ナイーブベイズ(単純ベイズ)とは?概要とRでの実装!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、機械学習手法の中でも比較的単純なアルゴリズムで高い効果が見込める「ナイーブベイズ」について見ていきましょう!
ナイーブベイズはベイズ統計学の概念を用いており、様々な分野へ応用されています。
ベイズ統計学を研究している人を巷ではベイジアンと呼ぶのですが、僕自身大学院時代はベイジアンでした。
ナイーブベイズとは?

ナイーブベイズはベイズの定理に基づいた機械学習手法です。
ベイズの定理はベイズ統計学の基本中の基本。大事な式なので覚えておきましょう。
$$ p(A|B)=\frac{p(B|A)p(A)}{p(B)} $$
これは以下の条件付き確率と同時確率の関係から導出できます。
$$ p(A,B)=p(B|A)p(A)=p(A|B)p(B) $$
この関係式を変形するとベイズの定理が導出されることが分かるでしょう。
ベイズの定理では基本的に確率を元に考えていました。
しかし、ベイズの枠組みはそれだけではおさまりません。
ベイズ推定ではベイズの定理における確率を確率分布へと拡張させ考えていきます。
ベイズ推定に関しては事前分布と事後分布、そして尤度という考え方が非常に重要です。
事前分布は前から持っている情報。
尤度は手に入れた情報。
事後分布は前情報と手に入れた情報を合わせた情報というイメージを持っていれば良いでしょう。
$$ p(A|B){\propto}p(B|A)p(A)=事後分布{\propto}尤度×事前分布 $$
ベイズ推定を用いた判別手法が「ナイーブベイズ」です。
実はベイズ推定の理論自体は古くからあったのですが、伝統的な統計学との対立とマシーンパワーの問題で現代まで流行りませんでした。
ベイズ統計学に関しては以下の記事をご覧ください!

ナイーブベイズが応用される場面

ナイーブベイズが用いられる場面として最も有名なのはスパムメールの判別ですね。
スパムメールの判別では、文章に含まれる単語に対して迷惑メールである確率を算出しベイズ推定を使って迷惑メールであるか否かを推定します。
$$ p(迷惑メール|ダウンロード)=\frac{p(ダウンロード|迷惑メール)p(迷惑メール)}{p(ダウンロード)} $$
ダウンロードというワードが入っていた場合に迷惑メールであるか判別するためには、「迷惑メールの中にダウンロードが入っている確率」と「迷惑メールの確率」と「メールにダウンロードが入っている確率」が分かれば算出することが可能です。
これらを手元の教師データから判別していくのがナイーブベイズによるスパムメールの判別アルゴリズムになります。
なんとなくイメージが湧きましたでしょうか?
ナイーブベイズをRで実装してみる

それではナイーブベイズを実際にRで実装してみます。
実装と言ってもパッケージを使ってしまうので非常に簡易的な実装になります。
有名なタイタニックのデータを用います。Kaggleの公式サイトからデータをダウンロードできます。
まず、データのクレンジングを行い、欠損値は削除、不要と考えられる項目は削除しました。
項目8つ
Survived:生死 pclass:客室のクラス sex:性別 age:年齢 sibsp:兄弟・配偶者の数 parch:親・子供の数 fare:乗船料金 embarked:乗船した港
サンプル数714
この時、生死を目的変数としそれ以外を説明変数とします。
サンプル数714のうちランダムに400個のデータを取り出し学習データとし、残りの314を予測データとします。
学習データで予測モデルを作り、予測データにあてはめ真値と予測値の判別率を精度として比較します。
シミュレーション回数は10回とし、上記の手順を10回繰り返し、結果を平均したものを最終アウトプットとします。シミュレーション回数をもっと増やせば精度の信頼性は上がります。
Bayes(ナイーブベイズ)をSVM(サポートベクターマシン)、RF(ランダムフォレスト)、NN(ニューラルネットワーク)、xgb(XGboost)、knn(k近傍法)の5手法と比較します!
基本的に引数は全部デフォルトで!果たして結果はどうなるでしょうか!
e1071というパッケージに入っているnaiveBayesという関数を用いて解析を行っていきます。
##ナイーブベイズ##
nb<-naiveBayes(Survived~.,train.data)
test.data.nb<-cbind(test.data,”predict”=predict(nb,test.data))
result[i,3]<-sum(test.data.nb$predict==test.data.nb$Survived)/nrow(test.data.nb)
データ加工は描画でいくつかコードを書いていますが、実際にナイーブベイズを行っているのはこの数行!
Survived~.はSurvivedを目的変数としてそれ以外を説明変数にするよーということです。
結果は以下のようになりました!
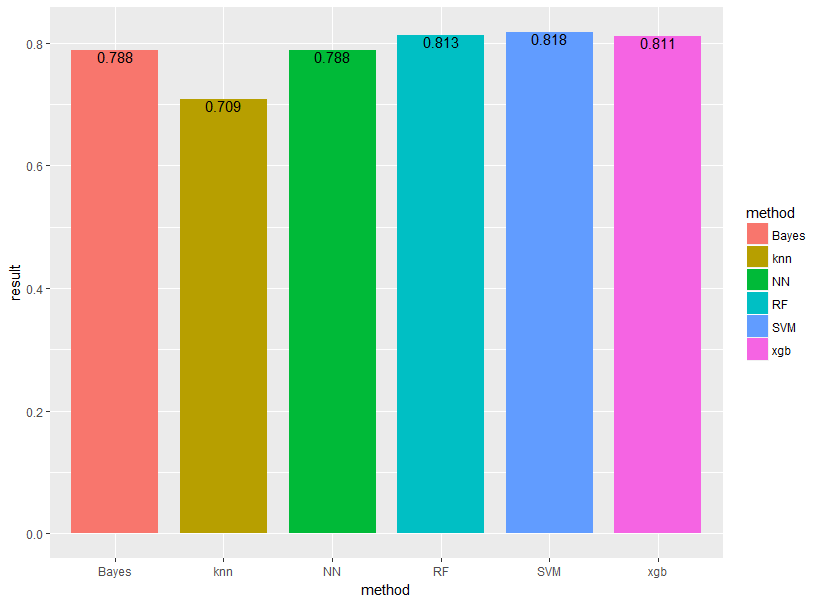
それぞれBayes(ナイーブベイズ)、knn(k近傍法)、NN(ニューラルネットワーク)、RF(ランダムフォレスト)、SVM(サポートベクターマシン)、xgb(XGboost)と表示しています。
やはりランダムフォレスト・SVM・XGboostあたりが強いですね!
今回はパラメータをいじらずデフォルト設定で行ったためグリッドサーチなどでチューニングを行えば、もっと良い精度が出るでしょう。
他の手法についても是非見てみてください!
ナイーブベイズ まとめ
ナイーブベイズは、アルゴリズム自体が単純でRやPythonでも簡単に実装できる優秀な手法です。
ナイーブベイズのポイントについて最後に簡単にまとめておきましょう!
・ベイズ統計学の理論を基にした手法である
・スパムメール判別に良く用いられる
・RやPythonでの実装が非常に簡単である
ベイズの識別規則について深く学びたい方は以下の書籍がオススメです!

機械学習やデータサイエンスや統計学の勉強法は以下の記事でまとめているのでチェックしてみてください!



機械学習やデータサイエンスについてより深く学びたい方は、当メディアが運営している「スタアカ(スタビジアカデミー)」を是非チェックしてみてください!
格安でデータサイエンスが一通り学べます!ご受講お待ちしております!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!