
パターン認識の事例やAIや機械学習との関連性をわかりやすく解説!


こんにちは!スタビジ編集部です!
パターン認識は、得られたデータから文字通り「パターンを認識する」技術です。
今回はパターン認識について詳しく解説し、代表的な手法のPythonでの実装例も紹介していきます!
・パターン認識とはなにか
・事例の紹介
・代表的な手法
・AIや機械学習とパターン認識の関連性
・Pythonでの文字認識実装
パターン認識については以下の動画でも解説していますので合わせてチェックしてみてください!
目次
パターン認識とは?

まずはじめに、「パターン認識とはそもそも何なのか?」について解説していきます!
パターン認識とはずばり、与えられたデータの中から規則性や特徴を抽出し、それを利用して新たなデータを分類したり予測したりする技術です!
例えば、手書き文字認識の場合、大量の手書き文字のデータを収集し、その特徴(線の太さや角度、曲がり具合など)を抽出します。
次に、これらの特徴を基にモデルを構築し、新しい手書き文字が入力された際にそれを認識・分類することができます!
1.データ収集
分析対象のデータを収集します。これは、画像データ、音声データ、テキストデータなど、さまざまな形式のデータが対象となります。例えば画像認識のプロジェクトでは、大量の画像データが必要になります。音声認識では、録音された音声データが必要です。データ収集は、インターネットからのデータスクレイピングやセンサーデータの取得、既存のデータベースの利用など、さまざまな方法で行われます。
2.前処理
収集したデータはそのままでは分析に適さない場合が多いため、前処理が必要です。前処理の目的は、データの特徴を捉えやすくすることです。例えば画像データの場合、ノイズの除去やサイズ変更、色調補正などの処理が行われます。音声データの場合、無音部分の除去やノイズフィルタリングが行われます。テキストデータの場合、トークン化(単語、句読点、記号などに分割)やストップワード(特徴を捉えるのに不要な内容を持たないワード)の除去などが行われます。前処理はデータの質を高め、後の分析の精度を向上させるために非常に重要です。
3.特徴抽出
前処理されたデータから、必要な特徴を抽出するステップです。特徴抽出は、データの次元を縮小し、重要な情報を効率よく取り出すプロセスです。例えば画像データの場合、エッジ検出やコーナー検出などの方法を用いて、画像の重要な部分を特定します。特徴抽出によってデータはより扱いやすくなり、パターン認識の精度が向上します。
4.データの識別・分類
抽出した特徴を基に、機械学習アルゴリズムを用いてモデルを構築します。このモデルは、トレーニングデータを基に学習し、新しいデータに対してパターンを識別・分類するために使用されます。例えば画像分類のタスクでは、畳み込みニューラルネットワーク(CNN)を使用して、画像を異なるカテゴリに分類します。音声認識では、リカレントニューラルネットワーク(RNN)を使用して、音声をテキストに変換します。モデルの精度は、トレーニングデータの質や量、選択したアルゴリズムの性能に大きく依存します。


パターン認識の事例
パターン認識は、さまざまな分野で幅広く応用されています。
先程の章でも少し例を出してご紹介しましたが、ここでも具体的な事例を紹介します!
画像認識
イメージがしやすく利用事例も多い種類の1つとして、画像認識があります!
画像認識は、パターン認識の代表的な応用分野の一つです。
例えば、手書き文字認識では、手書き文字の画像をデジタル文字に変換します。
郵便物の宛名認識システムでは、手書きの宛名を認識してデータベースに登録します。
また、顔認識技術は、セキュリティシステムやスマートフォンのロック解除機能などで広く利用されています。
これらのシステムは、画像から特徴を抽出し、データベースに登録されたパターンと照合することで、対象を識別します。
音声認識
音声認識は、音声データをテキストに変換する技術です。
これにより、音声アシスタント、音声入力システム、自動翻訳アプリケーションなどが実現されています。
音声認識システムは、取得した音声の波形から特徴を抽出し、それを基に音素(音の最小単位)を識別します。
その後、音素の連なりを解析して単語や文を特定します。
これらのシステムは、パターン認識技術を駆使して音声データのパターンを学習しています!
医療診断
医療分野でもパターン認識技術は重要な役割を果たしています。
例えば、放射線画像やMRI画像の解析によって、がんやその他の疾患を早期に発見することができます。
これにより、診断精度が向上し、患者の治療計画を最適化することが可能になります。
さらに、遺伝子データの解析においてもパターン認識技術が活用され、個別化医療の実現に寄与しています。
これらのシステムは、膨大な医療データから有用なパターンを抽出し、診断や治療の意思決定を支援します!
セキュリティの分野
セキュリティ分野では、異常検知や不正アクセスの検出にパターン認識技術が活用されています。
例えば、ネットワークトラフィックの解析により、通常のパターンから逸脱する異常な動きを検知します!
これにより、サイバー攻撃やデータ漏洩のリスクを早期に発し、対策を講じることができます。
また、監視カメラの映像解析により、異常行動の検出や犯罪の予防にもパターン認識技術が役立っています!
パターン認識で用いられる代表的な手法

パターン認識の手法は多岐にわたりますが、ここでは特に代表的なものをいくつか紹介します!
それぞれの手法がどのように機能し、どのように活用されているのかを見ていきましょう!
k-近傍法(k-NN)
k-近傍法(k-NN)は、シンプルでありながら非常に効果的な分類アルゴリズムです。
k-NNは、新しいデータポイントの分類を、そのデータポイントの最も近いk個の隣接データポイント(近傍)に基づいて行います。
例えば、ある花がどの種に属するかを分類する場合、その花に最も近いk個の花の種を調べ、最も多い種に分類します。
具体例として、手書き数字認識を考えます。手書き数字のデータセットがあり、新しい手書き数字を分類する必要があるとします。k-NNを用いると、新しい手書き数字の画像を既知の手書き数字のデータセットに対して比較し、最も近いk個の数字のラベルを取得します。例えば、k=3の場合、新しい手書き数字が3つの近傍の数字ラベルの中で最も頻繁に現れるラベルに分類されます。

サポートベクターマシン(SVM)
サポートベクターマシン(SVM)は、高次元空間におけるデータポイントを分類するための強力なアルゴリズムです。
SVMではデータを最適に分離する境界線を見つけます!
その際、クラス間の最大マージンを持つ境界線を求め、新たなデータがその境界線に対してどちら側に寄っているかでデータを分けていく流れです!
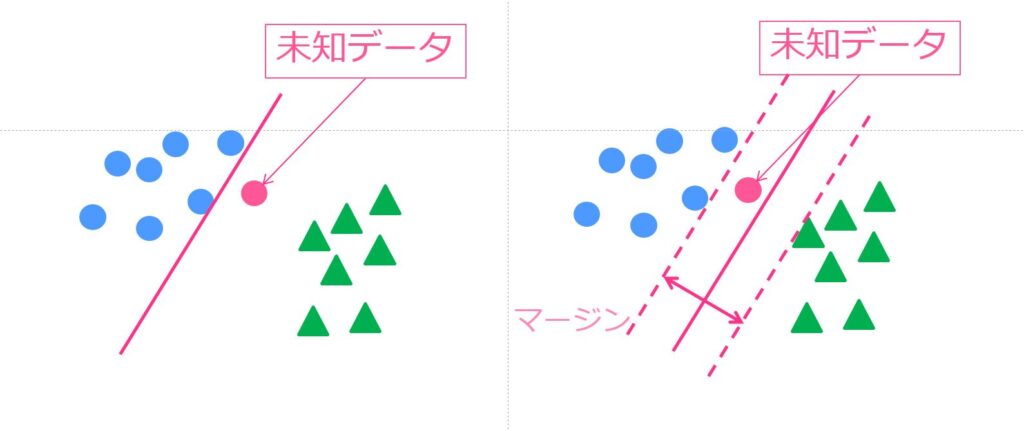
具体例として、スパムメールの分類を考えます。SVMを用いて、スパムメールと正常メールを分ける境界線を算出します。特徴ベクトル(メールの内容や送信者情報など)を基に、SVMは最大のマージンを持つ境界線を見つけ、新しいメールがスパムかどうかを分類します!

主成分分析
主成分分析(PCA)は、高次元データの次元削減に使用される手法です。
PCAは、データの分散を最大化する方向に新しい軸(主成分)を見つけ出し、次元を圧縮します。
これにより、データの構造を保持しつつ、次元を減らして解析を行うことを可能とします!
具体例として、顔認識を考えます。大量の顔画像データをPCAを用いて次元削減し、各顔画像を少数の主成分に変換します。この主成分を基に、顔の特徴を捉え、新しい顔画像の識別を行います。PCAを用いることで、計算コストを削減しつつ、高い精度で顔認識を行うことができます!

ニューラルネットワーク
ニューラルネットワークは、生物の脳の構造を模倣したアルゴリズムで、複雑なパターン認識問題に対して非常に効果的です。
ニューラルネットワークは、多層の「ニューロン」と呼ばれる単位で構成され、各ニューロンが他のニューロンと重み付けされた接続を持ちます。
入力データがネットワークに渡されると、各ニューロンはデータを処理し、出力を生成します。
具体例として、画像認識を考えます。畳み込みニューラルネットワーク(CNN)を使用して、画像から特徴を抽出し物体を認識します。例えば、猫の画像を入力すると、CNNは画像のピクセル情報を解析し、猫の特徴(耳の形、目の位置、毛のパターンなど)を学習して、画像が猫であることを認識します。

AIや機械学習との関連性

パターン認識とAI(人工知能)や機械学習は密接に関連しています。
パターン認識と機械学習の互いの技術を掛け合わせることによって、AIの進歩に貢献してきた側面があります!
本章では、パターン認識とAI、機械学習の関連性について詳しく解説します。
パターン認識とAI/機械学習
機械学習は、パターン認識における学習プロセスを支える主要な技術です。
教師あり学習、教師なし学習、強化学習など、さまざまなアプローチがあり、それぞれが異なる方法でパターンを学習します。
パターン認識とAIおよび機械学習の関係は相互補完的であり、これらの技術が組み合わさることで、より高度なシステムが構築されます!
例えば、AIベースの医療診断システムでは、パターン認識技術を用いて医療画像を分析し、異常を検出します。
この過程で機械学習アルゴリズムが用いられ、過去の診断データから学習して診断精度を向上させます。
また、レコメンドシステムでは、ユーザーの行動パターンを認識し、適切な商品やコンテンツを推薦します。
ここでも機械学習技術を活用してユーザーの嗜好を学習し、精度の高いレコメンドを行います。
このように、パターン認識はAIと機械学習の基盤となる技術であり、これらの技術が進化することで、ますます高度な応用が可能となります!
パターン認識のこれから
パターン認識、AI、機械学習の関連性は今後ますます強まっていくものと見られ、技術は進化し続けるでしょう!
自動運転車、スマートシティ、医療診断システムなど、さまざまな分野での応用が期待されています。
自動運転車では、道路状況や他の車両、歩行者の動きをリアルタイムで認識し、安全に走行するために高度なパターン認識技術が求められます!
スマートシティでは、都市全体のデータを解析し、交通渋滞の緩和やエネルギーの効率的な使用を実現するために、パターン認識技術が活用されます!
このように、パターン認識はAIや機械学習の中核的な技術として、未来のイノベーションを支える重要な役割を果たしています!
Pythonでパターン認識を実装してみよう

パターン認識の概要について掴んだところで、次は実際の実装例を簡単に見ていきましょう!
Pythonは、豊富なライブラリとシンプルな構文で、パターン認識を行うのに非常に適した言語となっています。
ここでは、機械学習ライブラリであるScikit-learnを使用して、具体的なパターン認識手法を実装します。

以下の流れで進めていきます!
1. データの準備
2. データの分割と標準化
3. k-NNモデルの構築
4. テストデータを用いた予測と結果の確認
1. データの準備(データ収集)
今回は、手書き数字認識を、k-近傍法を使って実装していきます!
データセットにはScikit-learnの提供する手書き数字データセットを使用します。
以下はデータセットの中身のイメージです!

以下で、ライブラリのインストールとデータの読み込みを行います!
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# データの読み込み
digits = load_digits()
X = digits.data
y = digits.target2. データの分割と標準化(前処理)
データをトレーニングデータとテストデータに分割し、使いやすい形に標準化も行っていきます!
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# データの標準化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)3. 機械学習モデルの構築
ここではk-NNモデルを構築します!
このフェーズ自体はライブラリから持って来るだけなので非常にシンプルです!
# k-NNモデルの構築
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(X_train, y_train)4. テストデータを用いた予測
最後に、テストデータを用いて実際の手書き数字の認識を行ってみます!
精度はどのくらいになるでしょうか!
# 予測と評価
y_pred = knn.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
print(classification_report(y_test, y_pred))
print(confusion_matrix(y_test, y_pred))
# 結果の可視化
fig, axes = plt.subplots(1, 4, figsize=(10, 3))
for ax, image, true_label, predicted_label in zip(axes, digits.images[:4], y_test[:4], y_pred[:4]):
ax.set_axis_off()
plt.show()
結果は以下のようになりました!
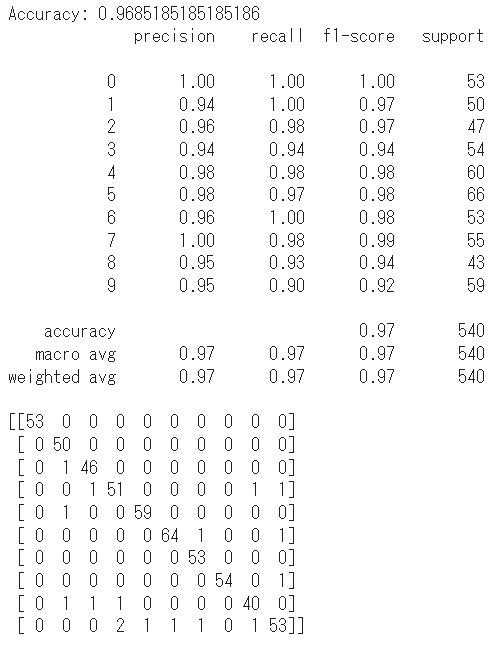
Accuracyは95%以上と、かなり高い精度を示していますね!
その他のprecisionやrecall、f1scoreなども上記の表から確認できます!

まとめ
ここまでご覧いただきありがとうございました!
本記事では、パターン認識の基本概念や事例、AIや機械学習との関連性、さらにはPythonを用いたパターン認識の実装まで幅広く解説しました!
パターン認識は、さまざまな分野で重要な役割を果たしています!
データから規則性やパターンを抽出し、その情報を利用して意思決定や予測を行うことを可能にします!
ぜひ一度、気になるパターン認識の手法で実装まで行ってみてください!
今回分析に用いたPythonについて勉強したい方は以下の記事を参考にしてみてください!

さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















