
AIモデルによる需要予測の事例と手法を紹介!Pythonで実装してみよう!


こんにちは!スタビジ編集部です!
今回は需要予測におけるAIモデルについてその活用方法や具体的な事例について紹介していきます。
記事の後半では、実際にPythonを使った需要予測のやり方についても紹介します!
・AIを用いた需要予測とは?
・AIモデルの種類と活用事例
・Pythonでの実装
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
目次
需要予測とは?AIモデルを用いるメリットは?

まず初めに、需要予測とは何なのか?について解説していきます!
需要予測とはその名の通り、誰にも定かではない将来の需要を予測するプロセスでありビジネスにおいて欠かせないものとなっています。
需要予測は、企業が製品やサービスを供給する量を最適化し、在庫を多く抱えすぎないように抑えつつ、需要に応じて生産や調達の量を調整する目的で利用されます。
製品の製造計画や在庫管理、サービス提供の最適化など、戦略的な意思決定を行う需要予測のプロセスは多岐にわたります。
昨今では、この需要予測にAIモデルが活用されるケースが見られます。

AIモデルを用いて需要予測を行うメリットは以下などがあります。
・精度向上:過去の大量のデータから学習を行い、パターンやトレンドを把握することが可能。また過去データだけでなく異なる変数や要因を組み合わせた予測を行うことによる精度向上も期待できる。
・ロスタイムがない:変化する市場の状況や消費者の行動に対してリアルタイムでデータ分析を行えるため、需要の急激な変化にも対応しやすい。
・カスタマイズ性:異なる業界やビジネス特性においてもモデルの調整により柔軟に適応し、適切な予測を効率的に行える
AIモデルの種類と選定

需要予測に用いられるAIモデルは様々あります。
異なるモデルにはそれぞれ、得意なデータやパターンがあり、ビジネスの特性によって最適なモデルは変化します。
本章では、代表的な3つのモデルである「ARIMAモデル」「LSTM」「Prophet」に焦点を当ててそれぞれの特性について見ていきましょう。
ARIMAモデル
ARIMA(AutoRegressive Integrated Moving Average)は、時系列データの予測に広く使用される統計的手法です。
時系列データの予測なので需要予測以外にも、様々な予測に活用されます!
(ex.ある地域の降水量)
ARIMAモデルでは以下の3つの要素が組み合わさっています。
・自己相関(AutoRegressive:AR)
・和分(Integrated:I)
・移動平均(Moving Average:MA)
詳しい説明はここでは割愛しますが、上記3つの要素が組み合わさっていることにより、データのトレンドや季節性を捉えることが可能です。
このモデルの特徴は、非定常(時系列によって平均値などのトレンド感が異なるなど)の特徴を持つ時系列データに対しても、差分を取り定常性を持つデータに変換させるところにあります。

これにより、モデルがデータのトレンドや季節性をより適切に捉えられるようになります。
季節性のあるデータにも対応できるARIMAモデルは、例えば特定の月や週ごとのパターンを考慮して予測を行えることが強みです。
・実装が比較的容易
PythonやR、Excelなどでパッケージを用いて使用できる
・解釈性
数学的に理解がしやすく、モデルの構造やパラメータについて把握した上でユーザーがモデルの調整を行える
・柔軟なモデルである
非線形や定常・非定常データ、季節データなど、様々な時系列データに対して適用できる
ARIMAモデルについては以下の記事をチェックしてみてください!

LSTM
LSTM(Long Short Term Memory)は、時系列データに対するニューラルネットワークの一種です。
ニューラルネットワークの仕組みや種類についてまとめたこちらの記事もぜひチェックを!

通常のリカレントニューラルネットワーク(RNN)の、「時系列データの長期記憶を保持するのが困難である」という課題を解決するために開発されたのがLSTMになります。
RNNの概要はこちら↓↓

RNNの派生型LSTMについてはこちら↓↓

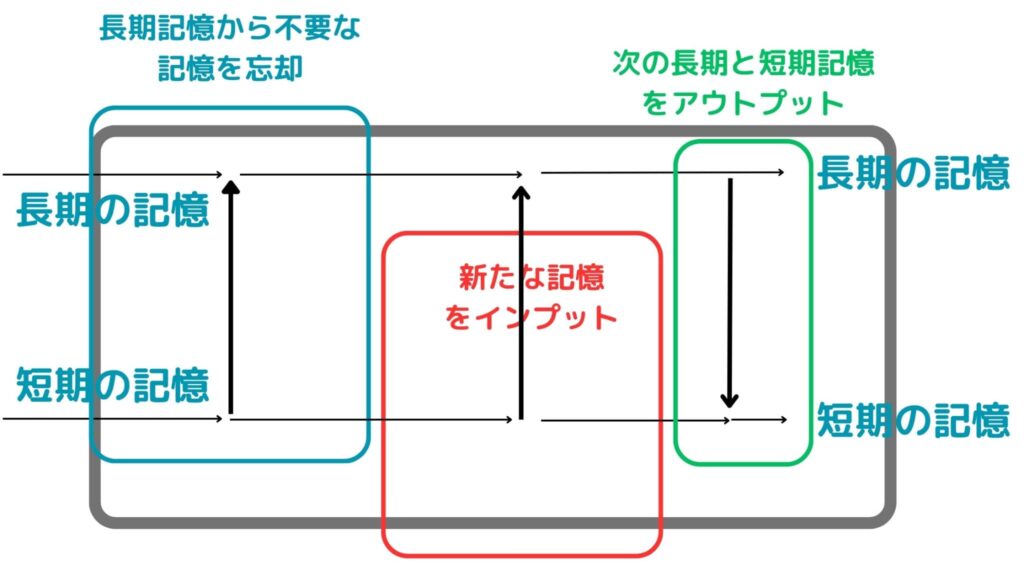
LSTMモデルでは上記のイメージ図のように、長期記憶と短期記憶を保持しつつ、長期記憶から不要な記憶を忘却させ新たな記憶をインプットして次に渡していくような仕組みになっています。
このモデルはデータの中に潜む複雑な非線形関係を捉えることができ、特に大量のデータが用意できる場合に効果を発揮します!
・非線形データへの相性
非線形なデータや複雑な時系列パターンをモデリングするのに優れている
・長期記憶に強い
時系列データの長期記憶も保持しつつ新しい記憶をインプットしていくことが可能
ニューラルネットワークについては以下の学習コンテンツもぜひ覗いてみてくださいーー!
Prophet
最後にProphet。
Prophetは、Facebookが開発した時系列データの予測に特化したモデルです!
季節性や休日などの時系列的要因を柔軟に取り扱うことができ、トレンドの変化に適応できます。
非常に使いやすくパラメータの調整が容易なため、初学者にもおすすめのAIモデルとなっています!
・シンプルで使いやすい
・外れ値に強い
外れ値に対して頑健であり、データの不安定性や異常値の存在があっても安定した予測が可能
・オープンソースで広く利用されている
Facebookが開発・メンテナンスしており、豊富なドキュメントやコミュニティサポートを利用できる
AIモデルによる需要予測の具体事例

前章で紹介した3モデルの適用事例を簡単に紹介します!
ARIMAモデルを用いた需要予測
ある小売業界では、スーパーマーケットでの商品の需要予測にARIMAモデルを適用しました。
過去の売り上げデータを学習させたARIMAモデルを用いて未来の需要を予測し、在庫を最適化した結果、在庫コスト減&機会損失の減少&顧客満足度向上に繋がりました!
LSTMを用いた需要予測
ある製造業では、機械の故障データや生産量などから未来の需要を予測し、生産計画を最適化するためにLSTMを活用しています。
データの中に潜む複雑な時系列関係を学習でき、非線形なパターンに対応することが出来るLSTMが活躍し、活用前より効率的な生産計画を実現しました!
Prophetを用いた需要予測
Prophetの利用事例として、小売業の季節性の強い商品や、イベントによる需要変動の予測が挙げられます!
Prophetは季節性を柔軟に扱えるため、クリスマスやお正月、ゴールデンウイークなど、季節イベントによる需要予測において有用です!
Pythonによる実装

ここからは、実際の需要予測の手法をPython上で実装していきます!
今回はシンプルな例として、年月日と売れた個数からなるデータを学習させてLSTMモデルを構築し、実際に需要の予測値の算出まで行っていきます。
以下の流れで分析を進めます。
1. 必要なライブラリのインポート
2. 日付と需要(売上数)からなるダミーデータの生成
3. データの前処理
4. LSTMモデルの構築
5. テストデータの設定&モデルの性能評価
6. 予測結果を可視化
1. 必要なライブラリのインポート
まずはじめに必要なライブラリをインポートしてあげましょう。
普段importすることの多いnumpyやpandas、可視化に用いるmatplotlib以外に、今回はLSTMモデルを利用するのでそれに関連するものもインポートしてしまいます!
# 必要なライブラリのインポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from keras.models import Sequential
from keras.layers import LSTM, Dense2.日付と需要(売上数)からなるダミーデータを生成
次にダミーデータを生成します。
各コードで何を行っているかは#で記載の通りです。
# 疑似乱数の設定
np.random.seed(1)
# 2022/1/1から2023/12/31までの日付データを1日ごとに生成
date_range = pd.date_range(start='2022-01-01', end='2023-12-31', freq='D')
# 正規分布からの乱数に疑似的に周期性を持たせた値を加算したものを需要データとして生成
demand_data = np.random.normal(loc=50, scale=10, size=len(date_range)) + np.sin(np.linspace(0, 4*np.pi, len(date_range)))
# 生成された日付データと需要データを結合しdataに格納
data = pd.DataFrame({'Date': date_range, 'Demand': demand_data})
上記コードにより、時系列データを模したダミーデータを生成し、データフレームに格納できました!
データの中身を確認してみましょう!
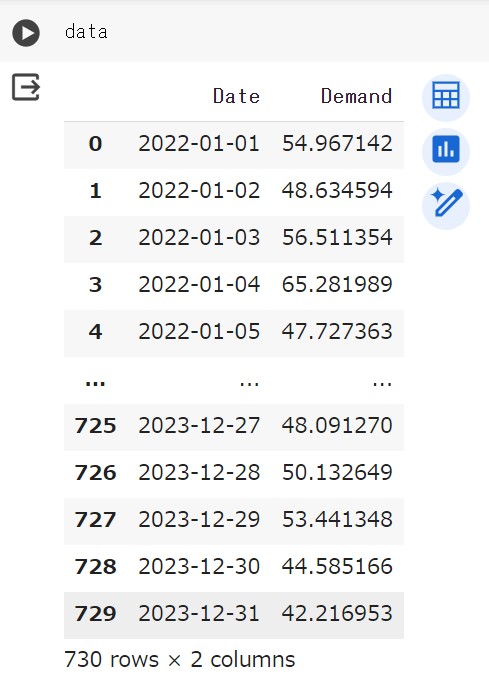
365日×2年間分の730行からなる需要量のダミーデータが作成されていることが分かります!
手元に実際の時系列データがある方は、そちらを使ってみましょう!
3. データの前処理
続いて時系列データの前処理として、正規化・整形・ラベルの作成を行っていきます。
# データの正規化
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data['Demand'].values.reshape(-1, 1))
# データの整形(データの95%を学習用として使用)
training_data_len = int(np.ceil(len(scaled_data) * .95))
train_data = scaled_data[0:int(training_data_len), :]
# ラベルの作成
x_train, y_train = [], []
for i in range(60, len(train_data)):
x_train.append(train_data[i-60:i, 0])
y_train.append(train_data[i, 0])
x_train, y_train = np.array(x_train), np.array(y_train)4. LSTMモデルの構築
このフェーズでは、実際にLSTMモデルを構築していきます!!
# LSTMモデルの構築
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))
model.add(LSTM(units=50, return_sequences=False))
model.add(Dense(units=25))
model.add(Dense(units=1))
# モデルのコンパイル
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルのトレーニング
model.fit(x_train, y_train, batch_size=1, epochs=1)
モデル構築の箇所では各層を追加し、ユニット数や出力の指定を行っております。
そしてコンパイルの箇所で最適化アルゴリズム:adam、損失関数:平均二乗誤差をそれぞれ指定し、学習させています!
5. テストデータの作成&モデルの性能評価
続いてこちらのフェーズでは、テストデータを作成し、そのテストデータとLSTMモデルから出力させた予測値をもとに、モデルの性能を評価しています。
# テストデータセットの作成
test_data = scaled_data[training_data_len - 60:, :]
# 特徴とラベルの作成
x_test = []
y_test = data['Demand'][training_data_len:].values
for i in range(60, len(test_data)):
x_test.append(test_data[i-60:i, 0])
x_test = np.array(x_test)
# データの再形成
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
# 予測値の取得
predictions = model.predict(x_test)
predictions = scaler.inverse_transform(predictions)
# モデルの性能評価
rmse = np.sqrt(np.mean(((predictions - y_test) ** 2)))
print(f'Root Mean Squared Error (RMSE): {rmse}')
6. 予測結果を可視化
ここまできたら、最後に予測結果を可視化します!
# 予測結果の可視化
train = data[:training_data_len]
valid = data[training_data_len:]
valid['Predictions'] = predictions
plt.figure(figsize=(16, 8))
plt.title('Model')
plt.xlabel('Date')
plt.ylabel('Demand')
plt.plot(train['Date'], train['Demand'])
plt.plot(valid['Date'], valid[['Demand', 'Predictions']])
plt.legend(['Train', 'Test', 'Predictions'], loc='lower right')
plt.show()
上記により、学習データ(Train)とテストデータ(Test)で示す実際の需要と、モデルによる予測結果(Predictions)が同プロット上に表示され、視覚的にモデルの性能を評価することが可能です!
実際の出力結果を見てみましょう!
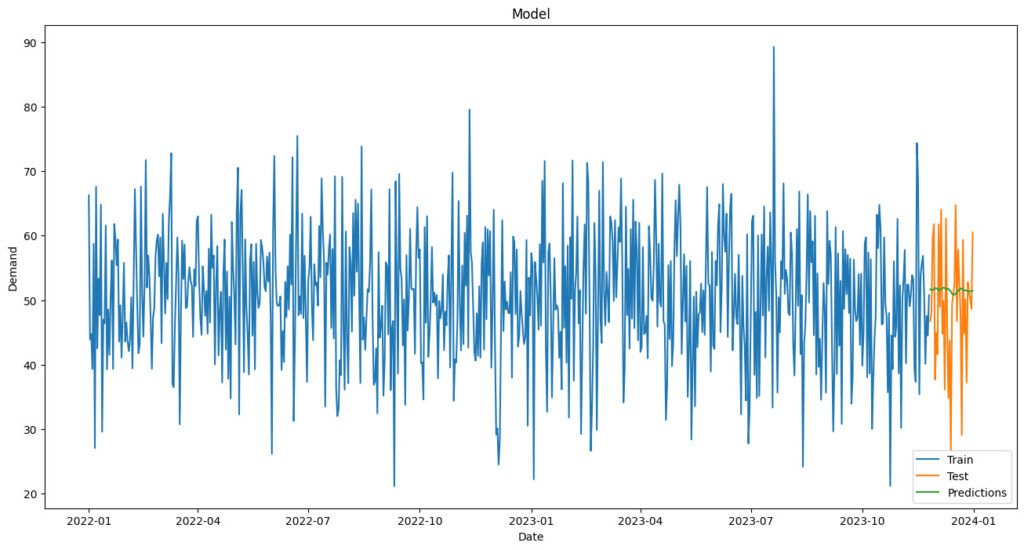
結果がしっかりとグラフ上に可視化できていることが確認できますね!!
最後の方の60日間はテストデータとしていて、予測値を出した際に評価を行っていました。
実際にモデルを作成して予測に用いる際には、パラメータを調整する必要があり、そのためにテストデータによる性能評価・検証のフェーズが存在します!
AIモデル×需要予測のまとめ

ここまでご覧いただきありがとうございました!
本記事では、AIモデルを使用して需要を予測する方法や事例についてまとめました!
需要予測はビジネスのあらゆる分野で重要な課題であり、AIの進化に伴ってより精緻で効果的な予測が可能になっています!
ぜひ理解して、自分でAIモデルを使えるようになりましょう!
このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















