMとCatboostもいかにまとめています!

チャーン分析による企業課題の解決を以下の小説でまとめていますので是非参考にしてみてください!

あまり具体的なデータサイエンティストの仕事について分かりやすく書いている本が見当たらなかったので自分で執筆しました!
ストーリー形式で分かりやすく書いていますので、目を通していただけるとイメージが湧くと思います。
価格は300円ちょっとですし、Kindle unlimitedであれば無料で読めるのでぜひチェックしてみてくださいね!
チャーン分析で気を付けなければいけないこと

チャーン分析で高い精度を算出するのは適切な変数さえ選べばそれほど難しくはありません。
ただ大事なのは、その結果をどのようにビジネスに落とし込むか。
例えばある変数が解約率にものすごく影響していることが分かったとしても、そのような変数は往々にして「これまでの継続月数」などアンコントローラブルであり解約に影響しているのは当たり前である変数なことが多いです。
仮に継続月数が長いほど解約率が低いという因果関係が分かったとして嬉しいでしょうか?
ふーん、まあ当たり前だよね、継続月数を伸ばすのが難しいんだよ、とそれだけではアクションに繋がりません。
そこでよく行われるのは、解約率によってユーザーをセグメント分けしそれぞれのセグメントに対してABテスト的にある施策を打ってみてその結果を受け今後の施策を使い分けるというモノ。
例えば、解約率20%以下ユーザーに過剰なクーポン施策を行うとチャーンレートが上がってしまうかもしれませんが、80%以上のユーザーに対しては過剰なクーポン施策が有効かもしれません。
ユーザーをセグメントに分けて効果検証を行うことで、ただの予測がアクションに結び付く結果になるのです。
実際にロジスティック回帰分析でチャーン分析をやってみよう!

ここでは簡易的にロジスティック回帰分析を使ってチャーン分析を行ってみます。
PythonでもRでも簡単に実装できますが、今回はPythonを使って実装してみます。
用いるのは、ライブラリscikit-learnに入っているdiabetesというデータセット。
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
print(diabetes.feature_names)[‘age’, ‘sex’, ‘bmi’, ‘bp’, ‘s1’, ‘s2’, ‘s3’, ‘s4’, ‘s5’, ‘s6’]
患者の状況と1年後の症状がデータとして入っています。
10個の説明変数に対して、症状を表す1つの量的変数が目的変数。
それぞれの変数については見ていかず予測精度だけ見ていきます。
チャーン分析にふさわしいデータセットが見つからなかったので、今回はこのデータセットを使って疑似的にチャーン変数を作っていきます。
1年後の症状は量的変数で入っているので、ここでは平均より高い場合は1、低い場合は0と無理やり変換して、ある患者の現在の症状から1年後の0・1症状を予測します。
本来であれば、解約をフラグの0,1に対して解約確率を算出するイメージです。
コードは以下。
アウトプットとしては、テストデータの0/1を予測したリストと、予測精度が算出されます。
array([0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 0, 1, 0, 0, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
予測精度=0.7149321266968326
疑似的にチャーン分析を行うことができました。
無理やり0/1変数を作り出したのでそれほど高い予測精度は出ておりません。
ここでは行いませんが、XGBoostやランダムフォレストで実装するともっと良い精度が出るでしょう。
また、回帰モデルの回帰係数を用いれば、それぞれのサンプルのチャーン確率を算出することができます。
チャーン確率によってユーザーをセグメント分けすることでビジネスチャンスが見出されるかもしれません。
チャーン分析 まとめ
本記事では、チャーン分析の説明と注意点、簡単な実装について見てきました!
チャーン分析を身に付ければビジネスに大きなインパクトを与えられること間違いなし!
チャーン分析の考え方自体は簡単ですが、
・どんな変数を持ってくるか
・どんな手法を使うか
・結果をどうビジネスに落とし込むか
はなかなか難しい。
統計学・機械学習・データサイエンス・AI・Pythonについて勉強したい方は以下の記事を参考にしてみてください!




また、詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
業界最安級AIデータサイエンス特化スクール:「スタビジアカデミー(スタアカ)」
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!