オートエンコーダ(autoencorder)についてわかりやすく解説しPython実装!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
最近ますます注目されているディープラーニングのや生成AI。
昨今OpenAIのGPTモデルやGoogleのPaLMやMetaのLLaMAなど様々な言語モデルが登場しています。
進化のスピードは驚くほど早く、「なぜこんなに急激にAIが賢くなったの?」と思ったことはありませんか?
実は、これらの最先端AIはいきなり誕生したわけではありません。
歴代の研究者たちが積み重ねてきた数々のブレークスルーが基盤となり、その流れの中で今のAIが存在しているのです!
その重要なブレークスルーの1つが「オートエンコーダ(autoencorder)」。
今回はこのオートエンコーダの仕組みや使われ方を、わかりやすく解説していきます!
さらに、記事だけでなく 動画解説 も用意しているので、ぜひあわせてチェックしてみてください!
オートエンコーダとは
それでは早速オートエンコーダについて見ていきましょう!
オートエンコーダは2006年にディープラーニングの大家であるジェフリー・ヒントン氏が提案したアプローチです。
ジェフリー・ヒントン氏は2012年にAlexNetを使って画像認識コンペで2位に大差をつけて優勝し、AIブームを巻き起こした張本人です!
オートエンコーダとは、簡単に言うと
特定のインプットデータ(主に画像)の次元を一旦圧縮しそれらの次元を元に戻し、インプットとアウトプットの差分を小さくするようにニューラルネットワークを学習するアプローチ
です。
図にすると以下のようなイメージ。
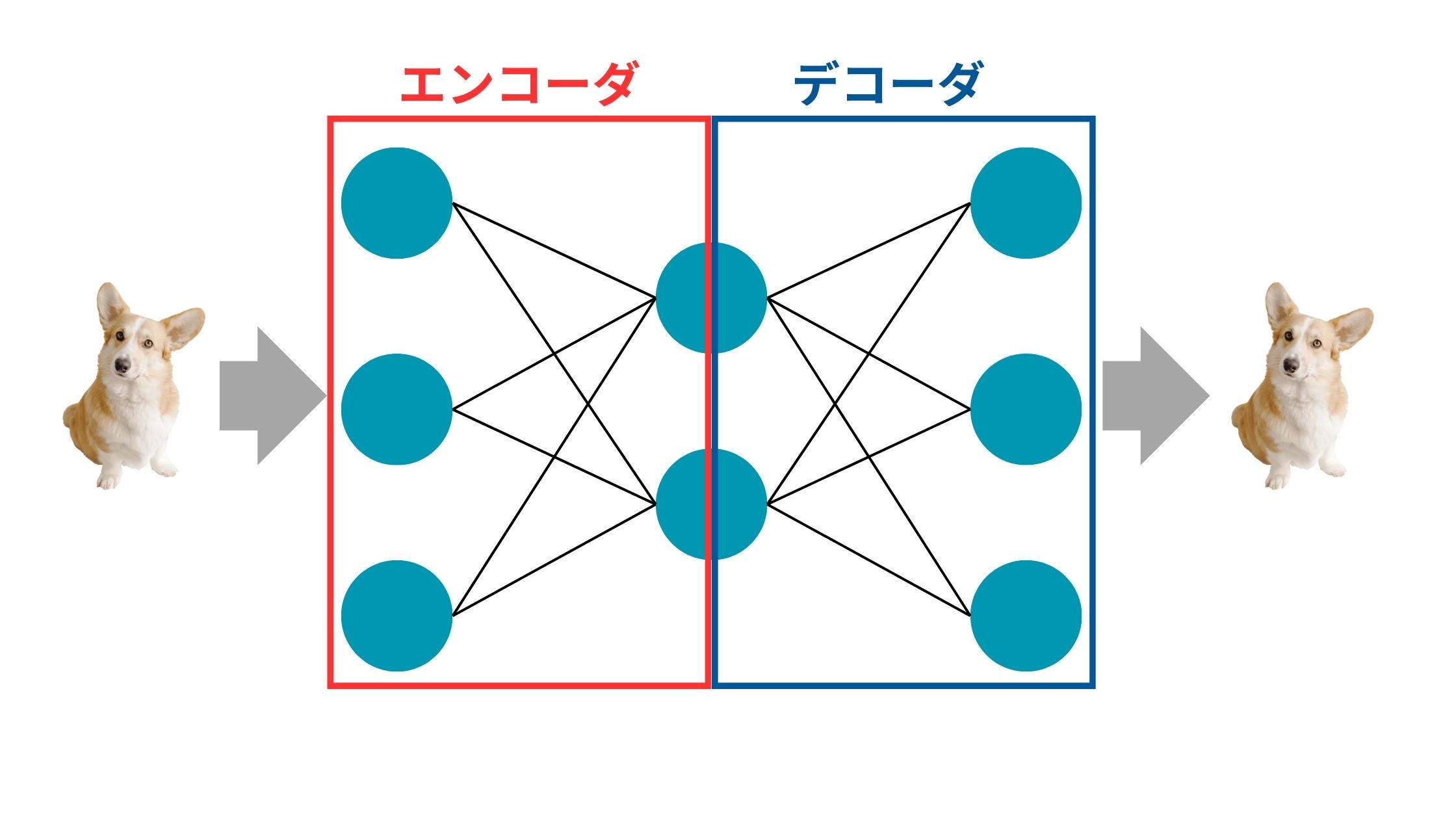
犬の画像を入れてあげて、それを次元圧縮して、それを元の次元に戻して元の画像に近い犬の画像をアウトプットします。
次元圧縮する部分をエンコーダ、圧縮された次元を元に戻す部分をデコーダを呼びます。
それでは、果たしてこのオートエンコーダにはどんなメリットがあるのでしょうか?
例えば、オートエンコーダを使うことで画像の抽象的な特徴を捉えて学習してくれるので、ノイズを除去することが可能です。
後ほどPythonで実装していきますが、Mnistという0~9の手書き数字文字のデータをオートエンコーダに入れて学習した例を取り上げてみましょう!
以下は、それぞれの数字の元の画像(上)と変換後の画像(下)を並べたものです。
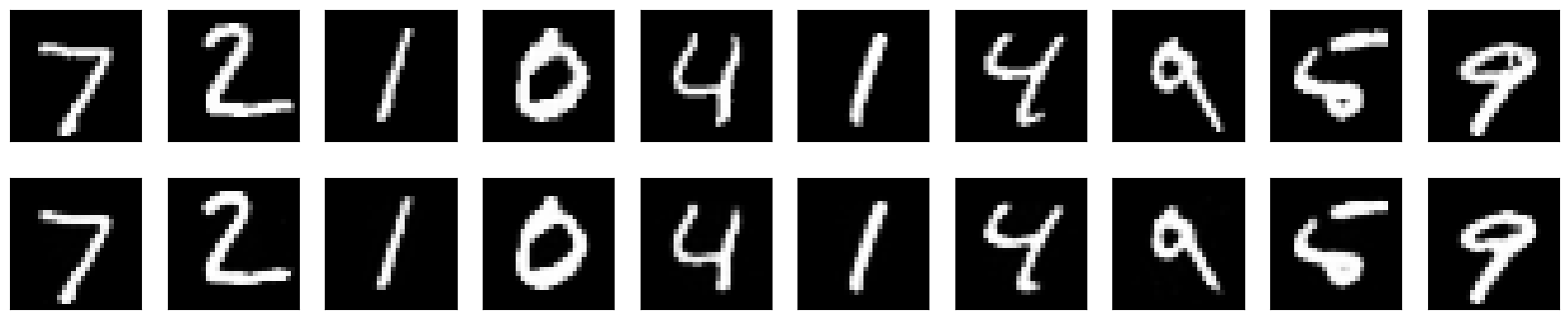
これをよく見てみると、上の画像に存在するノイズが下の変換で除去されていることが分かります。
例えば、一番右の9の元の画像に存在する、チョンが変換後に消えていることが分かりますね!
こんな感じで全てのデータに共通する抽象レイヤーを学習してくれるので画像からノイズを除去するのに有効なんです!
また、異常検知問題にもオートエンコーダは使えます。
例えば、この0~9の画像で学習したオートエンコーダのモデルに0~9でないAという手書き文字画像を入れた場合、上手く元の画像に戻せません。
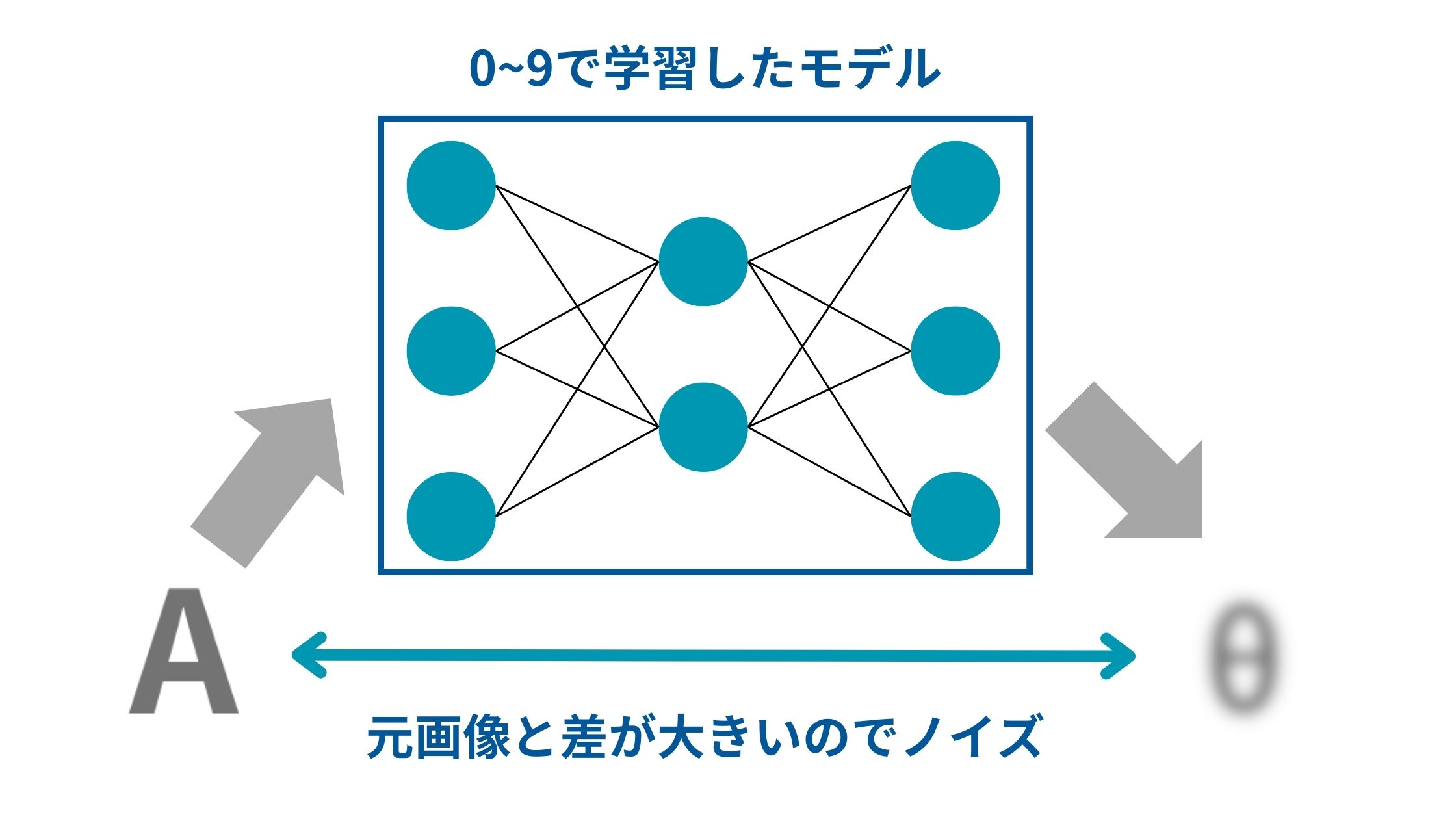
そのため元の画像とオートエンコーダで変換した後の画像の差分が非常に大きくなります。
この特性を使って元の画像と変換後の画像のギャップが大きい場合は異常値であると判断することができます。
オートエンコーダの考え方は、最近の生成モデルにも取り入れられており、非常に重要です。
画像生成AIにおける生成プロセスのベースになっている拡散モデルは、まさにこのオートエンコーダの考え方が用いられています。
ぜひ関連付けて理解しておきましょう!
オートエンコーダをPythonで実装してみよう!
それでは最後にオートエンコーダをPythonで実装して見ていきましょう!
ディープラーニングを実装するためのライブラリであるKerasを使っていきます!
実行環境は特にこだわりがなければGoogle Colabをオススメします。
手書き文字のノイズ除去
早速ですが全体のコードは以下!
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
# MNISTデータセットの読み込み
(x_train, _), (x_test, _) = mnist.load_data()
# データの前処理
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# オートエンコーダのモデルを定義
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
# モデルのコンパイル
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer=Adam(), loss='binary_crossentropy')
# オートエンコーダの訓練
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
# テスト画像をエンコードおよびデコード
encoded_imgs = autoencoder.predict(x_test)
decoded_imgs = autoencoder.predict(encoded_imgs)
# 結果の表示
n = 10 # 表示する画像の数
plt.figure(figsize=(20, 4))
for i in range(n):
# 元の画像
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 再構築された画像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
さきほどお伝えしたように、この実装ではMnistという手書き数字のデータセットを使っています。
そして以下の部分で、オートエンコーダのモデル定義と学習をしています。
# オートエンコーダのモデルを定義
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
# モデルのコンパイル
autoencoder = Model(input_img, decoded)
autoencoder.compile(optimizer=Adam(), loss='binary_crossentropy')
# オートエンコーダの訓練
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))オートエンコーダのオートエンコーダのエンコード部分では活性化関数としてReLU関数を、デコード部分ではシグモイド関数を用いています。
最終的に以下の部分でオートエンコーダにテストデータをかけた結果を出力しています。
# テスト画像をエンコードおよびデコード
encoded_imgs = autoencoder.predict(x_test)
decoded_imgs = autoencoder.predict(encoded_imgs)
# 結果の表示
n = 10 # 表示する画像の数
plt.figure(figsize=(20, 4))
for i in range(n):
# 元の画像
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 再構築された画像
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
この結果が先ほどお見せした10個の画像になります。
ぜひご自身の環境でも動かしてみてください!
手書き文字を用いた異常検知
続いて異常検知について見ていきましょう!
流れとしては、まずオートエンコーダで1の文字のみを使った学習を行いモデルを構築します。
そして出来上がったモデルに1の文字を投入して元の画像と再構築後の画像の差分を算出しそれを元に閾値を設定します。
そして、未知データ(0, 2, 3・・・とか)に対して「元の画像」と「再構築した後の画像」の差分を計算し、それが閾値以上であれば異常と判断するようなアプローチです。
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
# MNISTデータセットの読み込み
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 1から9の数字のみを選択
x_train = x_train[np.isin(y_train, [1,2,3,4,5,6,7,8,9])]
y_train = y_train[np.isin(y_train, [1,2,3,4,5,6,7,8,9])]
# データの前処理
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_train = x_train.reshape((len(x_train), np.prod(x_train.shape[1:])))
x_test = x_test.reshape((len(x_test), np.prod(x_test.shape[1:])))
# 訓練データとバリデーションデータに分割
x_train, x_valid = train_test_split(x_train, test_size=0.2, random_state=42)
# オートエンコーダのモデルを定義
input_img = Input(shape=(784,))
encoded = Dense(128, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
# モデルのコンパイル
autoencoder.compile(optimizer=Adam(), loss='binary_crossentropy')
# オートエンコーダの訓練
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_valid, x_valid))
# バリデーションデータセットで再構成誤差の計算
decoded_imgs = autoencoder.predict(x_valid)
reconstruction_error_valid = np.mean(np.abs(x_valid - decoded_imgs), axis=1)
threshold = np.mean(reconstruction_error_valid) + np.std(reconstruction_error_valid)
# "0"の数字の画像をテストデータセットから選択
x_test_zero = x_test[y_test == 0]
# テストデータセットで再構成誤差の計算
decoded_imgs_test = autoencoder.predict(x_test_zero)
reconstruction_error_test = np.mean(np.abs(x_test_zero - decoded_imgs_test), axis=1)
# 異常検知
anomalies_test = reconstruction_error_test > threshold
sum(anomalies_test)/len(anomalies_test)1.0
結果として全ての0を異常と判別することができました!
異常検知に関して詳しくは以下の記事にまとめていますのでチェックしてみてください!

オートエンコーダ まとめ
ここまでご覧いただきありがとうございました!
本記事ではオートエンコーダについて簡単に解説してきました!
さらに色んなディープラーニングの手法を詳しく知りたい方は以下の記事を参考にしてみてください!
・RNN
・AlexNet
・ResNet
・Transformer
また、より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!