
SVM(サポートベクターマシン)とは?特徴とRによる実装!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
機械学習手法の中でも汎化能力が高いとされ使われることの多いSVM(サポートベクターマシン)
この記事では、そんなSVM(サポートベクターマシン)について見ていきます!
以下の動画でも簡単に解説していますよ!
他の手法についてはこちらも合わせてチェック!


SVM(サポートベクターマシン)とは

SVMとは、機械学習の中でも有名な手法の1つ。
SVMの特徴は、「マージン最大化」と「カーネルトリック」。
順番に見ていきましょう!
マージン最大化
SVMは「マージン最大化」というアイデアで分類データにおいて非常に高い精度をほこります。
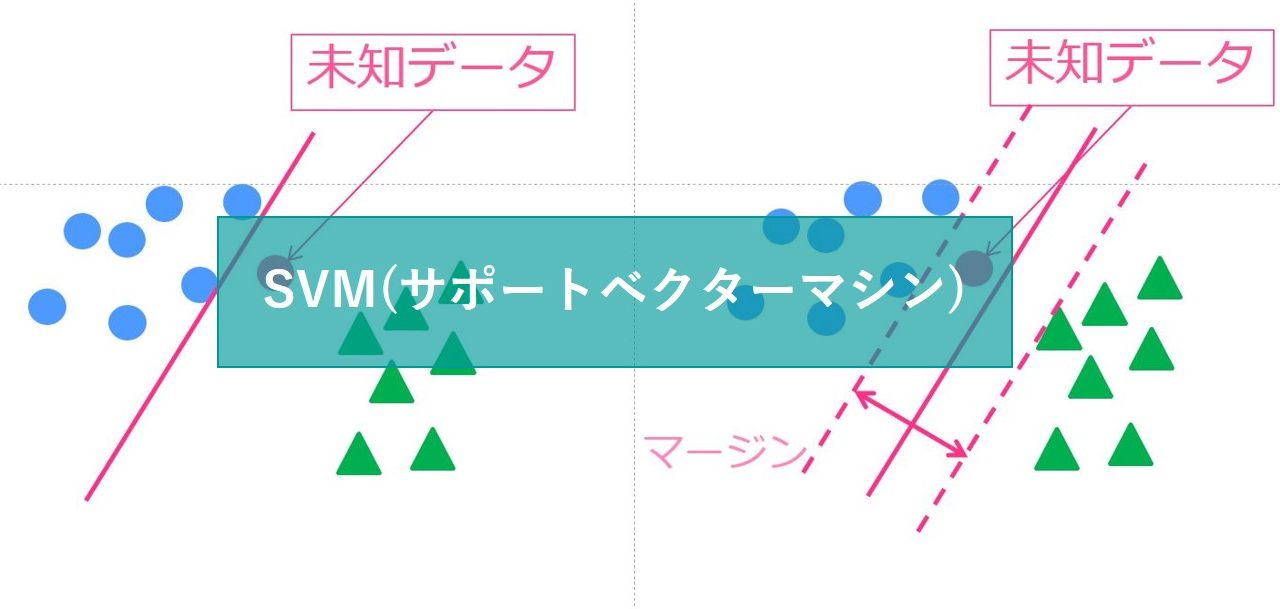
以下の図を見てみてください。
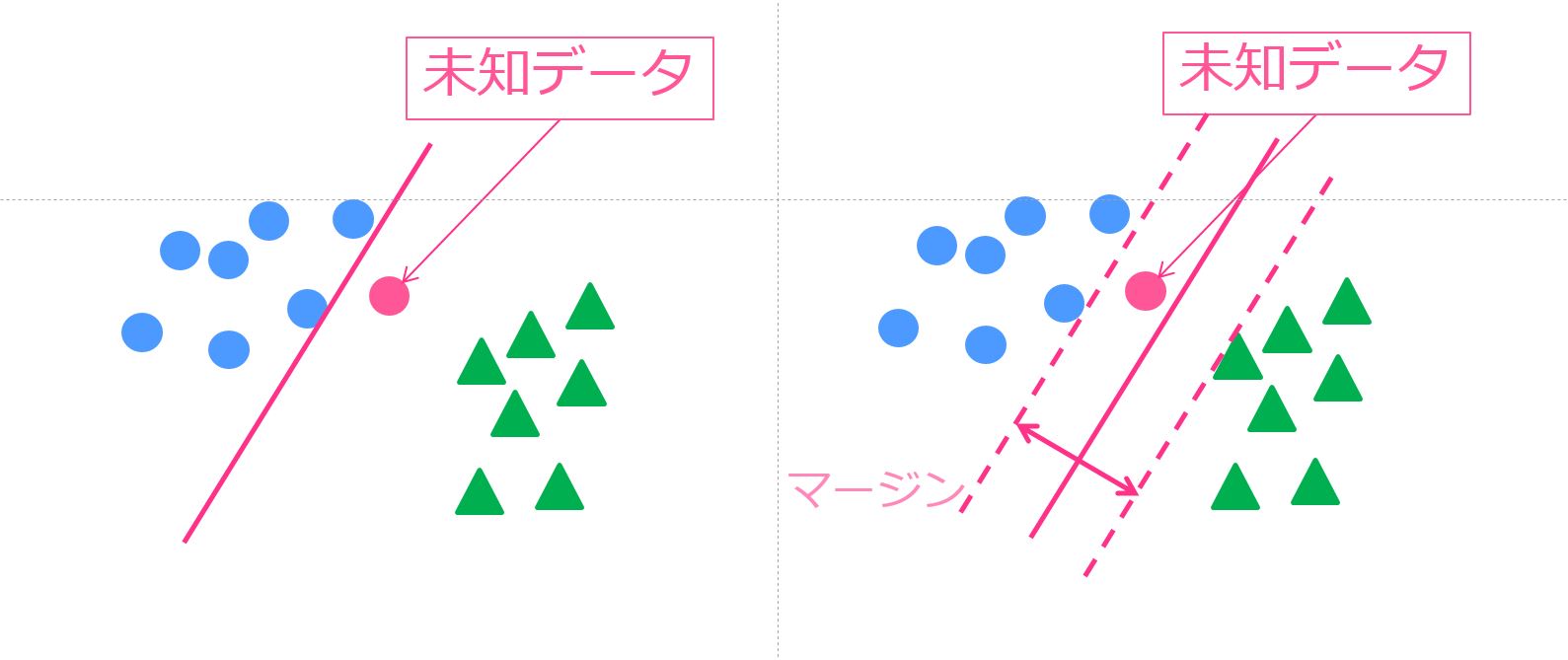
〇と△で分類したいのですが左のような識別境界線を引いてしまうと、新たな未知の〇データに関して上手く分類することができません。
なるべく、右の図のように〇と△の中間地点に識別境界線を引くべきです。
そして、この場合見なくちゃいけないのは境界に近い〇と△のデータ。
これら境界に近いデータのことをサポートベクトルと呼びます。
これらのサポートベクトルのマージンが最大になるように境界線を引く方法が「マージン最大化」であり、SVMの肝になる手法です。
マージン最大化については視覚的に分かりやすいので大丈夫だと思います。
カーネルトリック
カーネルトリックは少々難易度高です。
正直僕自身も完璧に理解しているとは言い難い・・笑
先ほどの例では、線形直線を引いて分類を行いました。
しかしデータの構造的に線形直線で分類出来ることばかりではありません。
データが真ん中に内側と外側に集まっている以下の図のようなパターンもあります。
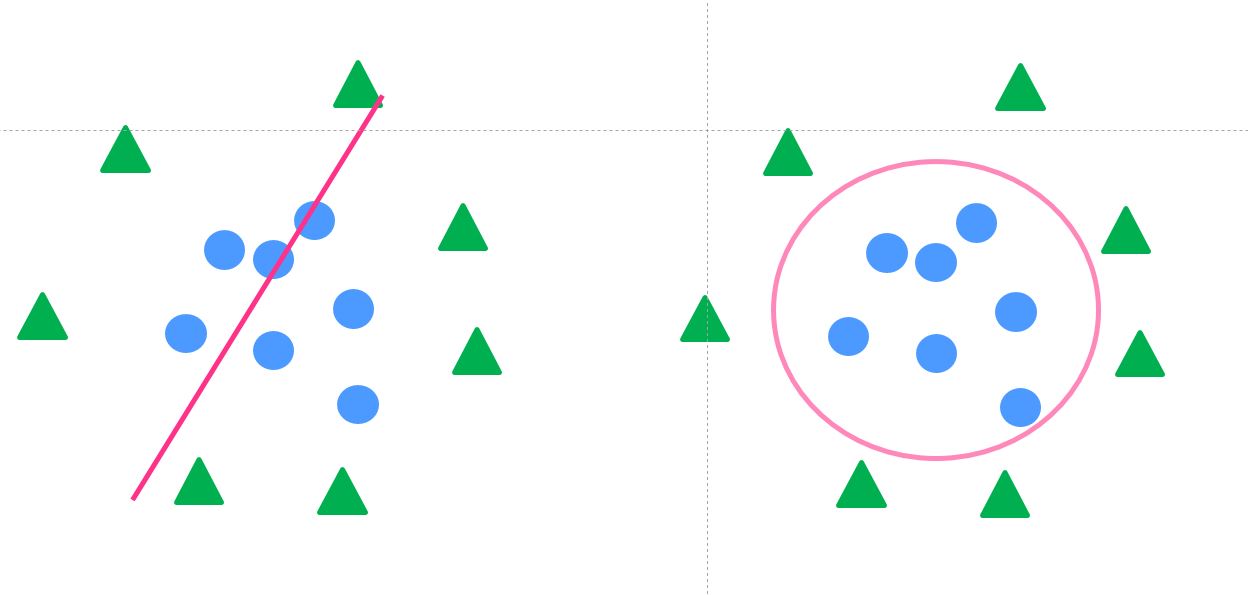
そんな時、左図のように直線では分類できません。
右図のような非線形の識別境界線が必要になってくるのです。
非線形な識別境界線を引くには、データを非線形変換する必要があります。
データ構造が複雑になればなるほど、非線形変換は大変です。
そこで登場するのがカーネルトリック。
カーネルトリックでは、そのような複雑な非線形変換をせずとも非線形識別境界線を引くことが可能なのです。
SVMのメリット

SVMについてなんとなく理解いただけたでしょうか?
さて、そんなSVMですが数ある機械学習手法と比べた時にどんなメリットがあるのでしょうか?
SVMの特徴である「マージン最大化」は、学習データを完璧に分類できれば良い!という考え方とは少し違います。
実は、ある程度分類ができなくても良いというマージンをソフトマージン、なるべく完璧に分類するようなマージンをハードマージンと呼んでいます。
SVMの場合は、ソフト・ハードあれど、マージン最大化を行うことが目的であるので、無理やり全ての学習データを分類するようなモデルは作りません。
一方、他の機械学習手法は学習データに対して過度にフィッティングし完璧に分類しようとします。
そうすると起きるのが過学習と呼ばれる現象。過適合などとも言ったりしますね。
過学習とは、学習モデルにフィッテングし過ぎて、あらたなデータに対する予測精度が悪化してしまうこと。
これは、機械学習手法で結構起こり得る問題なんです。
SVMは、「マージン最大化」というアルゴリズムから過学習が起こりにくくなっているんです。
SVMをRで実装してみよう!

それでは、最後にSVMをRで実装してみます。
有名なタイタニックのデータを用います。Kaggleの公式サイトからデータをダウンロードできます。
まず、データのクレンジングを行い、欠損値は削除、不要と考えられる項目は削除しました。
項目8つ
Survived:生死 pclass:客室のクラス sex:性別 age:年齢 sibsp:兄弟・配偶者の数 parch:親・子供の数 fare:乗船料金 embarked:乗船した港
サンプル数714
この時、生死を目的変数としそれ以外を説明変数とします。
サンプル数714のうちランダムに400個のデータを取り出し学習データとし、残りの314を予測データとします。
学習データで予測モデルを作り、予測データにあてはめ真値と予測値の判別率を精度として比較します。
シミュレーション回数は1000回とし、上記の手順を1000回繰り返し、結果を平均したものを最終アウトプットとします。そのため、結果はばらつきがなく確からしい結果になっているはずです。
SVM(サポートベクターマシン)をランダムフォレスト、ナイーブベイズ、ニューラルネットワーク、XGboost、k近傍法の5手法と比較します!
基本的に引数は全部デフォルトで!果たして結果はどうなるでしょうか!
kernlabというパッケージに入っているksvmという関数を用いて解析を行っていきます。
##SVM##
svm<-ksvm(Survived~.,train.data)
test.data.svm<-cbind(test.data,”predict”=predict(svm,test.data))
result[i,2]<-sum(test.data.svm$predict==test.data.svm$Survived)/nrow(test.data.svm)
データ加工は描画でいくつかコードを書いていますが、実際にSVMを行っているのはこの数行!
Survived~.はSurvivedを目的変数としてそれ以外を説明変数にするよーということです。
結果は以下のようになりました!
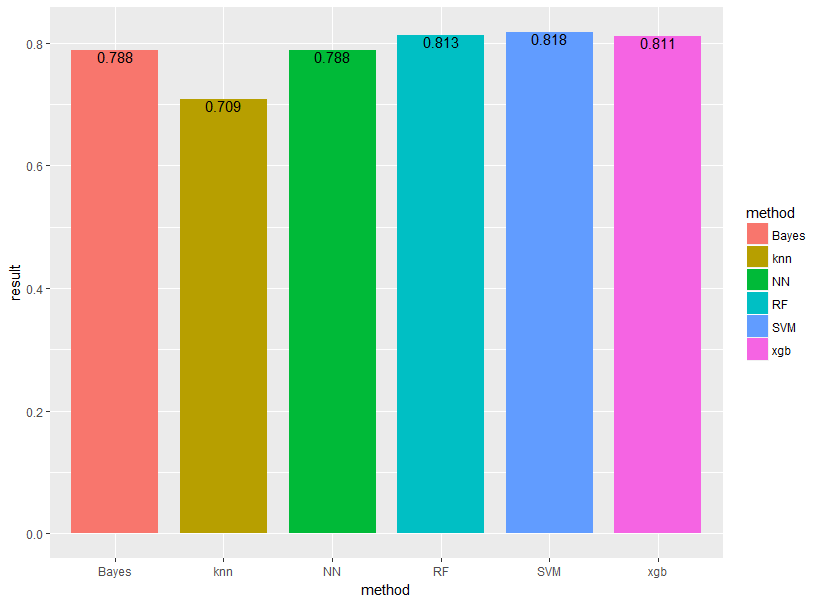 それぞれBayes(ナイーブベイズ)、knn(k近傍法)、NN(ニューラルネットワーク)、RF(ランダムフォレスト)、SVM(サポートベクターマシン)、xgb(XGboost)と表示しています。
それぞれBayes(ナイーブベイズ)、knn(k近傍法)、NN(ニューラルネットワーク)、RF(ランダムフォレスト)、SVM(サポートベクターマシン)、xgb(XGboost)と表示しています。
見事SVMの勝利!やはりランダムフォレスト・SVM・XGboostあたりが強いですね!
SVMが若干ランダムフォレストよりも精度が良いという結果になっています。
ちなみに計算速度はランダムフォレストの方が速く、SVMは若干遅めです。
SVM(サポートベクターマシン) まとめ
本記事では、SVMの特徴と実装方法について見てきました。
最後にまとめておきましょう!
・マージン最大化により過学習しにくい
・カーネルトリックにより非線形データでも計算負荷を抑えられている
・実装が簡単
SVMは非常に優秀な手法ですが、実装が簡単なので是非試してみてください!
SVMに関してもっと詳しく知りたいかたは以下の書籍を参考にしてみてください!


ちなみにランダムフォレストをはじめとした機械学習に関して深く勉強したい方は以下の記事を見てみてください!

データサイエンス全般について知りたい方は以下の記事をご覧ください。

また、今回はRを使ってきましたが機械学習の文脈ではPythonの方がよく使われていたりします。Pythonを勉強したい方は以下をチェックしてみてください!

またこれらの知識を総合的に学べる「スタビジアカデミー(スタアカ)」というスクールを当メディアで運営しておりますので興味のある方は是非チェックしてみてください!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















