
アンサンブル学習とは?バギングとブースティングとスタッキングの違いと注意点


こんにちは!
デジタルマーケター兼データサイエンティストのウマたん(@statistics1012)です!
様々な機械学習が登場する中、地味に存在感を強めているのがアンサンブル学習。
アンサンブル学習は、単独では強い手法ではない手法を多数使って精度を上げる方法。
Kaggleなどのデータ分析コンペで用いられることの多い、XGboostやLightGBMもアンサンブル学習の1つであるブースティングを用いています。
この記事では、そんなアンサンブル学習について見ていきます。
以下のYoutube動画でも解説しています!
目次
アンサンブル学習とは
アンサンブル学習とは、単独では精度の高くない弱学習器(決定木などなど)を多数用いることで高い精度をたたき出す手法群です。
※手法として確立されているのは弱学習器をアンサンブルする方法ですが、KaggleなどのデータコンペではCNNやXgboostなど単体で強力な手法を組み合わせることで予測精度を上げる方法が使われます。
アンサンブル学習に関しては「バイアス」と「バリアンス」という概念が関係してきます。
バイアスは、推定値と実測値の差を表します。
バイアスが低ければ低いほど上手く予測出来ているということになります。
一方バリアンスは、推定値のばらつきを表します。
複雑なモデルを組んで様々なデータへフィッティングさせようとすると予測値がばらつきバリアンスは高くなります。
バイアスとバリアンスはトレードオフの関係にあります。
ばらつきのあるデータに対してそれらを上手く当てることが出来ればバイアスは小さくなりますがバリアンスは大きくなることが想像できるでしょう。
一方それほどばらつきのない一定の予測値を返すと、精度は低いのでバイアスは高くなりますがバリアンスは小さくすることが可能です。
ちなみにバイアスが低くてバリアンスが高い状態は過学習に陥っている可能性が高く、未知データに対する予測精度は落ちてしまう可能性があります。
Kaggleなどのコンペでは現状のデータに対する精度で仮順位が決められます。
過学習をしていると仮順位は高いのですが、本番で一気に順位が下がってしまうのです。
過学習には注意しなくてはいけません。
アンサンブル学習は、そんなバイアスとバリアンスを上手く調整する手法群です。
上手くバイアスとバリアンスのバランスを取ることが大事(早口言葉みたい笑)!
アンサンブル学習の種類
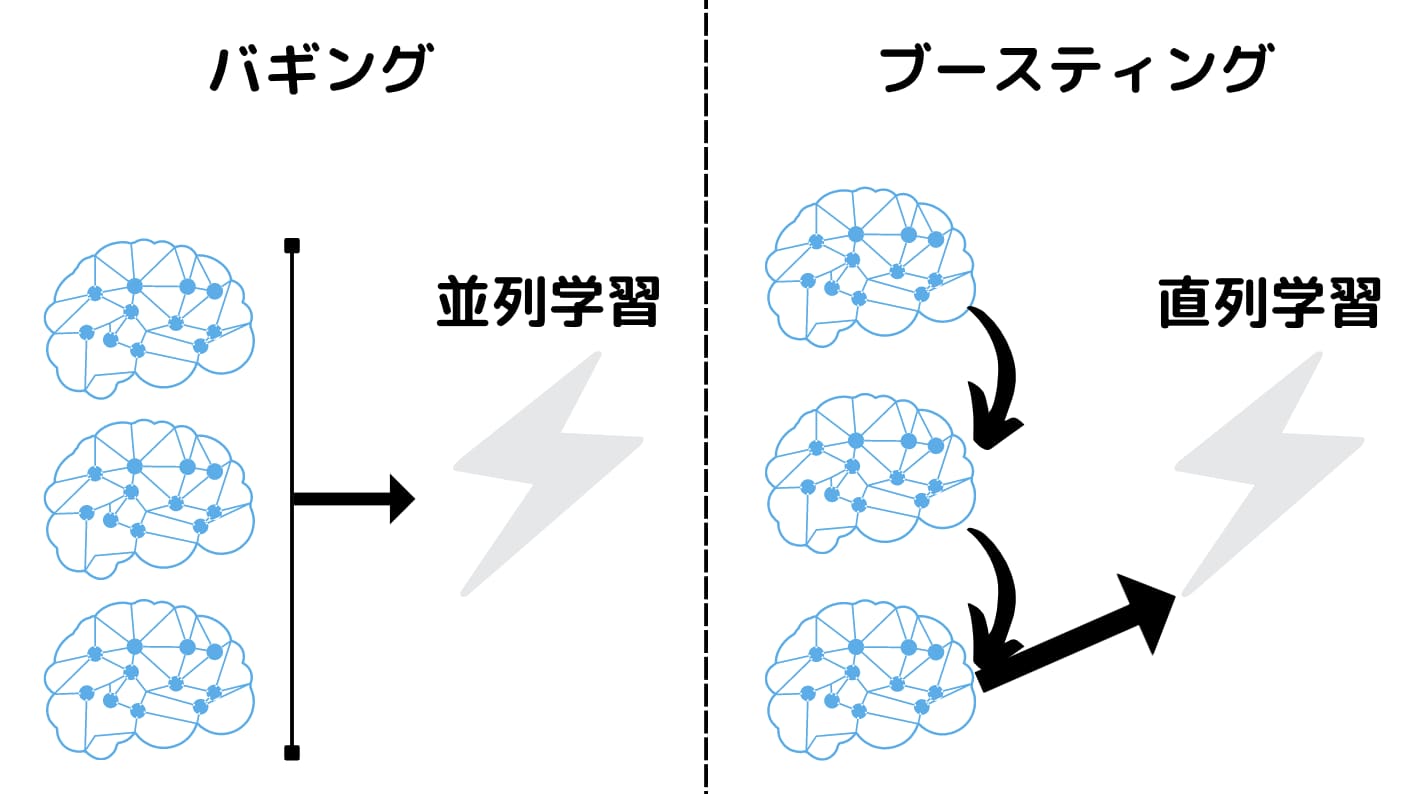
さて、アンサンブル学習には大きく分けて3つのタイプ「バギング」「ブースティング」「スタッキング」があります。
それぞれの手法について見ていきましょう!
バギング
バギングは、並列的に弱学習器を用いてそれぞれのモデルの総合的な結果を用いるという手法です。
バギングでは、バリアンスをおさえることが可能です。
バギングと決定木を組み合わせたランダムフォレストは以下のようなイメージ
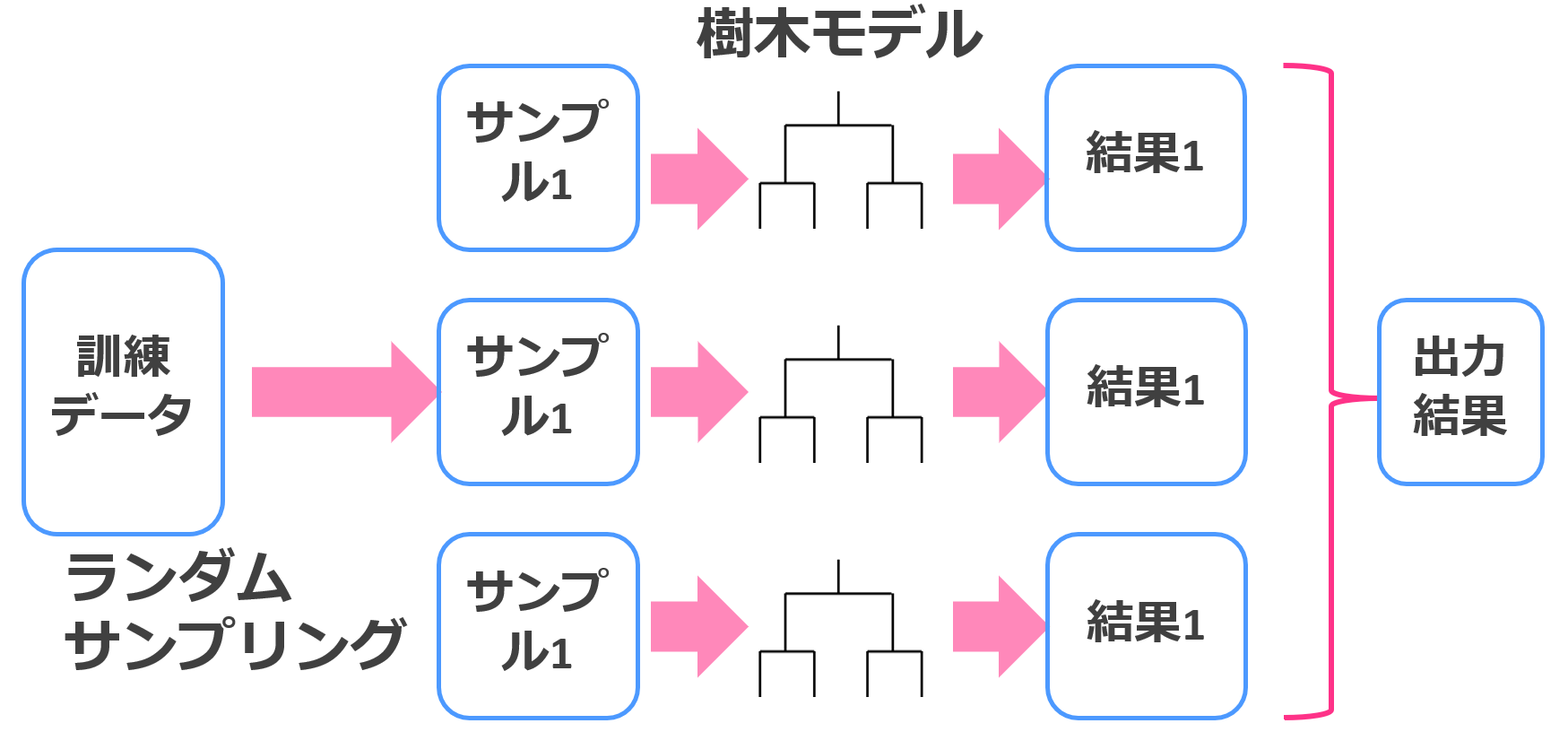
訓練データに対していくつも決定木モデルを作成し、それぞれの結果を集約して最終結果を出力します。
回帰だったら平均値、分類だったら多数決。
ランダムフォレストは非常に簡単に実装できる手法であり、それなりに高い精度が見込めるのでオススメです!
より詳しく知りたい場合、「Bagging」を発表した論文を見てみるとよいでしょう!
Bagging Predictors is a method for generating multiple versions of a predictor and using these to get an aggregated predictor. The aggregation averages over the versions when predicting a numerical outcome and does a plurality vote when predicting a class. The multiple versions are formed by making boostrap replicates of the learining set and using these as new learning sets.
(引用元:Google-”Bagging Predictors”)
ブースティング
バギングは並列でしたが、ブースティングは直列的に弱学習器を用いていきます。
最初の弱学習器で上手く推定できなかった部分を推定するために重みを付けて次の弱学習器で学習を行います。
最終的には、精度の高いモデルに重みを付けて最終的なモデルを作成します。
ブースティングでは、バイアスを低くすることが可能です。
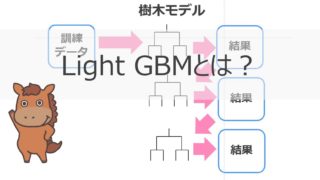
決定木とブースティングを組み合わせた手法がXGboostやLightGBMであり、非常に高い精度をたたき出します。
一般的にブースティングの方がバギングより高い精度が見込めますが、学習に時間がかかります。
より詳しく知りたい場合、「Boosting」に関する論文を見てみると良いでしょう!
Boosting is a general method for improving the accuracy of any given learning algorithm. This shoer papaer introduces the boosting algorithm AdaBoost, and explains the underlying theory of boosting, including an explanation of why boosting often does not suffer from overfitting. Some examples of recent applications of boosting are also described.
(引用元:Google-“A Belief Introduction to Boosting”)
スタッキング
スタッキングは、Kaggle上位者がよく使うテクニックであり、新たな特徴量を作る方法でもあります。
バギングやブースティングのように確立された手法に取り入れられている方法ではなく、高度な方法になります。
僕自身普段スタッキングは使わないのですが、簡単に説明します。
Step1:いくつかのFold(グループ)にデータを分けて、それぞれを各モデルで予測する(いわゆるクロスバリデーションを色んなモデルでやる)
Step2:それぞれの予測値を新たな特徴量とする
Step3:何回か繰り返して最終アウトプット算出
ある意味、新たな特徴量を作るコトでもあり時間はかかりますが精度向上が見込める可能性は高いです。
より詳しく知りたい場合は、こちらの「Stacked Generalization」を見てみるとよいでしょう!
This paper introduces stacked generalization, a scheme for minimizing the generalization error rate of one or more generalizers. Stacked generalization works by deducing the biases of the generalizer(s) with respect to a provided learining set.
(引用元:Google-“Stacked Generalization”)
アンサンブル学習の注意点

アンサンブル学習を行う上での注意点を最後に挙げておきます。
何でもかんでもアンサンブル学習すれば精度が上がるわけではない
当たり前ですが、なんでもかんでもアンサンブル学習をすれば精度が上がるわけではありません。
基本的には、既に確立されているXgboostやランダムフォレストなどの手法を使えるようになっておけばよいです。
Kaggleでは、複雑なアンサンブル学習を行い多数のモデル構築から最終結果を算出することもありますが、全てXgboostを使っているわけではなくk近傍法などの単独の推定精度は低いモデルを投入している例もあります。
基本的には、アプローチが違う手法をアンサンブル学習した方が良く、決定木モデル(XgboostやLightgbmやランダムフォレスト)と深層学習(CNN)などを組み合わせるとよいと言われています。
学習に時間がかかる
複雑なアンサンブル学習は実務ではよっぽどのことがない限り行いません。
Kaggleでは精度を少しでも上げることが目的なので、多数のモデルでアンサンブル学習を行いますが実務では精度を上げる労力とそこから得られるビジネスインパクトを天秤にかけた時にやらないことが多いです。
また、精度を上げる上ではアンサンブル学習にこだわるよりも新たな特徴量を作り出した方が良い可能性が高いです。
実務での複雑なアンサンブル学習はコストパフォーマンスの観点からやめておいたほうが良いです。

バリアンスとバイアスのバランスに注意
当たり前ですが、いくらXgboostなどを使ったとしてもデータセットを何も考えず使っていると過学習が起きる可能性があります。
交差検証法(クロスバリデーション)などを行い過学習しないように注意しましょう!
アンサンブル学習手法をPythonで実装してみよう!

それでは最後にアンサンブル学習の手法をPythonで実装してみましょうー!
ここではアンサンブル学習手法の中でも非常に強力なLightGBMを実装していきたいと思います。
国産データコンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータを題材にしていきます。
まず![]() Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
このデータをローカルのどこかのフォルダに格納し、LightGBMでの分析に移っていきましょう!
コードは以下になります。
globでデータフレームを結合させて、各種カラムのデータを一部前処理しています。
その上でLight gbmを以下の部分で実装しています。
trains = lgb.Dataset(train_x, train_y)
valids = lgb.Dataset(val_x, val_y)
params = {
"objective": "regression",
"metrics": "mae"
}
model = lgb.train(params, trains, valid_sets=valids, num_boost_round=1000, early_stopping_rounds=100)これだけで強力な機械学習手法であるLightGBMを実装することが出来るんです!
このタスクでは評価指標がMAE(平均絶対誤差)であり、結果は
0.0764となりました!
以下の記事で詳しく解説していますのでぜひチェックしてみてください!
アンサンブル学習 まとめ
本記事では、アンサンブル学習について見てきました。
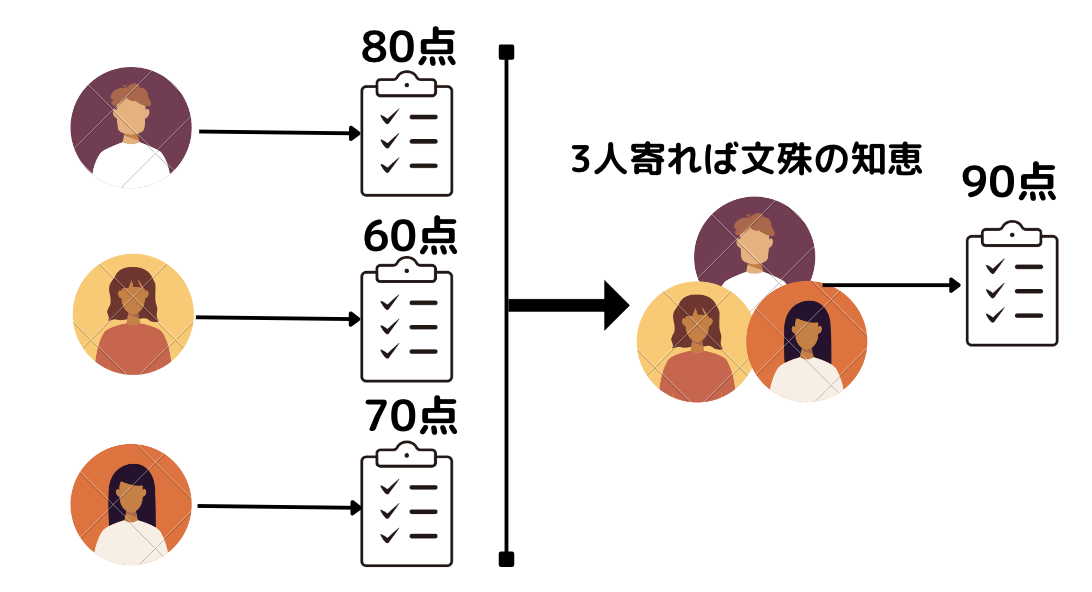
アンサンブル学習とは、いわゆる三人寄れば文殊の知恵的な手法です。
ランダムフォレストやXGboostやLightGBMは非常に高い精度を出力してくれるので良く使います。
LightGBMを使ったデータ分析については以下のUdemyの講座で詳しく解説していますのでこちらも参考にしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「ZEJ2UK7YVZFV」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編では体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ2000円以下になる講師クーポンを発行いたします!
是非アンサンブル学習を使ってみましょう!
また、当メディアではデータサイエンティストになるための分野を体系的に学ぶスクール「スタアカ(スタビジアカデミー)」を運営して、機械学習やディープラーニングのコースもがっつり用意しているので、是非チェックしてみて下さい!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
もっと深く理論について学びたい方は以下のはじめてのパターン認識が読むことをオススメします!

Kaggleで用いられる上位者テクニックのアンサンブル学習について知りたい方は以下の書籍を読んでみることをオススメします!

以下の記事で他の機械学習手法についてまとめているのでこちらも合わせてチェックしてみてくださいね!

機械学習、データサイエンス、Pythonについて学びたい方は以下の勉強ロードマップをまとめているので是非見てみてください!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















