
傾向スコアを使ったマッチングや逆確率重み付け法(IPW)についてPython実装法と共に分かりやすく解説!


こんにちは!データサイエンティストのウマたん(@statistics1012)です。
統計的因果推論とは変数間の因果関係をデータから明らかにしようという分野で、ビジネスシーンでよく登場します。
そんな統計的因果推論の世界で、おさえておきたいのが傾向スコア。
この記事で学んで、しっかり理解しておきましょう!
ちなみに、傾向スコアについて詳しく知りたい方は以下の私のUdemy講座で学べますのでチェックしてみてください!
【初心者向け】統計的因果推論を学びPythonで実装していこう!RCT・層別解析・マッチング法・傾向スコアを学ぼう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
統計的因果推論について詳しく知りたいならこのコース!
今なら購入時に「B3PS3TPL8ZWG」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
また、以下のYouTube動画でも解説していますので合わせてチェックしてみてください!
相関関係と因果関係
さて、まずは相関関係と因果関係の違いについて見ていきましょう!
例えば、「年収と一日の平均摂取カロリーには負の相関関係がある」
と聞いたらみなさんはどのように思いますか?
「よっしゃ!年収をあげるためにカロリーを抑えよう!」と思うでしょうか?
でも実際にはカロリーを低く抑えることによって年収が上がるということは期待されません。
なぜなら相関関係があったとしても因果関係があるとは限らないからです。
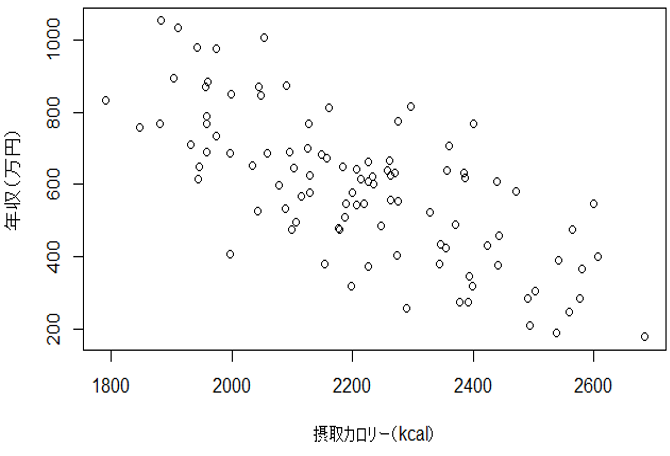
さて、先ほどの「年収と一日の摂取カロリー」には相関関係があることは間違いないです。
しかし、経験的に一日の摂取カロリーを低くしても年収が上がるという因果関係は認められないと思います。
それではなぜ「年収」と「摂取カロリー」の間に相関関係が見られたのでしょうか?
それは、「年収」と「摂取カロリー」の裏に「年齢」という隠れた因子が存在するからです。
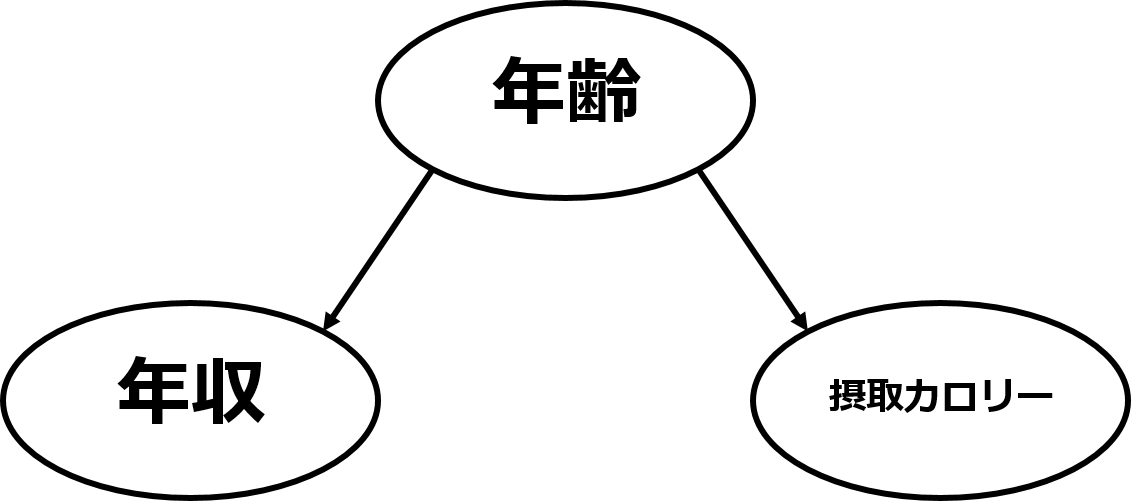
一般的に年齢が高くなると年収は上がります。そして年齢が高くなると摂取カロリーは低くなるでしょう。
そのため摂取カロリーが低い人ほど年収が高くなったのです。
このような変数間の構造のことを交絡と呼びます。
また、交絡しているときの相関を擬似相関(偽相関)と呼びます。
大事なのは相関関係があっても因果関係があるとは限らないということです。

傾向スコアが必要な場面
相関と因果の違いが分かったところで、傾向スコアが必要な場面について見ていきましょう!
ランダム化比較実験というアプローチができれば、それに越したことはないのですがそうでない場合は、様々なアプローチを考えなくてはならず、そのうちの1つが傾向スコアを使ったアプローチなのです。
どういうことか見ていきましょう!
例えば、ある新薬を飲んでもらう群と通常のビタミン剤を飲んでもらう群に分けて新薬の効果を見る実験をするとします。
この時、ある集団を新薬を飲んでもらう群(実験群・介入群・処置群などと呼ぶ)とビタミン剤を飲んでもらう群(対照群・統制群・コントロール群などと呼ぶ)に分けて、結果の差を見ます。
集団の中のそれぞれの対象が介入群と対照群のどちらになるかを決定させることを割り付けと呼びます。
では、集団をどのように割り付ければ良いでしょうか。
例えば、男性なら新薬を飲んでもらい、女性ならビタミン剤を飲んでもらうという割り付けをしてみます。
すると、確かに結果の差を得ることは出来ますが、果たしてそれは新薬の効果によるものなのでしょうか。性別に由来する影響かもしれません。
この場合、性別のことを交絡因子と呼びます。
このように割り付けを適切に行わないと交絡を引き起こしてしまいます。
結局、如何にして交絡に対処するかが重要ということです。
因果効果を測定するには交絡因子を調整する必要があります。
ここで登場する最も最適な方法が、割り付けを完全にランダムに行う方法でありランダム化比較実験(Randomized Controlled Trial;RCT)と呼ばれるのです。
RCTでは例えば、一人一人にコインを投げてもらい表なら介入群、裏なら対照群とします。
これによって、いろんな潜在的な交絡因子があっても二つの群の分布は平均的に等しくなることが期待されます。
RCTに関して詳しくは以下の記事をチェックしてみてください。

このRCTが実行できればよいのですが、そうとは限らないのが現実世界。
例えば、タバコと肺がんの関係を調べるために、ランダムに割り付けた人々に一日10本のタバコを吸ってもらい肺がんになるまで実験するというのは倫理的に不可能です。
また、コストの問題もありますし、そもそもすでにデータが得られている場合にはどうしようもありません。
実験研究とは異なり割り付けがランダム化されていない方法は観察研究と呼ばれます。
現実問題では、観察データが多いこともあり、その場合は別のアプローチを試す必要があるのです。
そんな別のアプローチの1つが傾向スコアを使ったアプローチというわけです。
それではそんな傾向スコアについて見ていきましょう!
傾向スコアとは?
傾向スコアとは介入群に割り付けられることを1、対照群に割り付けられることを0として、(複数の)交絡因子を与えたときの事後確率のことです。
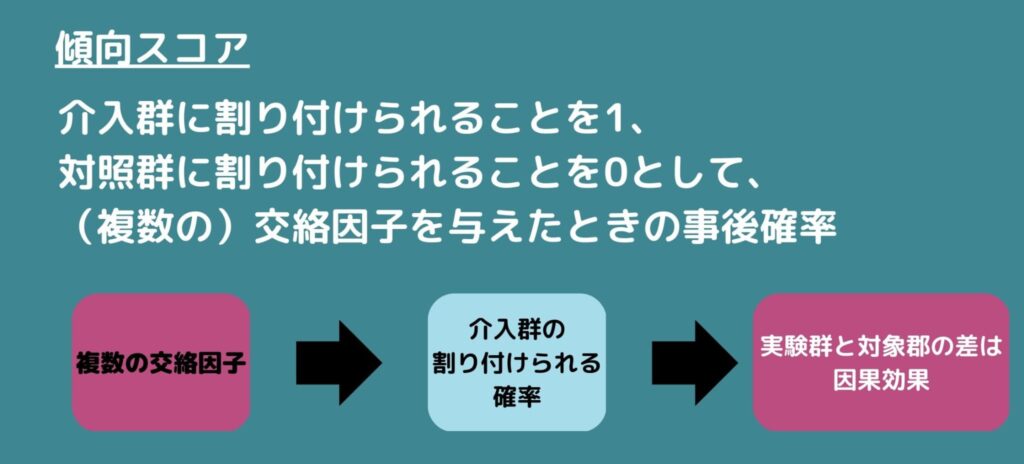
複数の交絡因子を介入群への割り付けられやすさという一変量に集約することで解析します。
事後確率の算出には一般的にロジスティック回帰かプロビット回帰が用いられますが、別に機械学習の手法でも構いません。
傾向スコアは他の様々の手法達とあわせて用いられます。
傾向スコアを区切って層別解析、傾向スコアを説明変数に入れて回帰モデルを作成、傾向スコアが近いものでマッチングなどです。
これらの手法群に興味のある方は以下の記事で網羅的に説明していますのでチェックしてみてください!

また、介入群と対照群の結果の差をバイアスなく推定するために逆確率重み付け法(Inverse Probability Weighting;IPW)や二重にロバストな方法があります。
傾向スコアにもデメリットがあり未観測の交絡因子には対応のしようがありません。
傾向スコアを使ったマッチング法をPythonで実装
それでは実際に傾向スコアを使ったアプローチをPythonで実装していきましょう!
今回は血圧を下げるサプリの効果があるのかないのか確かめるケースを考えてみます。
まず、血圧を下げるサプリを試したい人を公募で募集し、彼らに血圧を下げるサプリを試して、それをサプリを摂取していない一般人と比較しました。
そもそも年齢が高く血圧が高い人ほど血圧を下げるサプリを飲みたいと思い応募してきている可能性があります。
また、年齢以外にも太っている人ほど血圧が高く血圧を下げるサプリを飲みたいと思い応募してきている可能性もあります。
すなわち比較対象には年齢とBMI(太っているかどうかの指標)という交絡因子が存在することが考えられます。
この誤った実験設定をそのままPythonコードに落とし込んでいきましょう!
import numpy as np
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import NearestNeighbors
np.random.seed(42)
# --- データ生成 ---
N_obs = 1000
# 交絡因子: 年齢(Age), BMI
Age_obs = np.random.normal(50, 10, size=N_obs)
BMI_obs = np.random.normal(25, 4, size=N_obs)
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# サプリを飲む確率: Age, BMIに依存
# 年齢が高い (Age>50), BMIが高い (BMI>25) ほど確率UPと設定
p_supp_obs = sigmoid(0.3 * (Age_obs - 50) + 0.2 * (BMI_obs - 25))
# 実際のサプリ服用フラグ (0 or 1)
Supplement_obs = np.random.binomial(1, p_supp_obs)
# 血圧生成(年齢とBMIが高いと上がり、サプリ服用で-4.0下がる)
BloodPressure_obs = 130 + 0.3 * Age_obs + 0.4 * BMI_obs - 4.0 * Supplement_obs + np.random.normal(0, 5, size=N_obs)
# pandas DataFrame化
df_obs = pd.DataFrame({
'Age': Age_obs,
'BMI': BMI_obs,
'Supplement': Supplement_obs,
'BloodPressure': BloodPressure_obs
})
# --- 年齢・BMIを無視した単純比較 ---
mean_bp_supp_obs = df_obs[df_obs['Supplement'] == 1]['BloodPressure'].mean()
mean_bp_nosupp_obs = df_obs[df_obs['Supplement'] == 0]['BloodPressure'].mean()
diff_obs_naive = mean_bp_supp_obs - mean_bp_nosupp_obs
print(f"サプリ群 平均血圧: {mean_bp_supp_obs:.2f}")
print(f"非サプリ群 平均血圧: {mean_bp_nosupp_obs:.2f}")
print(f"単純比較(サプリ - 非サプリ): {diff_obs_naive:.2f}")
このコードの流れを見ていきましょう!
課題設定に沿って、1000人を対象に年齢が高いほどサプリを飲みやすいというような条件設定にします。
まず、Age_obs = np.random.normal(50, 10, size=N_obs)の部分で、年齢を平均50・標準偏差10の正規分布に従う形でランダムに1000個生成しています。
続いて、BMI_obs = np.random.normal(25, 4, size=N_obs)の部分ではBMIを平均25・標準偏差4で1000個生成していることが分かります。
続いて、sigmoidでシグモイド関数を定義しています。シグモイド関数はロジスティック回帰などに用いられる関数で、入力の値は0~1の範囲に変換します。
すなわち数値を確率に変換する時に役立ちます。
入力が0の場合は出力は0.5になり、それより小さくなればなるほど0に近づき、大きければ大きいほど1に近づくのです。
今回は年齢とBMIを入力にしてサプリを飲む確率値を出力したいので、シグモイド関数を用いているのです。
さて、この関数の入力には0.3 * (Age_obs – 50) + 0.2 * (BMI_obs – 25)を入れているので50歳でBMIが25の人はちょうど0.5の確率が出力されるようになっているわけですね。
年齢が高くてBMIが高い人はサプリを飲む傾向が高いような設計になっています。
続いて、Supplement_obs = np.random.binomial(1, p_supp_obs)の箇所では、二項分布に基づいて、確率値からサプリを飲むか飲まないかを0,1で出力しています。
続いて、以下の式では血圧の計測結果を出力しています。
BloodPressure_obs = 130 + 0.3 * Age_obs + 0.4 * BMI_obs - 4.0 * Supplement_obs + np.random.normal(0, 5, size=N_obs)
年齢が高ければ高いほどBMIが高ければ高いほど血圧が高くなり、サプリを飲んでいれば血圧が下がるような式になっています。
また個体差を出すために、乱数も発生させて加えています。
この結果をデータフレームに格納し、サプリを摂取した群としていない群の平均を比較してみると・・・結果は以下のようになりました。
サプリ群 平均血圧: 153.31
非サプリ群 平均血圧: 152.98
単純比較(サプリ – 非サプリ): 0.33
本来であればサプリの効果があるはずなのに、ほぼ差がないことが分かります(※今回サプリを飲んでいるか否かで4.0を足しているので、本来であれば単純比較の差が4近くなるはず)。
それではこちらに対して傾向スコアを使ってマッチングをおこなって結果がどうなるか見ていきましょう!
lr = LogisticRegression()
# 説明変数: Age, BMI / 目的変数: Supplement
lr.fit(df_obs[['Age', 'BMI']], df_obs['Supplement'])
# predict_proba()[:,1] で「サプリ=1となる確率」を傾向スコアにする
df_obs['probability'] = lr.predict_proba(df_obs[['Age', 'BMI']])[:, 1]
df_treated = df_obs[df_obs['Supplement'] == 1].copy()
df_control = df_obs[df_obs['Supplement'] == 0].copy()
# 最近傍マッチング: probabilityを基準
nbrs = NearestNeighbors(n_neighbors=1).fit(df_control[['probability']])
distances, indices = nbrs.kneighbors(df_treated[['probability']])
# マッチされた非サプリ群を取得
matched_controls = df_control.iloc[indices.flatten()].copy()
matched_controls.index = df_treated.index # インデックスを合わせる
# マッチング後のサンプルを結合
df_matched = pd.concat([df_treated, matched_controls])
# マッチング後の効果推定
mean_bp_supp_matched = df_matched[df_matched['Supplement'] == 1]['BloodPressure'].mean()
mean_bp_nosupp_matched = df_matched[df_matched['Supplement'] == 0]['BloodPressure'].mean()
ate_psm = mean_bp_supp_matched - mean_bp_nosupp_matched
print(f" サプリ群 平均血圧: {mean_bp_supp_matched:.2f}")
print(f" 非サプリ群 平均血圧: {mean_bp_nosupp_matched:.2f}")
print(f" 推定されたサプリ効果: {ate_psm:.2f} (サプリ - 非サプリ)")
具体的にコードの中身を見ていきましょう!
ます最初の以下の部分でロジスティック回帰を用いて年齢とBMIからサプリを飲む確率を推定しています。
lr = LogisticRegression()
# 説明変数: Age, BMI / 目的変数: Supplement
lr.fit(df_obs[['Age', 'BMI']], df_obs['Supplement'])
# predict_proba()[:,1] で「サプリ=1となる確率」を傾向スコアにする
df_obs['probability'] = lr.predict_proba(df_obs[['Age', 'BMI']])[:, 1]
その後に傾向スコアを使ったマッチングに入っていきます。
lr = LogisticRegression()
# 説明変数: Age, BMI / 目的変数: Supplement
lr.fit(df_obs[['Age', 'BMI']], df_obs['Supplement'])
# predict_proba()[:,1] で「サプリ=1となる確率」を傾向スコアにする
df_obs['probability'] = lr.predict_proba(df_obs[['Age', 'BMI']])[:, 1]
df_treated = df_obs[df_obs['Supplement'] == 1].copy()
df_control = df_obs[df_obs['Supplement'] == 0].copy()
# 最近傍マッチング: probabilityを基準
nbrs = NearestNeighbors(n_neighbors=1).fit(df_control[['probability']])
distances, indices = nbrs.kneighbors(df_treated[['probability']])
# マッチされた非サプリ群を取得
matched_controls = df_control.iloc[indices.flatten()].copy()
matched_controls.index = df_treated.index # インデックスを合わせる
matched_diff = df_treated['BloodPressure'] - matched_controls['BloodPressure']
ate_matching = matched_diff.mean()
print(f" 推定されたサプリ効果: {ate_matching:.2f}")
ここでは、マッチングにk近傍法という手法を用いています。
k近傍法は、ざっくり言うと特定のサンプルに近いk個のサンプルを見つけるという手法。
これにより、サプリ摂取群の特定サンプルの傾向スコアが近いサンプルを非サプリ摂取群から見つけてきて、それらの差を取ることができます。
傾向スコアが近いユーザー=交絡因子による影響が少ないユーザーなので、これらのユーザーを比べることでサプリの因果効果を正しく把握できるというわけです。
結果は以下のようになりました。
推定されたサプリ効果: -5.51
本来のサプリの効果である4.0にだいぶ近くなったのが分かると思います。
傾向スコアを使った逆確率重み付け法(IPW)をPythonで実装
続いて傾向スコアを使った逆確率重み付け法(IPW)について見ていきましょう!
早速ですがコードは以下のようになります。
# 重みの列を作る
df_obs['weight'] = 0.0
df_obs.loc[df_obs['Supplement'] == 1, 'weight'] = 1.0 / df_obs.loc[df_obs['Supplement'] == 1, 'probability']
df_obs.loc[df_obs['Supplement'] == 0, 'weight'] = 1.0 / (1.0 - df_obs.loc[df_obs['Supplement'] == 0, 'probability'])
# 重み付き血圧
df_obs['weighted_bp'] = df_obs['BloodPressure'] * df_obs['weight']
# サプリあり・なし それぞれの重み合計
sum_wt_supp = df_obs.loc[df_obs['Supplement'] == 1, 'weight'].sum()
sum_wt_nosupp = df_obs.loc[df_obs['Supplement'] == 0, 'weight'].sum()
# 重み付き平均血圧
mean_bp_supp_weighted = df_obs.loc[df_obs['Supplement'] == 1, 'weighted_bp'].sum() / sum_wt_supp
mean_bp_nosupp_weighted = df_obs.loc[df_obs['Supplement'] == 0, 'weighted_bp'].sum() / sum_wt_nosupp
# IPWによるATE
ate_ipw = mean_bp_supp_weighted - mean_bp_nosupp_weighted
print(f" サプリ群 平均血圧 (重み付): {mean_bp_supp_weighted:.2f}")
print(f" 非サプリ群 平均血圧 (重み付): {mean_bp_nosupp_weighted:.2f}")
print(f" 推定されたサプリ効果: {ate_ipw:.2f}")
逆確率重み付け法では傾向スコアの値を元に血圧に重み付けをしていきます。
サプリ摂取した人の中で、サプリ摂取確率の高い人の重みは小さくサプリ摂取確率の低い人の重みは大きく設定します。
またサプリを摂取しなかった人の中で、サプリ摂取確率の低い人の重みは小さくサプリ摂取確率の高い人の重みは大きく設定します。
これは年齢やBMIによって歪んだ分布をならすためです。
元のデータは「年齢とBMIの偏り」があって、サプリを飲む人と飲まない人の分布が異なります。
それに対して、逆確率重みをかけることで、実際のデータ内の「サプリ群」と「非サプリ群」の分布を均一にします。
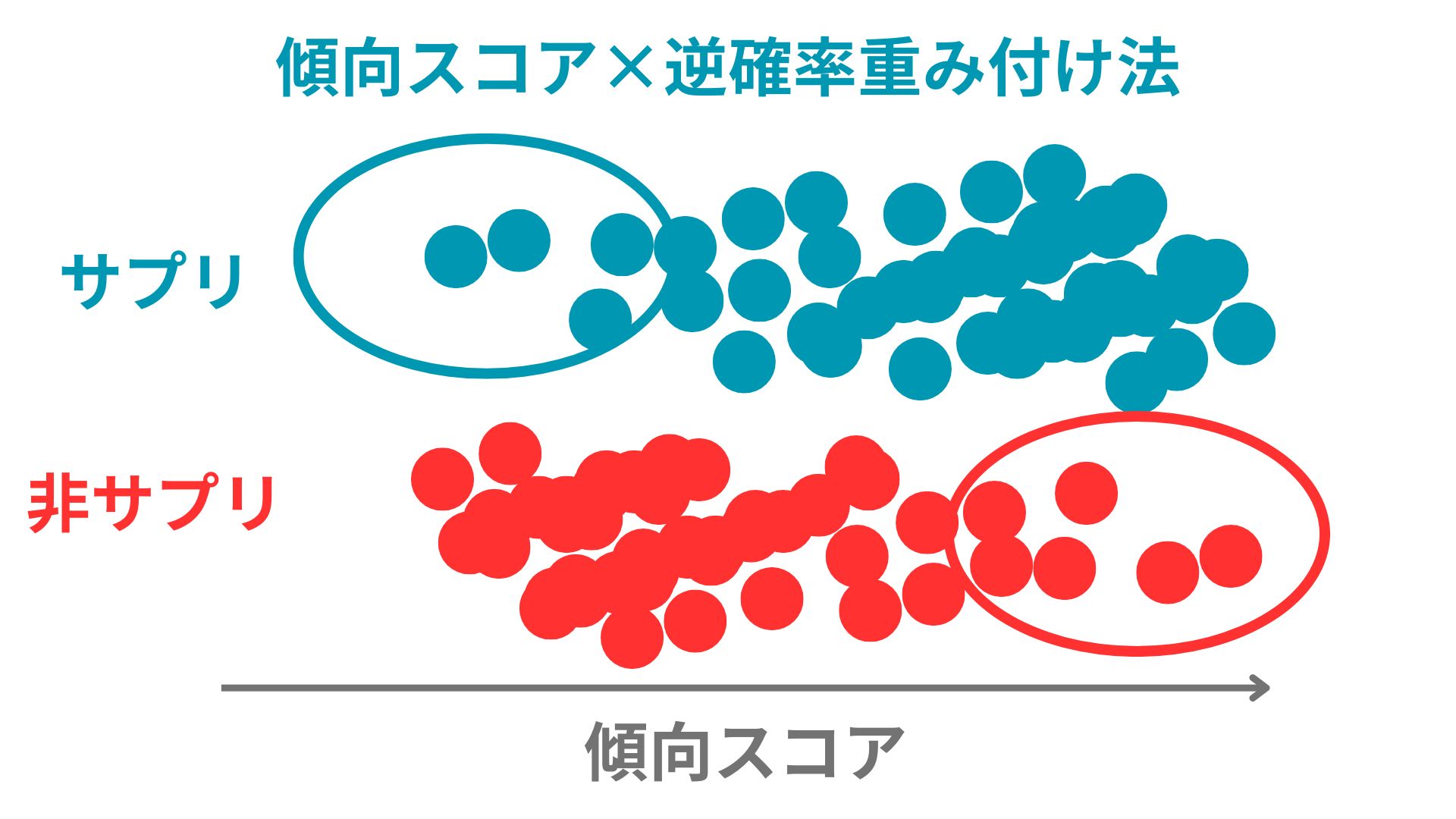
こうすることで、「まるでサプリの有無がランダムに決められたかのようなデータ」を作ることができるのです。
そして最終的に重み付け平均を取ったものの差を取っています。
結果は以下の通りになりました。
サプリ群 平均血圧 (重み付): 151.86
非サプリ群 平均血圧 (重み付): 155.80
推定されたサプリ効果: -3.94
サプリの真の効果である4.0にかなり近い値になっていることが分かりますね!
統計的因果推論には、他にも色々なアプローチがあるので以下の記事でチェックしてみましょう!

傾向スコア まとめ
ここまでで統計的因果推論の1種のアプローチである傾向スコアについて解説してきました。
RCTが難しい時は、この傾向スコアが比較的単純にできてオススメです。
ぜひ使えるようになっておきましょう!
統計的因果推論の分野には、他にもたくさんの手法があります。
他の手法について知りたい方は以下の記事でチェックしてみてください!
また、統計的因果推論について詳しく知りたい方は以下の私のUdemy講座で学べますのでチェックしてみてください!
【初心者向け】統計的因果推論を学びPythonで実装していこう!RCT・層別解析・マッチング法・傾向スコアを学ぼう!
| 【時間】 | 3.5時間 |
|---|---|
| 【レベル】 | 初級 |
統計的因果推論について詳しく知りたいならこのコース!
今なら購入時に「B3PS3TPL8ZWG」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















