
RNNの派生型LSTMについてわかりやすく解説!時系列データをPythonで分析していこう!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
ディープラーニングの日進月歩の進化により、数年前と比較して飛躍的に言語処理能力が上がっています。
今でこそ、OpenAIのGPTモデルやGoogleのPaLMやMetaのLLaMAなど様々な言語モデルが登場し数年前まで考えられなかった高精度で言語を扱えるようになっていますが、この進化の過程で様々な研究がされてきました。
これまでの進化の過程を理解することは最新のAIを理解することにも繋がります。

この記事では、そんな進化の過程の中でも有名なLSTMについて解説していきたいと思います。
以下のYoutube動画でも解説していますので合わせてチェックしてみてください!

LSTMとは
LSTMは「Long short term memory」の略で、その名の通り長い期間や短い期間の記憶をいい感じに保持してくれる手法で時系列処理や自然言語処理領域で利用されてきたRNNの派生手法になります。
LSTMは1997年にS. Hochreiter 、 J. Schmidhuberによって提案されました。
LSTMは端的に言うとRNNが持っていた勾配消失問題を解決した手法。
では、勾配消失問題とはどんな問題なのでしょうか?
そのためにLSTMの元となるRNNの問題を見ていきましょう!
RNNは以下のように層を連ねて時系列データや自然言語処理の文脈の意図を把握していく構造のため、多層になる傾向があります。
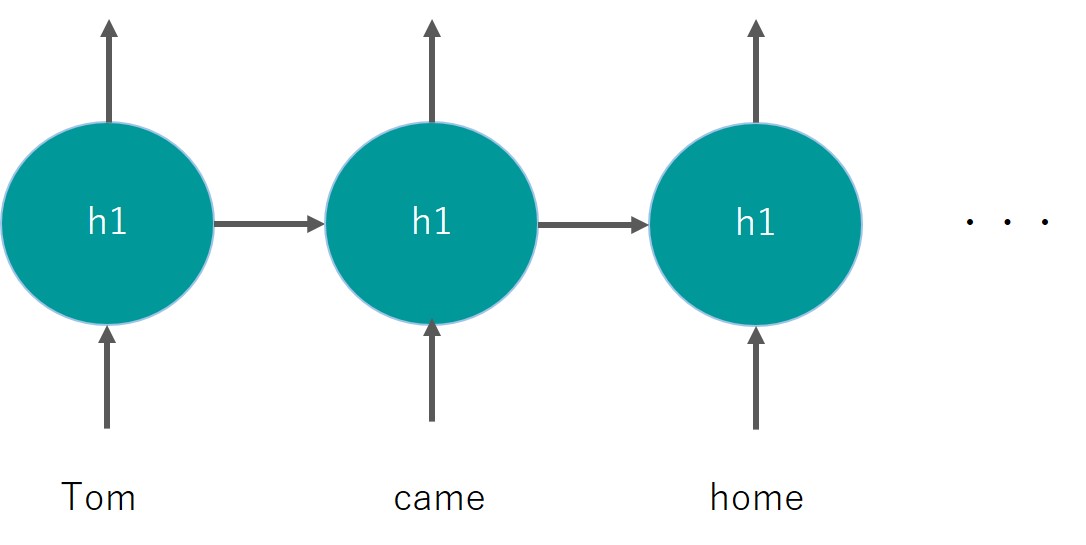
そしてこのようなディープラーニング構造のパラメータ最適解を求める上で、微分を行い勾配を計算して重みを更新していくのですが、この勾配が0に近くなってしまうと更新幅が小さくなり最適解にたどり着かなくなる問題、これが勾配消失問題なのです!
詳しい説明は省きますが、勾配を計算する上で誤差逆伝播法というアプローチを用いて複数回微分を重ねて行うのですが、この際に勾配がどんどん小さくなり勾配消失問題が起きてしまうのです!
この問題のせいでディープラーニングを多層にすることが難しく時系列データの長期記憶を保持出来ない状態になっていました。
そんな中登場したのが、LSTMなのです!
LSTMでは、長期の記憶と短期の記憶を保持しつつ、いい感じに過去の不要な記憶を忘却しつつ新しい記憶をインプットできるアーキテクチャになっています。
ザッと数式を使わずイメージだけ図にすると以下のような感じになります。
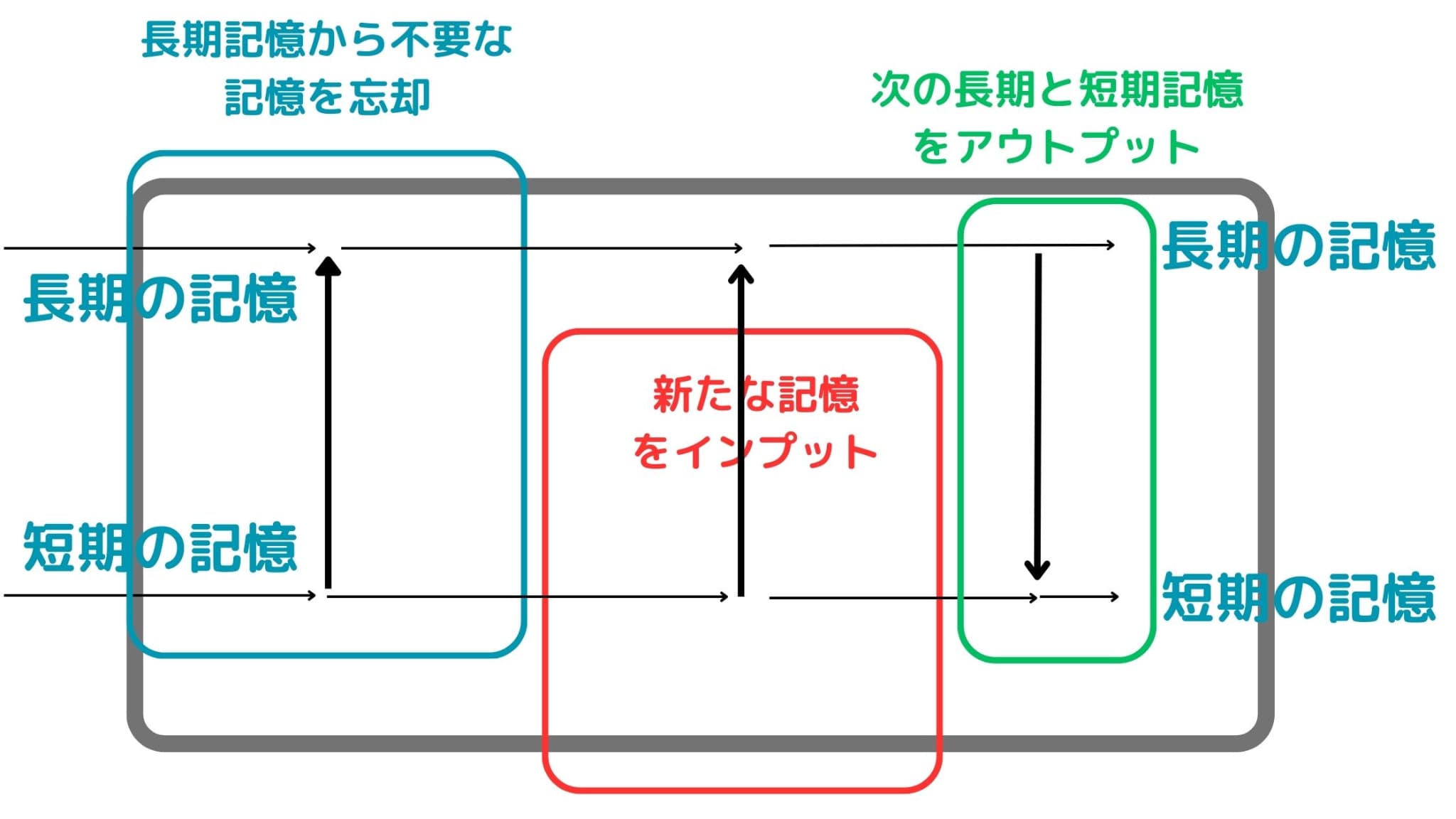
長期記憶と短期記憶を保持しつつ、長期記憶から不要な記憶を忘却させ新たな記憶をインプットして次に渡していくようなアーキテクチャになっています。
これを実際に数式を使って図で表現しているのが以下です。
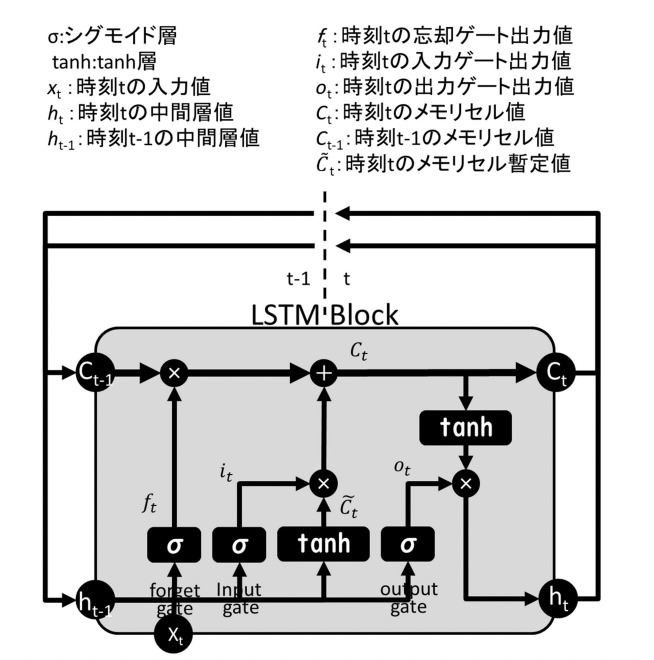
(出典:LSTM(Long Short-Term Memory)を活用した ダム流入量予測に関する研究)
大まかな構造自体は、ざっくりイメージの図と同様の構造になっていることが分かると思います。
ちょっとわかりにくいのですが、最初の記憶忘却の部分は
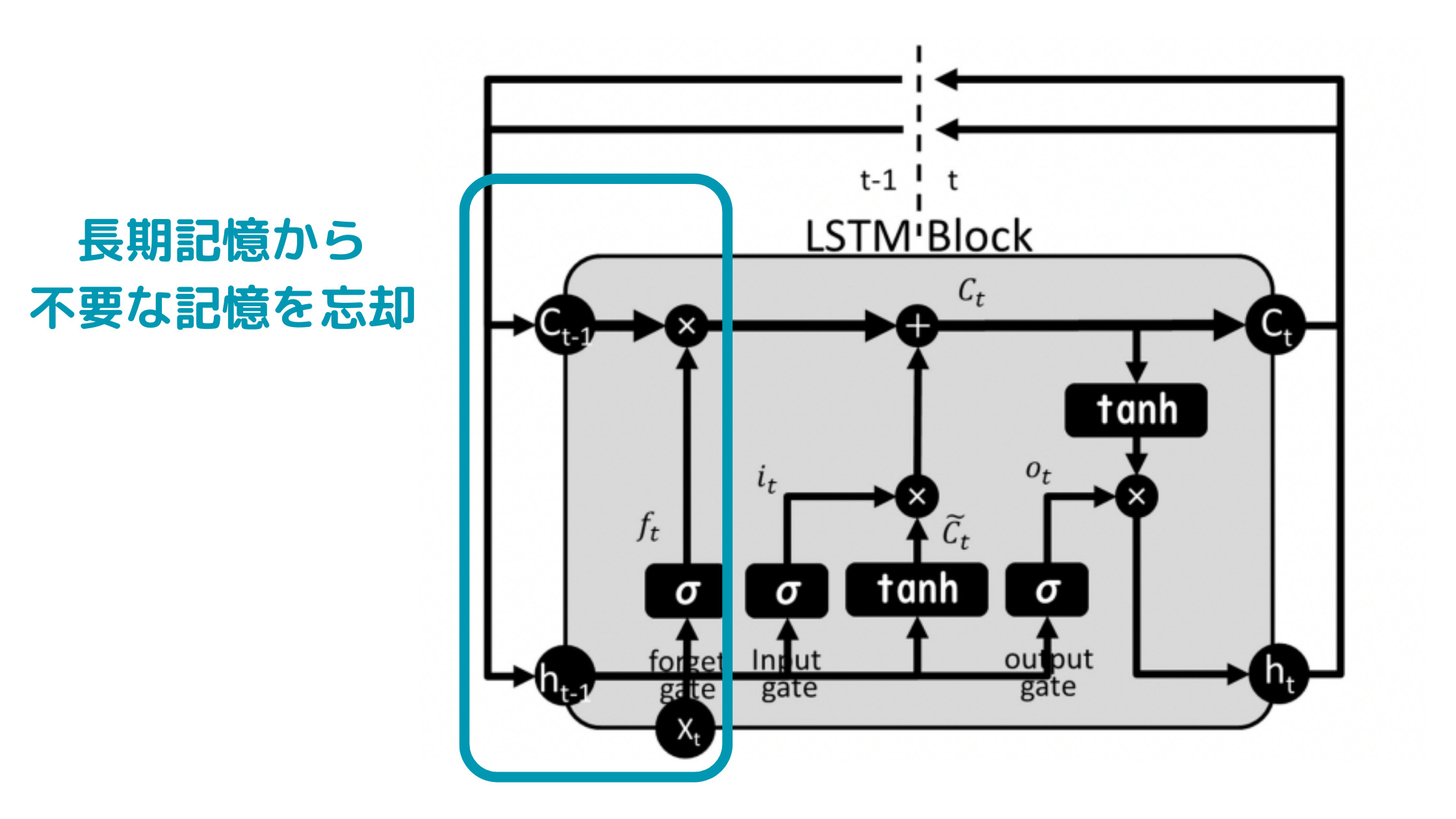
以下のように特定の関数と長期記憶をかけ合わせる(アダマール積)によって忘却を実現しています。
\begin{eqnarray} f_{t} × C_{t-1} \end{eqnarray}
アダマール積では、行列に対して要素ごとに積を取ります。
LSTMをPythonで実装してみよう!
ざっくりLSTMの構造が分かったところで、LSTMをPythonで実装していきましょう!
今回はサンプルとして時系列データをシミュレーション発生させて、それをLSTMで予測していくような処理を作っていきます。
コード全体は以下です。
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# データ生成 (サンプルのため、sin関数を用います)
timesteps = 10
data = np.sin(np.linspace(0, 20 * np.pi, 1000))
# 入力データと正解データの作成
X = []
Y = []
for i in range(len(y) - timesteps):
X.append(data[i:i+timesteps])
Y.append(data[i+timesteps])
X = np.array(X).reshape(-1, timesteps, 1)
Y = np.array(Y).reshape(-1, 1)
# モデルの定義
model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, 1), return_sequences=True))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルの学習
model.fit(X, Y, epochs=50, batch_size=32)
# 予測
test_input = np.array([np.sin(np.linspace(20*np.pi, 21*np.pi, timesteps))]).reshape(-1, timesteps, 1)
predicted_output = model.predict(test_input)
print("予測結果:", predicted_output)
具体的に処理を見ていきましょう!
まず以下の部分でシミュレーションデータを発生させています。データは1000個のSIN関数の系列データでを発生させています。
# データ生成 (サンプルのため、sin関数を用います)
timesteps = 10
data = np.sin(np.linspace(0, 20 * np.pi, 1000))
# 入力データと正解データの作成
X = []
Y = []
for i in range(len(y) - timesteps):
X.append(data[i:i+timesteps])
Y.append(data[i+timesteps])
X = np.array(X).reshape(-1, timesteps, 1)
Y = np.array(Y).reshape(-1, 1)
それをXというリストに10個ずつのウィンドウでデータを格納し、Yというリストに1個ずつ予測対象を格納しています。
t-10,・・・t-1期のデータをもとにt期を予測する構造になっています。
その後の処理でLSTMのアーキテクチャを用いたディープラーニングモデル構築して学習し予測しています。
# モデルの定義
model = Sequential()
model.add(LSTM(50, input_shape=(timesteps, 1), return_sequences=True))
model.add(LSTM(50))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
# モデルの学習
model.fit(X, Y, epochs=50, batch_size=32)
# 予測
test_input = np.array([np.sin(np.linspace(20*np.pi, 21*np.pi, timesteps))]).reshape(-1, timesteps, 1)
predicted_output = model.predict(test_input)
print("予測結果:", predicted_output)予測結果は0.805となりました!非常に簡単に実装できることが分かったと思います!
LSTM まとめ

ここまでご覧いただきありがとうございました!
本記事では、LSTMについて簡単に解説してきました!
LSTMの登場によってRNNの問題をいくつか克服したのですが、自然言語処理の世界において現在では大量のパラメータを持つ事前学習モデルである大規模言語モデルが主流になっています。
現在は大量のデータ・パラメータと資本力で殴り合う世界になってきてしまっていますが、過去にはこのようなアーキテクチャの改造によるブレークスルーが合ったこと覚えておくとよいでしょう!
さらに色んなディープラーニングの手法を詳しく知りたい方は以下の記事を参考にしてみてください!
・RNN
・AlexNet
・ResNet
・Transformer
LSTMを含む3種のAIモデルによる需要予測についての記事はこちら↓↓

また、より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















