
Pythonのおすすめライブラリ18選!必須ライブラリを一覧で確認しよう!


こんにちは!スタビジ編集部です!
AIやデータ分析、自動化などを実現するため、”Python“を使ってWebアプリやサービスを開発する人が増えています。
Pythonは機能が充実していて、初心者にも学習がしやすい面から利用者の多いプログラミング言語です。
そんなPythonでの開発で欠かせないのが「ライブラリ」!
Pythonでは「ライブラリ」を活用することで、初心者でも簡単に高度なプログラムを実現できます。
一方でこんな悩みもあると思います。


そこで、本記事では、ぜひ押さえておきたいおすすめのPythonライブラリを紹介していきます。
Pythonについて基礎から体系的に学びたい人は当メディアが運営する「スタアカ」の以下のコースをチェックしてみて下さい。

以下のYouTube動画でも解説していますので合わせてチェックしてみてください!
Pythonのライブラリとは
Pythonの「ライブラリ(Library)」とは、特定の機能を簡単に使えるようにまとめられたプログラムの集合を指します。
ライブラリを使うことで、ゼロからコードを書かなくても、便利な機能をすぐに活用できます。
Pythonがプログラミング言語の中で人気である理由の一つにこのライブラリの充実度があります。
Pythonインストール時に提供される「Pythonの標準ライブラリ」だけでも便利な機能が豊富に揃っています。
それに加えて数多くのサードパーティ製(有志のコミュニティで作成された)ライブラリが提供されており、これらを活用することで効率的に開発を進めることが可能です。
実現したい内容に合わせて、適切なライブラリを選択することで、開発スピードを向上できるよ!
Pythonのライブラリを使うメリット
Pythonのライブラリを使うメリットは以下です。
・インストールすることで誰でも利用可能
・コーディングがシンプルになり、開発スピードが速くなる
・高度な機能を簡単に実装できる
Pythonのライブラリはインストールコマンド一つで、利用可能になります。
高度な機能がプログラムとして準備されているので、ライブラリの使い方に沿ってコードを書くことだけで、その機能を使うことができます。
実際に例を見て、メリットを実感してみましょう。
Pythonライブラリの実装サンプル
例えば、「テスト結果が記載されたcsvファイルを読み込んで平均値を計算する」プログラムを実装します。
ライブラリを使わない場合、以下例のようなコードになります。
# CSVファイルを開いて、1行ずつ読み込み、データを処理
data = []
with open("data.csv", "r", encoding="utf-8") as file:
lines = file.readlines()
headers = lines[0].strip().split(",") # ヘッダー取得
for line in lines[1:]:
values = line.strip().split(",") # 各行をカンマで分割
data.append(dict(zip(headers, values))) # ヘッダーと値を結びつける
# 平均値を計算(数値変換が必要)
total = sum(float(row["score"]) for row in data)
average = total / len(data)
print(f"平均スコア: {average:.2f}")
サンプルのcsvファイルと実行結果は以下です。
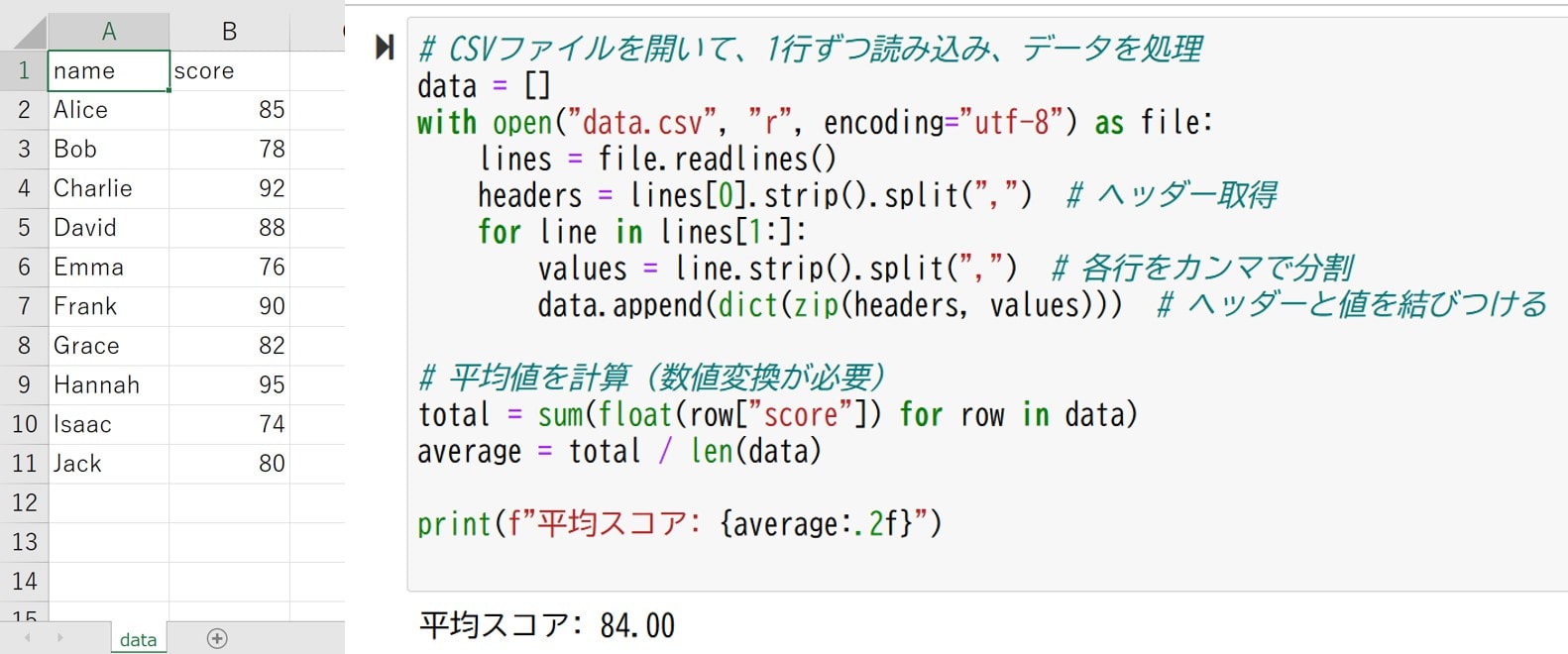
確かにこのプログラムでも平均スコアを出すことは出来てます。
ただ、csvファイルからカンマで分割して、必要な値を取り出して、配列に入れて、、、と処理を一から記述するのは大変ですよね
ではライブラリを使った場合を見ていきましょう。
import pandas as pd
df = pd.read_csv("data.csv") # 1行でCSVを読み込む
average = df["score"].mean() # 1行で平均値を計算
print(f"平均スコア: {average:.2f}")ライブラリなしの場合は、10行あったコードが4行に短縮されました。
実行結果も同じ結果が出力されています。

今回は実装イメージがつきやすいものを例にしましたが、ライブラリを使うと他にも機械学習やWebスクレイピングなど、一から実装するのが難しいようなものでも簡単にプログラムに組み込むことができます。
Pythonどんなライブラリがあるか、この後見ていこう!
Pythonのライブラリを使う注意点
とても便利なPythonのライブラリですが、利用の際には「いくつか注意点があること」を押さえておきましょう。
・ライブラリの中には依存関係があるものに注意
・セキュリティリスクに注意
・ライブラリの仕様に注意
それぞれ詳しく見ていきましょう。
ライブラリの中には依存関係があるものに注意
ライブラリには他のライブラリと依存関係があるものがあります。
例えば、データ処理に利用される”pandas“とデータの可視化に利用される”matplotlib“はどちらも”numpy“を利用します(依存します)。
そのため、pandasとmatplotlibで必要なnumpyのバージョンが違うとき、依存関係エラーでどちらかがインストールできない場合があるので注意が必要です。
セキュリティリスクに注意
Pythonのライブラリには企業がサポートしている公式のものから個人で作成しているものまであり、品質は様々です。
特に個人で作成しているものの中には、悪意のあるコードが含まれていたり、脆弱性があったりする場合があるので注意が必要です。
Pythonのライブラリをインストールする際は、ライブラリの開発者が信用できるか(組織が作成したものか、ドキュメントの有無、ダウンロード数などで判断)確認してからインストールしましょう。
ライブラリの仕様に注意
Pythonのライブラリは高度な機能を簡単に使えて便利ですが、その中身を全く知らなくていいということではないので注意してください。
例えばライブラリは日々バージョンアップされることが多いです。
基本的にはセキュリティ面や機能面でライブラリは常に最新バージョンにアップデートすることが望ましいとされています。
一方でバージョンアップによって、以前使えていたコマンドが使えなくなる場合があります。
そんな時、古いバージョンを使い続けるのではなく、ドキュメントを確認して、ライブラリの仕様を理解することが大切です。
Pythonのおすすめライブラリ一覧
Pythonのおすすめライブラリについて見ていきましょう。
Pythonで利用必須なライブラリは下記です。
| カテゴリ | ライブラリ | 説明 |
|---|---|---|
| データ解析・処理 | pandas | データ解析・加工の定番。ExcelやCSVのデータ操作が簡単 |
| numpy | 数値計算の基本ライブラリ。行列計算や統計処理が得意 | |
| openpyxl | Excelファイルを直接読み書きできる | |
| データ可視化 | matplotlib | グラフ作成の基本ライブラリ。カスタマイズ自由度が高い |
| seaborn | matplotlibの拡張版。美しい統計的グラフが作れる | |
| plotly | インタラクティブなグラフを作成。Web表示にも最適 | |
| 機械学習・ディープラーニング | scikit-learn | 機械学習の定番ライブラリ。分類、回帰、クラスタリングなど |
| XGBoost | 勾配ブースティングの強力なライブラリ。Kaggleで人気 | |
| lightgbm | 高速な決定木ベースの機械学習ライブラリ | |
| tensorflow | Google製の深層学習ライブラリ | |
| pytorch | Facebook製の深層学習ライブラリ。学習がしやすく人気 | |
| Web開発 | Flask | 軽量なWebフレームワーク。シンプルなAPI開発向け |
| Django | フルスタックのWebフレームワーク。大規模なWeb開発向け | |
| FastAPI | 高速なAPI開発向け。型ヒントを活用できる | |
| AI | OpenAI | ChatGPT・DALL·Eなどの生成AIを活用 |
| Langchain | LLMを統合・管理し、AIワークフローを最適化 | |
| OpenCV | 画像処理・顔認識・動画解析 | |
| transformers | BERT/GPTなどのNLPモデルを簡単に利用 |
それぞれ詳しく見ていきましょう。
データ解析・処理
Pythonではデータサイエンスや機械学習の場面でデータ解析・処理が求められます。
そんなデータ解析・処理によく利用されるライブラリは以下です。
・pandas
・numpy
・openpyxl
pandas
“pandas“はデータの読み込み・加工・集計・分析が簡単にできるライブラリです。
pandasの主な機能は下記です。
- CSV、Excel、SQL、JSON などのデータの読み込み・書き出し
- データのフィルタリング・ソート・集計
- 欠損値の処理やデータの結合
pandasの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

numpy
“numpy“は高速な数値計算が出来るライブラリで、特に行列計算が得意であり、大規模なデータの計算処理に最適です。
numpyの主な機能は下記です。
- 高速な配列処理
- 数学的処理(行列演算、統計計算)
numpyの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

openpyxl
“openpyxl“は、PythonでExcelファイルを読み書き編集できるライブラリです。
openpyxlの主な機能は下記です。
- Excelファイルの読み込み・書き出し
- セルの書式設定(色、フォント、サイズなど)
- シートの追加・削除・編集
- ピボットテーブルやグラフの作成
openpyxlの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

データ可視化
Pythonでは主にデータサイエンスの分野で、収集したデータや解析したデータを可視化して知見を見つけることが多いです。
そんなデータ可視化によく利用されるライブラリは以下です。
・matplotlib
・seaborn
・plotly
matplotlib
“matplotlib“は折れ線グラフ・棒グラフ・ヒストグラム・散布図など、幅広いグラフが作成可能なライブラリです。
matplotlibの主な機能は下記です。
- 基本的なグラフ(折れ線、棒、散布図、ヒストグラムなど)の作成
- 軸ラベル、凡例、タイトルの追加
- グラフのカスタマイズ(色、スタイル、フォントサイズなど)
matplotlibの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

seaborn
“seaborn“はmatplotlibを拡張し、統計データを簡単に可視化できるライブラリです。
seabornの主な機能は下記です。
- ヒートマップ、箱ひげ図、分布図など、統計データ向けの可視化
- グループごとの色分けやデータのトレンド分析
seabornの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

plotly
“plotly“はWeb上で動的なグラフを作成できるライブラリでプレゼンテーションやダッシュボード向けに最適です。
plotlyの主な機能は下記です。
- インタラクティブな折れ線グラフ、棒グラフ、散布図作成可能
- Webアプリに埋め込み可能(Dash との連携)
- ズーム、ホバー情報の表示、リアルタイム更新機能。
plotlyの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

機械学習・ディープラーニング
機械学習・ディープラーニングの分野でPythonでは強力なライブラリが多く用意されています。
・scikit-learn
・XGBoost
・lightgbm
・tensorflow
・pytorch
scikit-learn
“scikit-learn“は分類、回帰、クラスタリング、次元削減などの基本的な機械学習アルゴリズムを簡単に実装できるライブラリです。
scikit-learnの主な機能は下記です。
- ロジスティック回帰、決定木、ランダムフォレスト、SVMなどの教師あり学習
- K-means、DBSCANなどの教師なし学習
- PCAなどの次元削減
- データの前処理(正規化、特徴量エンジニアリング)
- 交差検証、ハイパーパラメータチューニング
scikit-learnの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

XGBoost
“XGBoost“は勾配ブースティング(Gradient Boosting)のライブラリで、決定木ベースのモデルを高速に学習できるのが特徴です。
XGBoostの主な機能は下記です。
- 高速な学習(並列計算・GPU対応)
- 分類・回帰・ランキングタスクに適用可能
XGBoostの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

lightgbm
“lightgbm“はXGBoostよりも軽量で高速な学習を実現するためにMicrosoftが開発したライブラリです。
lightgbmの主な機能は下記です。
- 超高速学習で数千万件の大規模データでもスムーズに学習可能
- リーフワイズで少ないツリーの深さで高精度なモデルを構築
- カテゴリ変数をそのまま学習に利用
lightgbmの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。
tensorflow
“tensorflow“はGoogleが開発したディープラーニング用のライブラリで、ニューラルネットワークを構築・学習するために最適化されています。
tensorflowの主な機能は下記です。
- CNN(畳み込みニューラルネットワーク)やRNN(リカレントニューラルネットワーク)
- 分散学習、GPU/TPU対応
- 事前学習済みモデルの利用
- Kerasを統合し、簡単なAPIで深層学習が可能
tensorflowを使ったCNN(畳み込みニューラルネットワーク)の実装方法を以下の記事で詳しく解説しているので参考にしてみて下さい。

pytorch
“pytorch“はFacebookが開発した柔軟で直感的なディープラーニングのライブラリで動的計算グラフを採用しており、直感的にモデルを作成・デバッグできるのが特徴です。
pytorchの主な機能は下記です。
- numpyのような使いやすいテンソル演算
- GPU対応で高速学習
- torchvisionで事前学習済みモデルを簡単に利用可能
pytorchの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

Web開発
Pythonを使ってWebアプリ開発される事例も多くあります。
Webアプリ開発ではライブラリよりも大きい範囲でアプリ全体の構造を提供するフレームワークを利用することが多いです。
フレームワークの中にライブラリが多く含まれるので、今回はPythonのWebアプリ開発でおすすめのフレームワークを紹介します。
・Flask
・Django
・FastAPI
フレームワークを使うことでWebアプリに必要な機能を簡単に実装出来るよ!
Flask
“Flask“はシンプルなPythonのWebフレームワークで、API開発や小規模なWebアプリに最適です。
Flaskの主な機能は下記です。
- ルーティング機能でURLごとに異なる処理(関数)を簡単に紐づけ可能
- テンプレートエンジン(Jinja2)で動的なHTMLページを生成
- リクエスト&レスポンス処理
Flaskの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。
Django
“Django“は、Pythonで大規模なWebアプリ開発に最適なフルスタックフレームワークです。
Djangoの主な機能は下記になります。
- データベース管理(Django ORM)
- ユーザーのログイン・認証機能が標準搭載。
- 管理画面(Django Admin)の作成
Djangoの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

FastAPI
“FastAPI“はPythonでのAPI開発を超高速に行えるフレームワークです。
FastAPIの主な機能は下記です。
- 非同期処理で高速なAPIレスポンス
- Swagger UIの自動生成
- 型ヒントを活用し、リクエストデータを自動チェック
FastAPIの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

AI
AI分野ではPythonにる開発が主流です。
そんなAIでのおすすめのライブラリは以下です。
・OpenAI
・Langchain
・OpenCV
・transformers
OpenAI
“OpenAI“はテキスト生成・画像生成・翻訳などのAI機能を手軽に実装できるライブラリです。
OpenAIの主な機能は下記です。
- gpt-3.5-turboやgpt-4を利用し、文章の自動生成や要約が可能。
- DALL·Eを使った画像生成
- 音声認識&音声合成
OpenAIのライブラリで様々な生成AIモデルを呼び出すことができます。
OpenAIのよく使われれるGPTについては以下の記事で詳しく解説しているので参考にしてみて下さい。

Langchain
“Langchain“は大規模言語モデル(LLM)を簡単に活用できるライブラリです。
Langchainの主な機能は下記です。
- LLMのチェーン(連携処理)を簡単に作成
- プロンプト管理
- 外部データとの連携
Langchainについては以下の記事で詳しく解説しているので参考にしてみて下さい。
OpenCV
“OpenCV“は画像処理やコンピュータービジョンの分野で最も広く使われているライブラリで、カメラ映像の解析、物体認識、顔検出など、多くの用途に対応可能です。
OpenCVの主な機能は下記です。
- 画像処理(画像のフィルタリング、エッジ検出、ノイズ除去)
- 物体検出(顔検出、バーコード認識、動作解析)
- 動画解析(動画フレームの処理、リアルタイム画像処理)
OpenCVの使い方については以下の記事で詳しく解説しているので参考にしてみて下さい。

transformers
“transformers“はHugging Faceが開発したライブラリで、BERTやGPTなどの事前学習済みモデルを簡単に利用でき、特に自然言語処理(NLP)の分野で広く使われています。
transformersの主な機能は下記です。
- 自然言語処理の事前学習済みモデル(BERT、GPT、T5、DistilBERTなどの最先端モデル)を活用可能
- テキスト分類・翻訳・要約・質問応答
- トークナイザー&ファインチューニング(データの前処理や独自データでの微調整が可能)
transformersに関しては以下の記事で詳しく解説しているので参考にしてみて下さい。
Python おすすめライブラリ まとめ
Pythonのおすすめライブラリについて再度一覧を紹介します。
| カテゴリ | ライブラリ | 説明 |
|---|---|---|
| データ解析・処理 | pandas | データ解析・加工の定番。ExcelやCSVのデータ操作が簡単。 |
| numpy | 数値計算の基本ライブラリ。行列計算や統計処理が得意。 | |
| openpyxl | Excelファイルを直接読み書きできる。 | |
| データ可視化 | matplotlib | グラフ作成の基本ライブラリ。カスタマイズ自由度が高い。 |
| seaborn | matplotlib の拡張版。美しい統計的グラフが作れる。 | |
| plotly | インタラクティブなグラフを作成。Web表示にも最適。 | |
| 機械学習・ディープラーニング | scikit-learn | 機械学習の定番ライブラリ。分類、回帰、クラスタリングなど。 |
| XGBoost | 勾配ブースティングの強力なライブラリ。Kaggleで人気。 | |
| lightgbm | 高速な決定木ベースの機械学習ライブラリ。 | |
| tensorflow | Google製の深層学習ライブラリ。 | |
| pytorch | Facebook製の深層学習ライブラリ。学習がしやすく人気。 | |
| Web開発 | Flask | 軽量なWebフレームワーク。シンプルなAPI開発向け。 |
| Django | フルスタックのWebフレームワーク。大規模なWeb開発向け。 | |
| FastAPI | 高速なAPI開発向け。型ヒントを活用できる。 | |
| AI | OpenAI | ChatGPT・DALL·Eなどの生成AIを活用 |
| Langchain | LLMを統合・管理し、AIワークフローを最適化 | |
| OpenCV | 画像処理・顔認識・動画解析 | |
| transformers | BERT/GPTなどのNLPモデルを簡単に利用 |
これらのライブラリを一通り使いこなせれば、いろんなアプリケーションを実装することができます。
また、初心者だけど本格的にPythonでアプリ開発をやってみたい方は、当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」を以下の講座チェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムですので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















