
【大量の学習データ!】Meta開発のLLMであるLLaMA、LLaMA2、派生モデルAlpacaについて解説!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
OpenAIのGPTやGoogleのPaLMなど、各社AIブームにおける覇権争いを繰り広げていますが、その中でもこの記事ではMetaが開発している大規模言語モデルのLLaMAについて解説していきたいと思います!
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
目次
LLaMAの仕組みや構成
LLaMAは(Large Language Model Meta AI)の略であり、Metaが2023年2月に発表した大規模言語モデルです。
以下がLLaMAの論文になります。
ちなみに英語ですが、LLaMAに関して以下の動画で分かりやすく論文を解説してくれています!
LLaMAは、OpenAIに開発するGPTモデルや、Googleの開発するPaLMなどと比較すると圧倒的に少ないパラメータ数のモデルになっています。
LLaMAは、パラメータ数をおさえながら高精度を実現しているため、世界中の研究者がLLaMAをベースに様々な大規模言語モデルの可能性を探ることが可能になっているんです。
LLaMAのコードはGithubに上がっておりオープンソースとして公開されています。
なんと、Githubのリポジトリからコードを世界中の誰でも確認できるんです!

それでは具体的にどんな特徴があるのか簡単にまとめていきましょう!
パラメータ数
さて、先ほどLLaMAの特徴の1つはパラメータ数の少なさであるとお伝えしましたが、どのくらいのパラメータ数なのでしょうか?
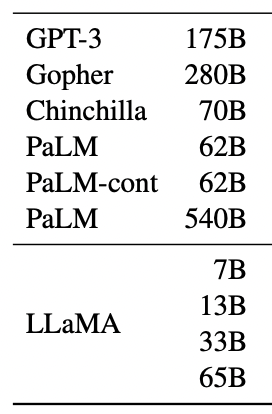
LLaMAは4つのモデルが提供されています。
各モデルのパラメータ数は以下のようになっています。
(出典:LLaMA: Open and Efficient Foundation Language Models)
LLaMAにはそれぞれ、
・70億個(正確には67億個)
・130億個
・330億個(正確には325億個)
・650億個(正確には652億個)
のパラメータ数のモデルが存在しています。
これでも十分パラメータ数は多い気がしますが、GPT-3の1700億個やGoogleのPaLMの5400億個などに比べると圧倒的に少ないのが分かるでしょう!
学習データ
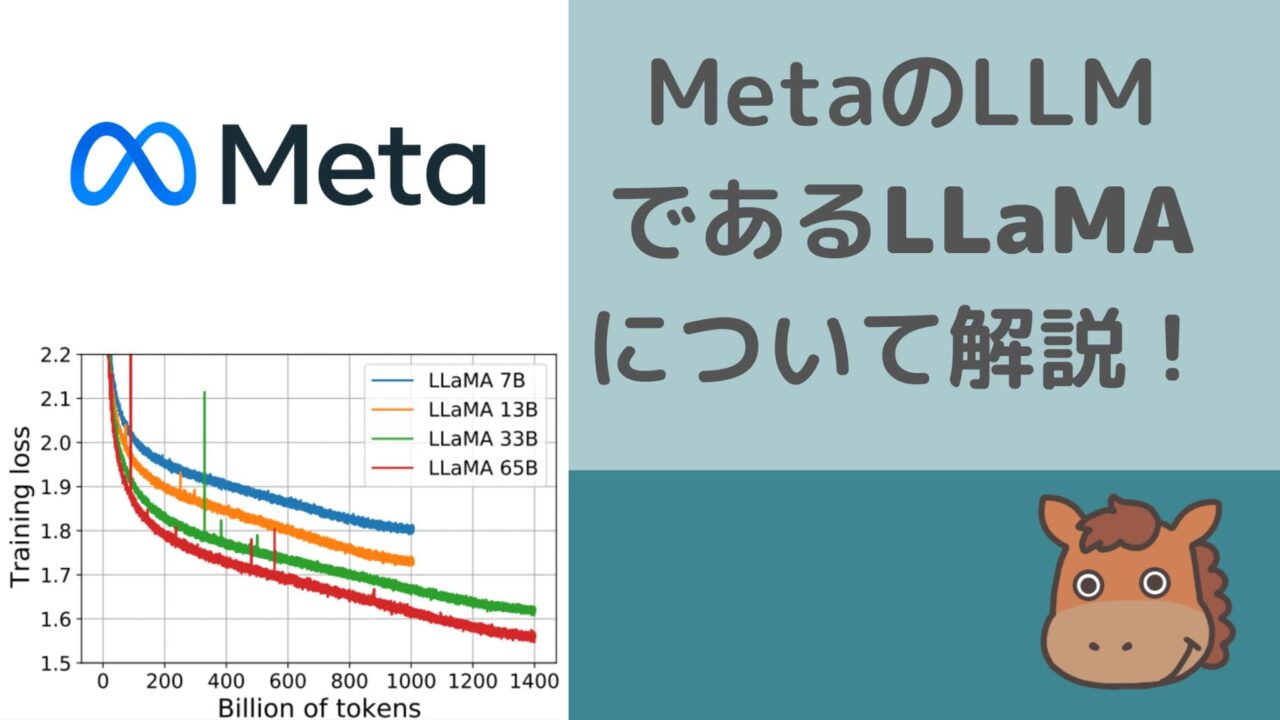
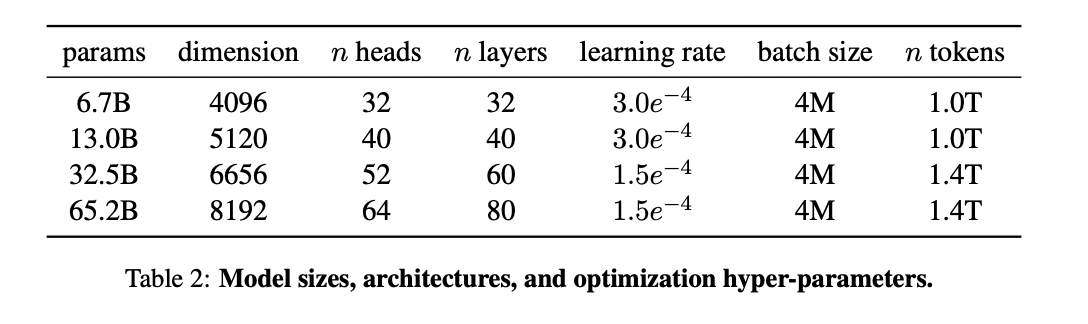
LLaMAでは、パラメータ数が比較的少ない分、大量の学習データで学習させています。
一番パラメータ数の少ない67億個のパラメータ数モデルでも、なんと1兆トークンの学習データで学習しているんです!※1トークンは英語の1単語に等しいです
 (出典:LLaMA: Open and Efficient Foundation Language Models)
(出典:LLaMA: Open and Efficient Foundation Language Models)
最もパラメータ数の多い652億個のパラメータ数モデルだと、1.4兆トークンの学習データになります。
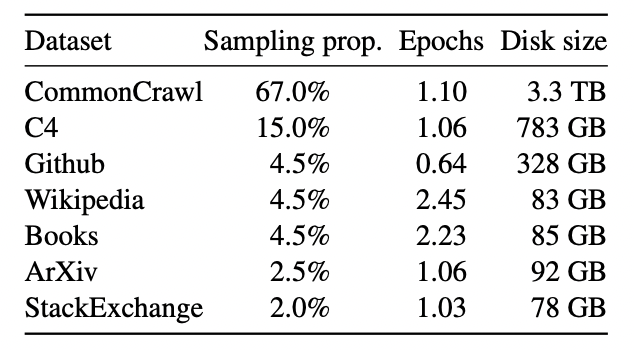
ちなみに学習データのソース割合は以下の表のようになっています。
(出典:LLaMA: Open and Efficient Foundation Language Models)
CommonCrawlはWebサイトのクローリングデータ、C4とはGoogleが用意している巨大データセット「Colossal Clean Crawled Corpus(C4)」でありこちらもクローリングデータですね。
あとはGithubのコードデータセットやWikipediaのデータや書籍・論文などのデータが利用されていることが分かります。
アーキテクチャ
続いてLLaMAのアーキテクチャについて見ていきましょう!
特別なアーキテクチャではなく既存の研究の組み合わせのアーキテクチャになっているようです。
最近の大規模言語モデルはどれもそうですが、LLaMAもご多分に漏れずベースはTransformerのアーキテクチャになっています。
RMSNormalizationによる計算量の削減
計算量を削減するためにLLaMAではRMSNormalizationという正規化手法が用いられています。
RMSとはRoot Mean Squareの略であり、ニューラルネットワークの層に入力する前に平均二乗誤差(Root Mean Square)で正規化してから入力するというアプローチです。
RMSNormalizationに関する論文は以下ですので詳しく知りたい方は是非チェックしてみてください。
これにより大幅な計算量削減に成功しており、論文の中では実行時間を7%〜64%短縮できたと述べられています。
活性化関数にSwiGLUを適用
活性化関数にSwiGLUという関数を使っています。
活性化関数とはザックリ言うと出力値を適当な関数で変換する関数です。
例えば、
\begin{eqnarray} y= \left\{ \begin{array}{l} 0 (w_1x_1+w_2x_2<=0.5) \\ 1 (w_1x_1+w_2x_2>0.5) \end{array} \right.\end{eqnarray}
みたいな関数があったら出力値が0.5というしきい値で0か1という値に変換されていることが分かります。
これも活性化関数です。
そして、ディープラーニングに古くから利用されてきている活性化関数としてはRELU関数が有名です。
RELU関数とは以下のような関数。
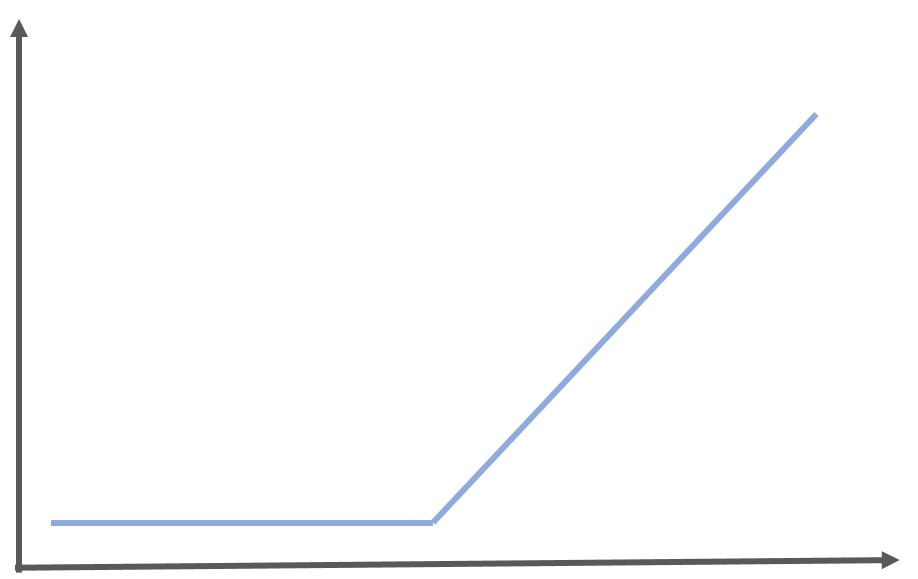
以下のように定式化することができます。
\begin{eqnarray} y= \left\{ \begin{array}{l} x ~~ (x>0) \\ 0~~ (x<=0) \end{array} \right.\end{eqnarray}
0以下は強制的に全部0にしてしまう活性化関数です。
このRELU関数に似た活性化関数としてよく使われるようになってきたのがSwish関数です。
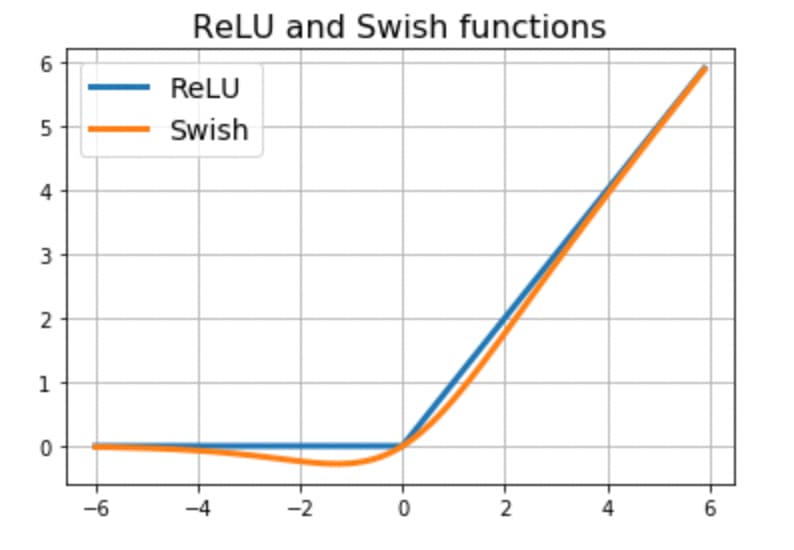
(出典:ReNom:Swish関数の紹介)
RELU関数にかなり近いのですが、入力が0付近で出力が若干負の値を取るようになる活性化関数です。
そしてこのSwish関数とGLU(Gated Linear Units)を組み合わせたものがSwiGLUです。
GLUはザックリ言うと通常の線形アウトプットと活性化関数で変換したアウトプットをかけあわせたものを出力とする処理です。
\begin{eqnarray} GLU = (w_1x_1+w_2x_2) × f(w_1x_1+w_2x_2) \end{eqnarray}
あまりよくわからないと思いますが、いい感じに関数組みあわせて変換するようにしたら精度上がった的な感じです(適当)。
GLUの論文は以下を参考にしてみてください。
絶対位置埋め込み処理でなくて相対位置埋め込み処理
Transformerのアーキテクチャでは単語の位置関係をモデルが理解するためにPosition Embeddingという処理が行われているのですが、LLaMAでは絶対位置埋め込み処理ではなくて相対位置埋め込み処理(Rotary Position Embedding)を用いています。
以下が論文です。
相対位置埋め込み処理は絶対位置埋め込み処理と比較して長文に対する精度が上がることがわかっています。
ここまでLLaMAの特徴を述べてきましたが、要は「これまでの研究で明らかになってきたアプローチを組みあわせてパラメータ数を少なめに学習データを多めに学習させたよ」ってことです。
LLaMAからLLaMA2へ
LLaMAが2023年2月に発表されてから約5ヶ月後の2023年7月19日にMeta社からLLaMA2が発表されました!
LLaMA2の論文は以下です。
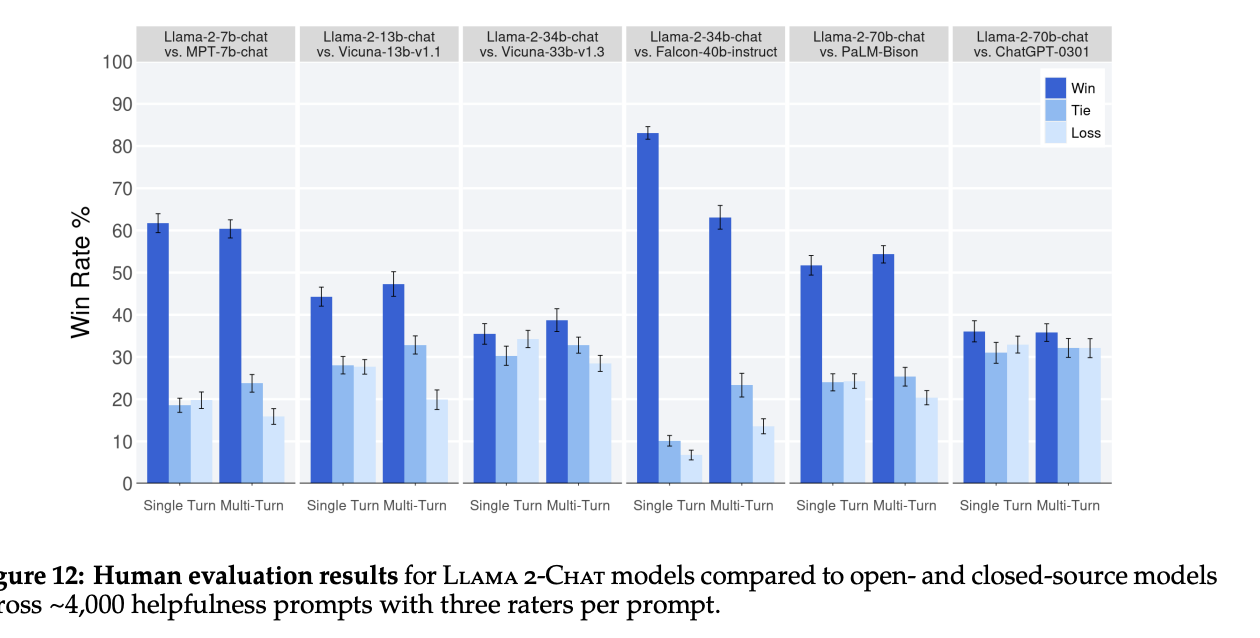
他のモデルとの結果を比較した以下のグラフを見ると、軒並みLLaMA2の評価が高いことが分かります。※人間がどっちのアウトプットの方がよいか下した結果です
それでは、そんなLLaMA2はどんな部分がLLaMAから進化しているのでしょうか?
LLaMA2に関しては以下のYoutube動画でも解説しています!
商用利用可能に
実は、モデルの改善ポイントよりも1番ここが話題になっているところです。
LLaMA1の段階では、オープンソースでコードを確認はできるもののモデルに利用された重み付け(ウェイト)までは特定の研究コミュニティを除いて確認することができませんでした。(※ウェイトは公式には公開していないもののリーク情報によりLLaMA1でも確認することができる状態になってました)
また商用利用は不可能で研究開発のみへの利用が認められていました。
しかし、、、今回公開されたLLaMA2はMeta社から公式に商用利用可能&モデルのウェイトも公開されたのです!!
最近のOpenAIのGPTといいGoogleのPaLMといい、AIモデルのオープン化は逆行しておりどんどん情報が公開されないクローズドな環境になっていってました。
その流れに対して楔を打ったのがMeta!
早速Stable Diffusionを展開するStabilityAIがLLaMA2をファインチューニングして新しい大規模言語モデルを開発したというニュースが出てきています。
このように多くの企業がMeta社のLLaMAをベースにモデルを開発する流れになっていくでしょう!
エンジニアは会社の利益とは関係なく自分の開発したプロダクトやモデルをオープンにしたい生き物なので、このような会社のスタンスはより優秀なエンジニアを集めて長期的に強いAIを作ることに繋がる可能性が高いです!
Grouped Query Attentionを採用
論文からモデルに関する説明を拝借してみましょう!
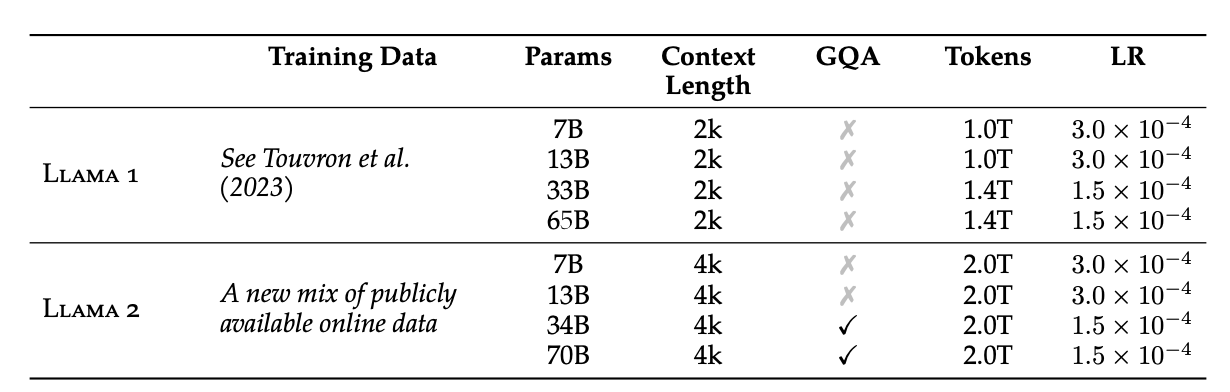
We adopt most of the pretraining setting and model architecture from Llama 1. We use the standard transformer architecture (Vaswani et al., 2017), apply pre-normalization using RMSNorm (Zhang and Sennrich, 2019), use the SwiGLU activation function (Shazeer, 2020), and rotary positional embeddings (RoPE, Su et al. 2022). The primary architectural differences from Llama 1 include increased context length and grouped-query attention (GQA). We detail in Appendix Section A.2.1 each of these differences with ablation experiments to demonstrate their importance.
(Llama 2: Open Foundation and Fine-Tuned Chat Models)
ここで言っているのは、ほぼほぼモデルのアーキテクチャはLLaMAの時と変わらないよーということ。
一部だけGrouped Query Attentionという構造を採用しているのですが、これは以下のように
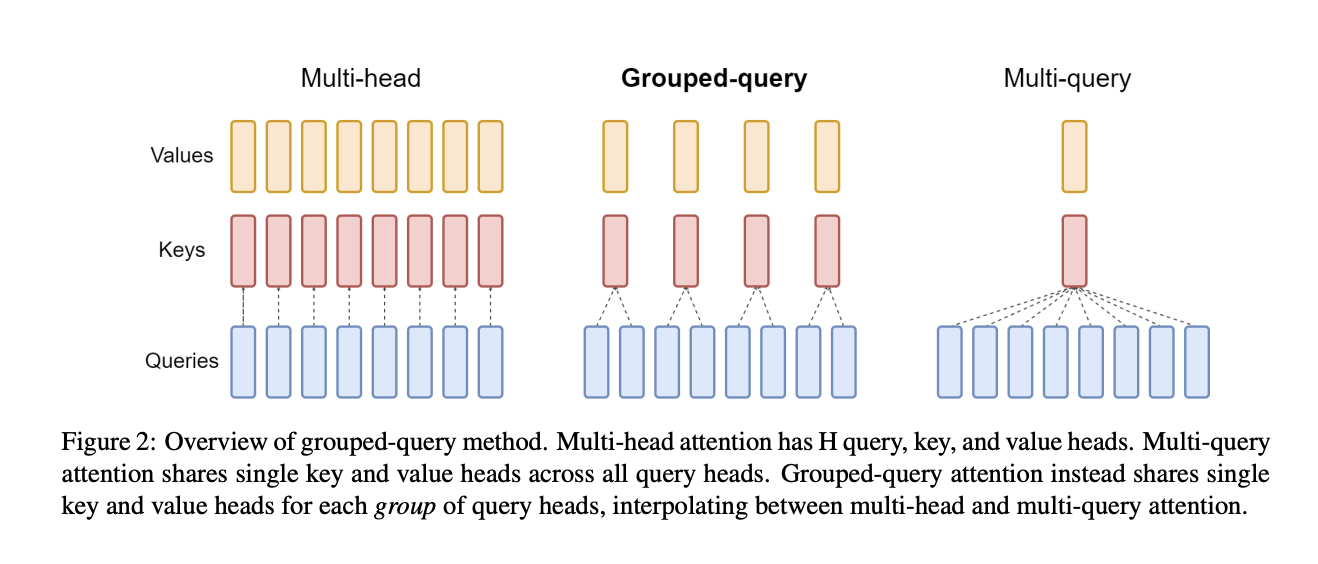
Attention層のKey-Valueの組み合わせをグループ化するアプローチ。
Attention層は大規模言語モデルにおいて非常に重要な役割を持つ層でTransformerの登場で一躍注目を浴びました。
Multi-head Attention層が一般的に用いられており、Multi-queryだと高速化できますが、その分精度が落ちてしまうので、間を取ったちょうどよいGrouped Query Attentionが提案されています。
提案論文は以下です。
学習データセットの刷新とデータ量の増加
LLaMA2では学習データセットが刷新されると共に増加しています。
LLaMAでは以下のように1兆個もしくは1.4兆個のトークンが学習データとして用いられていましたが、LLaMA2で2兆個に増えています。
またcontext lengthと呼ばれるモデルにインプットできるトークンも2倍に増えています。
ファインチューニングと人間による調整
この論文では、LLaMA2と同時にLLaMA2-CHATなるものもリリースしたよと発表してます。
GPT-3.5とChatGPTの関係みたいなものです。
LLaMA2-CHATでは、学習後にファインチューニングや人間による調整が行われてます。
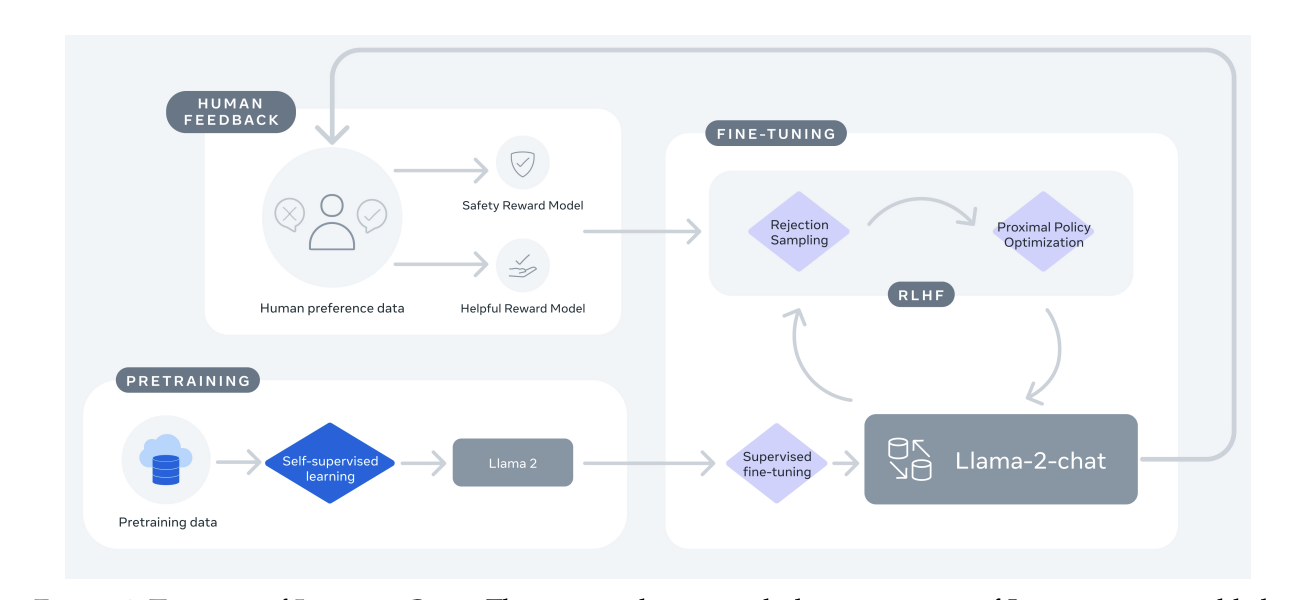
ここの部分について論文の中でもかなり細かく記載されており、特に危険性の少ないアウトプットをするようになったこと(Safety)が強調されています。
実際に以下がSafetyの結果です。
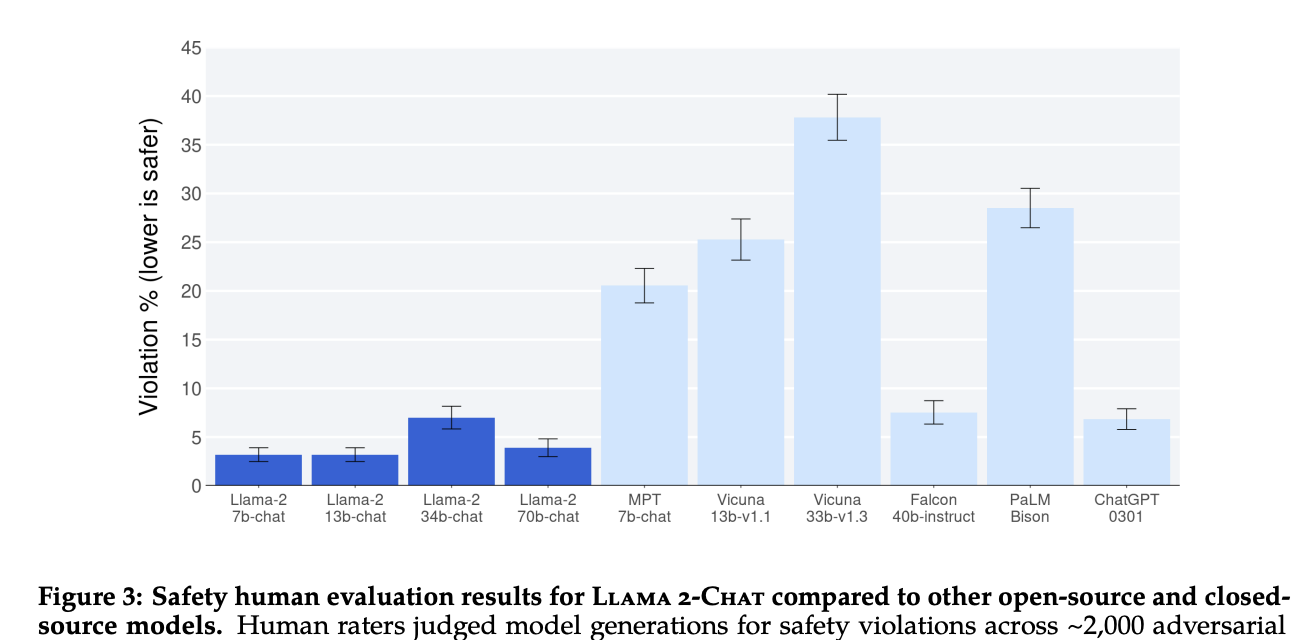
LLaMA2がいかに他のモデルと比較して安全なアウトプットをしてくれるかが分かりますね!
LLaMAからAlpacaへ
実はLLaMAをベースにスタンフォード大学を中心とした大学群の研究チームが67億個のパラメータを持つLLaMAモデルにファインチューニングをかけて精度を向上させたモデルであるAlpacaが発表され話題になりました。
Alpacaの論文は以下です。
たったの70億個のパラメータで、GPT-3.5に匹敵する会話性能を持つということで話題になりました。
LLaMAの根本思想として、世界中の研究者が簡単にファインチューニングして試行錯誤できる軽量モデルを提供する、があったからこそ実現したモデルだと思います。
Googleは「我々にとってのOpenAIではない、オープンソースだ」と言っているくらいは全て公開しようとする流れは冨を独占する企業にとって脅威です。
Meta開発のLLMであるLLaMA まとめ
ここまでご覧いただきありがとうございました!
本記事では、Meta開発のLLMであるLLaMA、そしてLLaMA2、Alpacaについてまとめてきました!
LLMについてある程度理解した後は各種モデルを具体的に手を動かしながら実装してみることが大事です。
各種大規模言語モデル(LLM)をPythonで利用する方法を知りたい方は当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















