
【入門】機械学習のアルゴリズム・手法をPythonとRの実装と一緒に解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
AIやビッグデータ、機械学習という言葉が巷を賑わせていますが、実際に機械学習とは何かご存知でしょうか?

この記事では、機械学習のアルゴリズムや手法の種類とPythonやRによる実装について見ていきますよ!
・機械学習とは
・機械学習の種類
・機械学習をRで実装してみよう!
・機械学習をPythonで実装してみよう!
・機械学習を勉強する方法
機械学習の実装方法について網羅的に知りたいのであれば「スタアカ(スタビジアカデミー)」をチェックしてみてください!
機械学習と密接に関わっているパターン認識についての記事もぜひご参照ください!

目次
機械学習とは
まずは、機械学習について簡単に確認しておきましょう!
以下の動画でも分かりやすく解説していますよー!
機械学習とは、その名の通り「機械に学習させてルールを作り出す」ということ。
機械学習が発展する前は、人間がルールを決めていました。
レコメンドで言えば、

というように(ルールベースレコメンドと呼びます)。
そこに存在するのは人間の勘と想像です。
実際にこのようなレコメンドはまだまだ実用的に使われていますが、より精度の高いレコメンドを行うためには機械学習が必要になります。
「この商品を購入した人はこの商品を購入する確率が高いから、そのようなルールを作る」というように現在存在するデータを学習して自動的にルールを作っていくわけです。
最近よく使われているレコメンドロジックは協調フィルタリングと言います。
簡単に言うと行動パターンの似ているユーザーが買っているモノを似たユーザーにレコメンドするといった仕組み。

レコメンドロジックについてはこちらの記事に詳しくまとめていますのでよければご覧ください!

このように現在存在するデータから自動的にルールを作ってくれるアルゴリズムが機械学習なのです。
ちなみに統計学を起点とする多変量解析手法群もその定義からすると機械学習の中に含まれますが、機械学習手法と統計学ではスタンスが若干違います。
統計学は現在のデータを解釈することを目的としますが、機械学習は未知のデータを正確に予測できることを目的とします。
僕は、統計学は解釈追求型、機械学習は精度追求型と呼んでいます。ただ境目は曖昧ですのでそれほど気にする必要はないでしょう。明確に切り分けることはできません。
詳しくは以下の記事をご覧ください!

機械学習アルゴリズム・手法の種類

続いて、そんな機械学習のアルゴリズムや手法にはどんな種類があるのか見ていきましょう!
機械学習には大きく分けて教師あり学習・教師なし学習・強化学習があります。

教師あり学習
教師あり学習はデータ群に対して正解が紐づいているデータセットを学習する手法のことを指します。
例えば、タイタニックの乗船者情報(後で実際に解析に使用します)では、様々なお客さん情報に対してそのお客さんが生き残ったか死んでしまったかのデータが入っています。
生死のラベルが付いていて、それを基にどんな客が生き残ったかのルールを作ることができるのです。
教師あり学習が最も一般的で様々な場面で使われています。
決定木
決定木はタイタニック乗船データに対しても例として用いられている一般的な手法です。
決定木のアルゴリズムは非常にシンプルで、樹木構造で変数での分類規則を作っていきます。
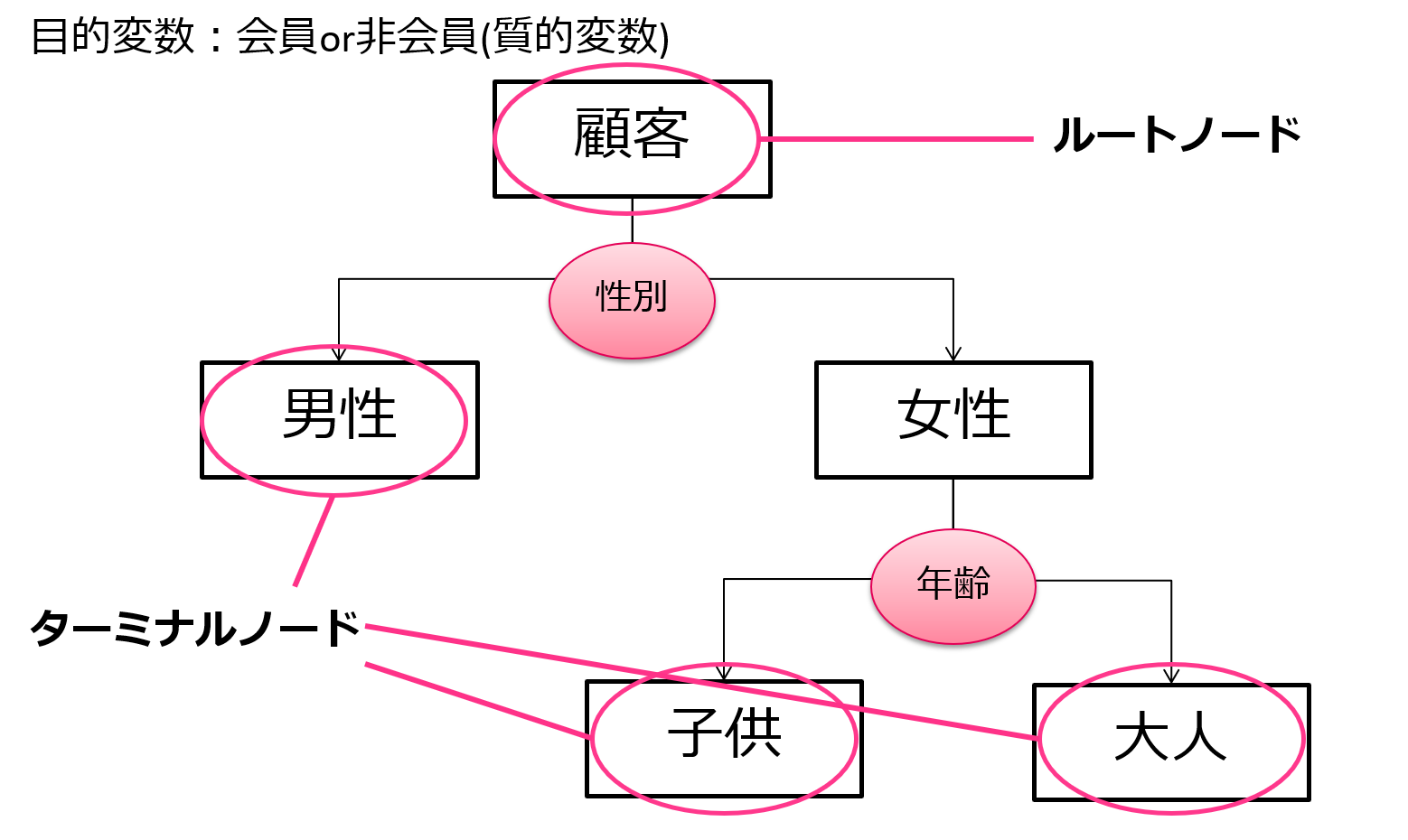
非常に分かりやすくルールも可視化しやすいためビジネスの場面で用いられることが多いです。
そういう意味でいうと、データの解釈のために使われることが多く単純な予測精度を出したいなら他の手法を用いたほうが無難です。
PythonでもRでもライブラリを呼び出すことで簡単に実装が可能。
以下はPythonのコードです。
決定木に関してはPython・Rどちらでの実装も合わせて以下の記事にまとめています!

k近傍法
k近傍法は、未知データの周りに存在する学習データの数から未知データのラベルを判断する機械学習モデルです。
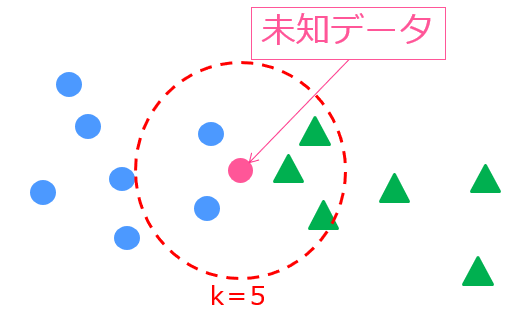
アルゴリズムはシンプルですが、ある程度精度の見込める手法です。
詳しくは以下の記事にまとめています!
後ほど紹介しますが、Rでの機械学習手法比較を行っています。

ランダムフォレスト
ランダムフォレストは、決定木とバギングを組み合わせた手法でそれなりの精度を簡単にたたき出してくれます。
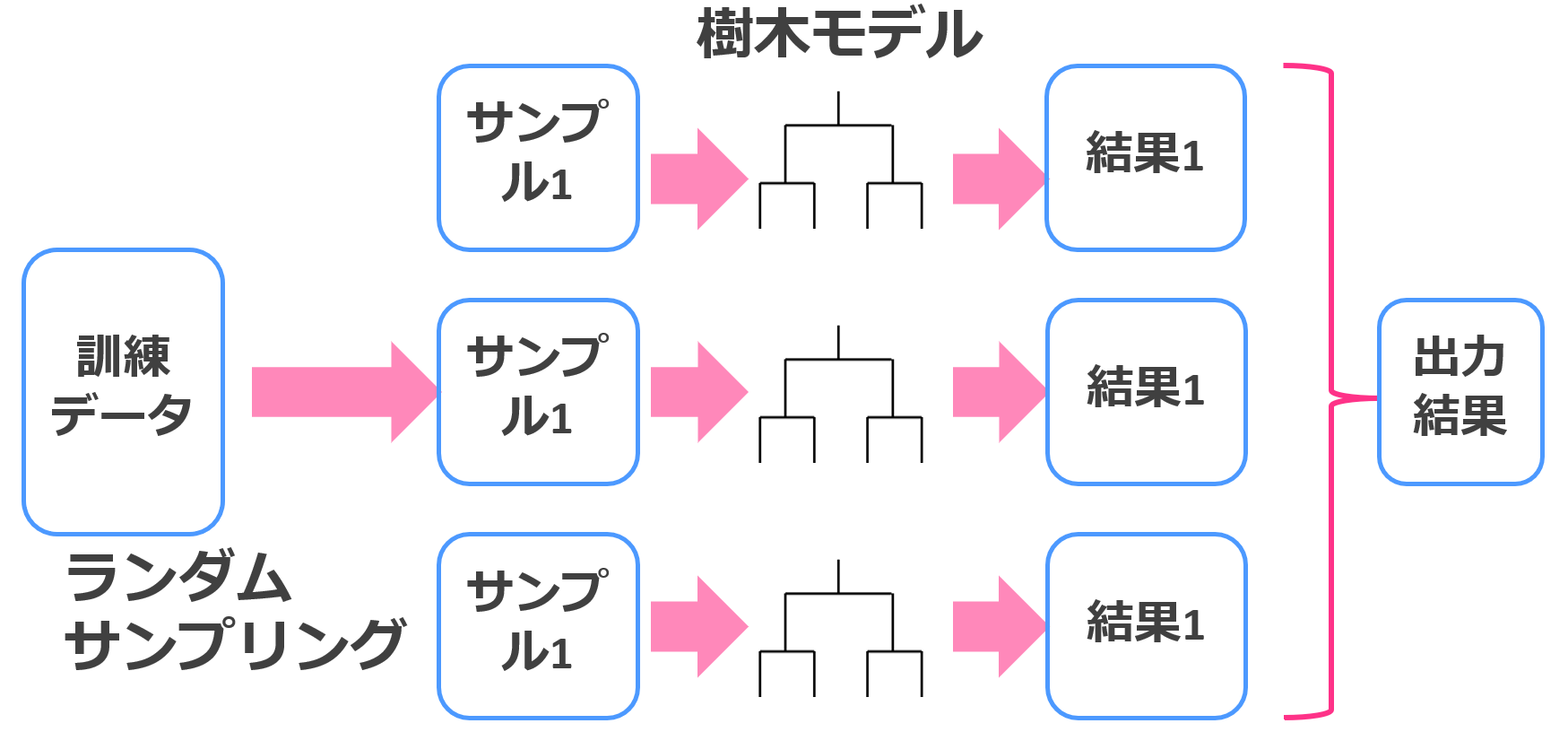
バギングは、アンサンブル学習の1つで精度を追求する際に非常によく使われるアルゴリズムです。
簡単に言うと、複数のモデルを組み合わせて最終アウトプットを決めるアルゴリズムです。
決定木のようなシンプルなアルゴリズムに対してアンサンブル学習を組み合わせるのは1つの手法として確立されています。
それほど計算負荷もかからないので、ちょっとしたデータを解析するのにはもってこいです。
決定木と同様のirisデータをPythonを使って分類できちゃいます。
ランダムフォレストに関しては以下の記事に詳しくまとめていますので参考にしてみてください。

SVM(サポートベクターマシン)
SVMもランダムフォレスト同様の精度が期待できる優秀な手法です。
サポートベクトルと呼ばれる境界付近のサンプルを使った分類とカーネル法を使った非線形化が特徴のアルゴリズムです。
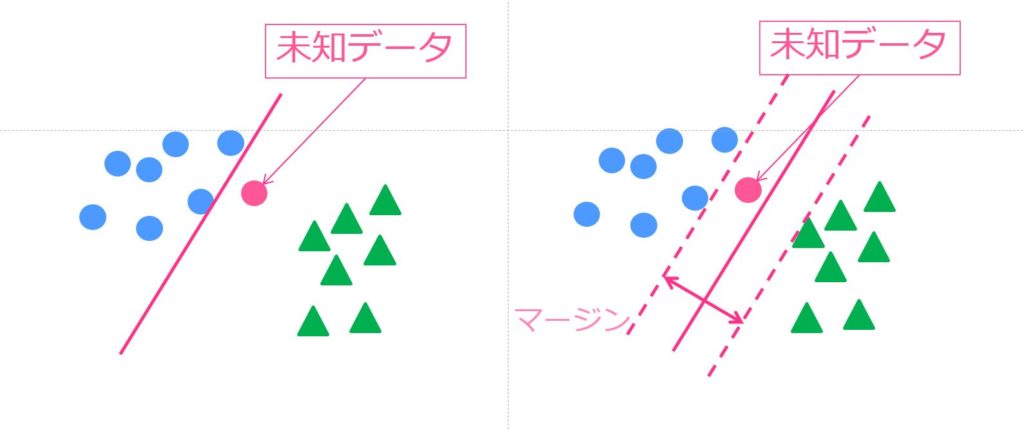
応用の幅が広く様々な分野で使われています。計算負荷は高めです。
SVMについて詳しくはこちら!

後ほどRでの実装比較を見ていきます
ニューラルネットワーク
ニューラルネットワークはディープラーニングの基となった手法です。
ニューラルネットワークでは人間の脳を模したシナプス結合をモデル化しており、層を信号が伝播して最終アウトプットが算出されます。
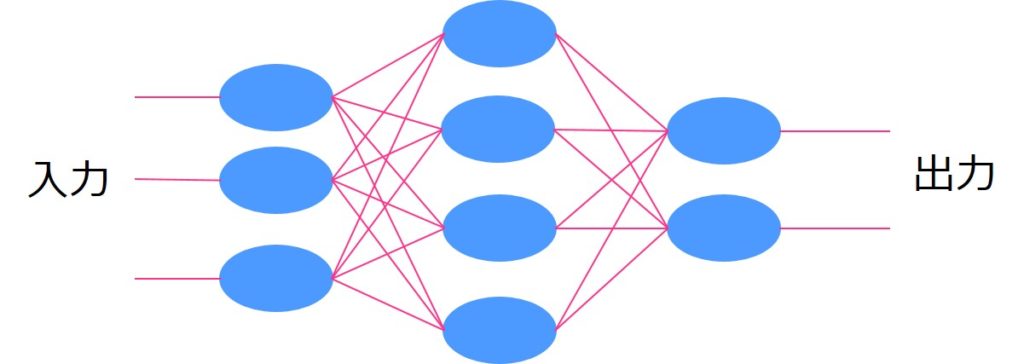
ニューラルネットワーク単体ではそれほど高い精度は見込めませんが、中間層を増やせば増やすほど学習が進み(ディープラーニングに近づき)精度が高くなります。
その分、計算負荷も上昇します。
ニューラルネットワークに関して詳しくはこちら!

ディープラーニングに関しては以下の記事を参考にしてみてください。

ナイーブベイズ
ナイーブベイズはベイズ統計学の概念を用いており、様々な分野へ応用されています。
ベイズの世界では、ある事象を基に事前確率が算出され、新たに得られたデータを基に事後確率が算出されます。
そのようにして確率分布の更新が行われていきます。
ナイーブベイズが用いられる場面として最も有名なのはスパムメールの判別ですね。
スパムメールの判別では、文章に含まれる単語に対して迷惑メールである確率を算出しベイズ推定を使って迷惑メールであるか否かを推定します
以下の記事でナイーブベイズに関してまとめています!

XGboost
XGboostは、決定木と勾配ブースティングを組み合わせた手法で相当高い精度が見込めます。
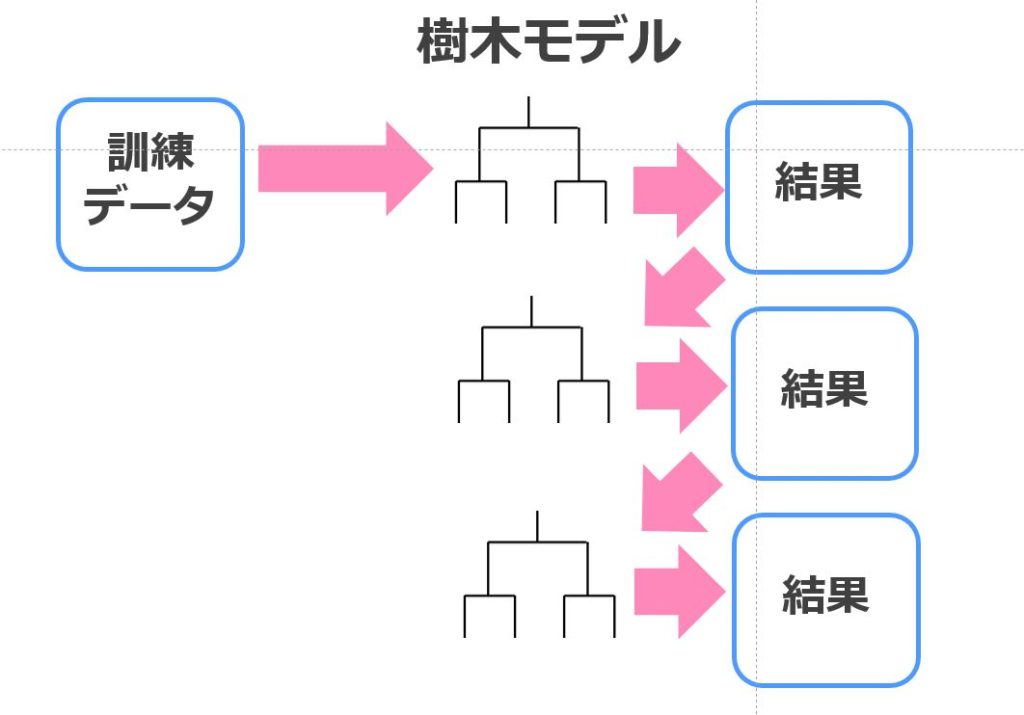
Xgboostのアルゴリズムはランダムフォレストと似ているのですが、ランダムフォレストはアンサンブル学習にバギングを用いている一方Xgboostはブースティングを用いているんです。

勾配ブースティングの手法群は、いまだに現役のデータ分析コンペ常連の手法なんですよー!
XGboostに関しては以下の記事をご覧ください!

LightGBM
Light GBMはXgboostのあと2016年にリリースされたXgboostを改良した手法です。
Xgboostを含む通常の決定木モデルのアルゴリズムでは以下のように階層を合わせて学習していきます。
それをLevel-wiseと呼びます。
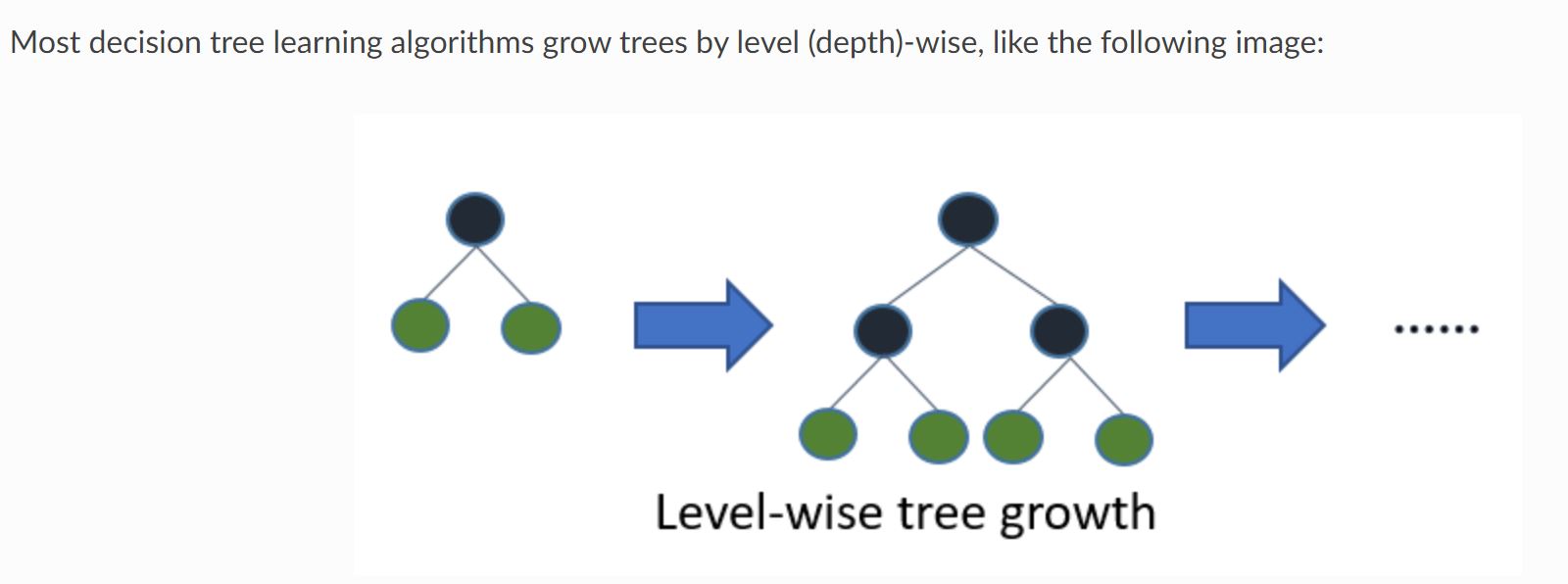
(引用元:Light GBM公式リファレンス)
一方Light GBMのアルゴリズムでは以下のように葉ごとの学習を行います。これをleaf-wise法と呼びます。
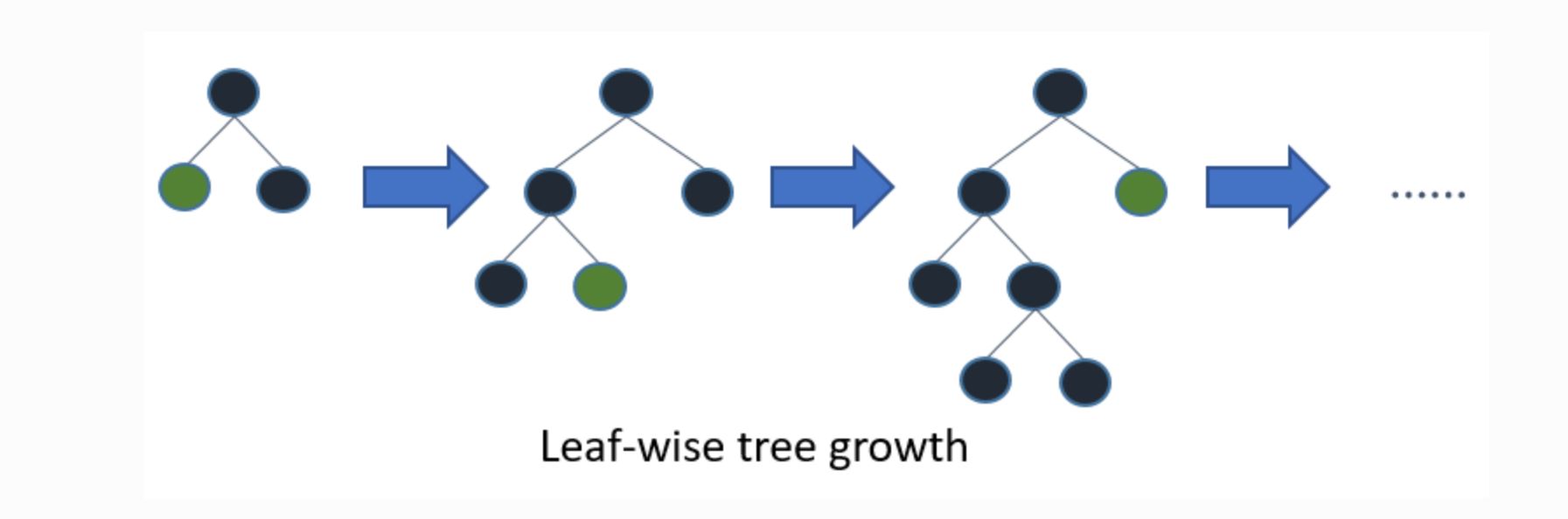
(引用元:Light GBM公式リファレンス)
これにより、ムダな学習をしなくても済むためより効率的に学習を進めることができます。
計算負荷がXgboostと全然違うので、時間の限られたコンペではLightGBMが好んで使われます。
LightGBMに関しては以下の記事で詳しくまとめています。
Catboost
さらにLight GBMよりも後に発表されたのが、Catboost。
「Category Boosting」の略であり2017年にYandex社から発表された機械学習ライブラリです。
アルゴリズムの特徴は以下。
・カテゴリカル変数(質的変数)の扱い方が上手いよ
・決定木のツリー構造を最適にして過学習を防ぐよ
・計算負荷が低いよ
実際、他の勾配ブースティング手法との違いは微妙なところ。
後ほど精度比較していきますよー!
Catboostに関しては以下の記事でまとめています!

教師なし学習
教師あり学習では、正解データが存在しましたが、教師なし学習では正解データは存在しません。
現在存在するデータから何か特徴を導き出す時・セグメントを行う時などに使われます。
教師なし学習の手法にはクラスター分析や主成分分析などが存在します。
先ほど機械学習と統計学の違いをお伝えした通り、統計学は現在のデータの解釈に使われることが多いです。
そのため、教師なし学習のクラスター分析や主成分分析は統計学的アプローチの文脈で使われることが多いです。
階層的クラスター分析
階層クラスター分析では木構造のような図を作ってクラスター分けを行います。
ある類似度を表す指標をもとにサンプルを融合していき、最終的に一つのクラスターを作るアルゴリズムを用います。
階層的クラスター分析に関しては以下の記事で詳しくまとめています!

k-means法
階層的クラスター分析は分かりやすく、結果が出た後に分類の様子からクラスタ数を決めることが可能です。
ただデータ量が多くなると計算に時間がかかるというデメリットがあります。
そこで登場するのが非階層的クラスター分析のk-means法。
どちらの手法も一長一短ですが、一般的にビジネスの場では膨大なデータを扱うことが多いため非階層的クラスター分析が良く用いられます。
先ほどから頻出のirisデータをk-means法で分類してみましょう!
以下がコードです。
3つの花のタイプに分かれているので、そのラベルがk-means法で上手く分類できるかどうか見ていきます。
実際におこなってみた結果がこちら
| 1 | 2 | 3 | |
| setosa | 0 | 50 | 0 |
| versicolor | 48 | 0 | 2 |
| virginica | 14 | 0 | 36 |
Verginicaは少し外してますが、それ以外は比較的当たってますね!
非常にシンプルなアルゴリズムで計算負荷も低くよく用いられます。
以下の記事でk-means法についてまとめています!
主成分分析
主成分分析は、1900年代前半にピアソンやホテリングにより導かれた手法であり長い歴史を持っています。
教師データ(正解データ)がいらない手法であり、手元にあるデータの次元を圧縮し構造化するのに優れています。
Pythonで主成分分析を実装していきましょう!
非常に簡単に実装することが可能です。
使用するデータは、統計科学研究所の「成績データ」。以下のURLからダウンロードできます。
https://statistics.co.jp/reference/statistical_data/statistical_data.htm
| kokugo | shakai | sugaku | rika | ongaku | bijutu | taiiku | gika | eigo |
| 30 | 43 | 51 | 63 | 60 | 66 | 37 | 44 | 20 |
| 39 | 21 | 49 | 56 | 70 | 72 | 56 | 63 | 16 |
| 29 | 30 | 23 | 57 | 69 | 76 | 33 | 54 | 6 |
| 95 | 87 | 77 | 100 | 77 | 82 | 78 | 96 | 87 |
| 70 | 71 | 78 | 67 | 72 | 82 | 46 | 63 | 44 |
| 67 | 53 | 56 | 61 | 61 | 76 | 70 | 66 | 40 |
| 29 | 26 | 44 | 52 | 37 | 68 | 33 | 43 | 13 |
9科目の点数が166人分入ってます。
主成分分析自体は、scikit-learn内のライブラリを用います。
from sklearn.decomposition import PCA
実際に第1主成分と第2主成分を軸にデータをプロットしてみるとこんな感じ
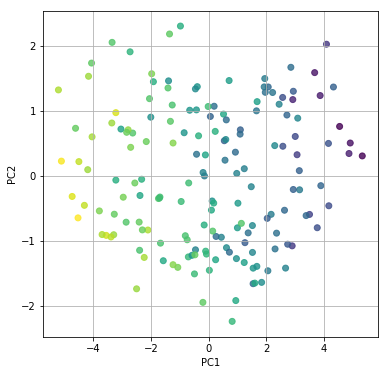
寄与率を見てみると以下のようになっており、ほぼ第2主成分までで80%を超えていることが分かります。
array([0.66738119, 0.12202057, 0.05453805, 0.04521959, 0.03336222, 0.02460657, 0.02030967, 0.01902168, 0.01354047])
主成分分析については以下の記事でまとめています!

強化学習
強化学習は、昨今最も注目を集めている分野です。
教師あり学習と似ていますが、教師あり学習は全ての変数(特徴量)に対してフィードバックがありますが、強化学習は最終的な結果にのみフィードバックをします。
それを強化学習の世界では報酬と言いますが、報酬をたくさんもらえるように最適化すると最終的に精度の高いモデルが構築されるというイメージです。
まだまだビジネスの世界への適応例は少ない手法です。
強化学習については以下の記事にまとめています!

機械学習の各種アルゴリズム・手法をRで実装してみよう!

機械学習に対する理解がだいぶ深まったと思いますので、ここで簡易的な解析をしてみましょう!
機械学習手法を使うだけなら非常に簡単に実装できちゃうんですよー!教師あり学習を実装してみましょう!
先ほども登場した有名なタイタニックのデータを用います。Kaggleの公式サイトからデータをダウンロードできます。
まず、データのクレンジングを行い、欠損値は削除、不要と考えられる項目は削除しました。
【項目8つ】
Survived:生死 pclass:客室のクラス sex:性別 age:年齢 sibsp:兄弟・配偶者の数 parch:親・子供の数 fare:乗船料金 embarked:乗船した港
【サンプル数714】
この時、生死を目的変数としそれ以外を説明変数とします。
サンプル数714のうちランダムに400個のデータを取り出し学習データとし、残りの314を予測データとします。
学習データで予測モデルを作り、予測データにあてはめ真値と予測値の判別率を精度として比較します。
シミュレーション回数は10回とし上記の手順を10回繰り返し、結果を平均したものを最終アウトプットとします。
XGboost、ランダムフォレスト、サポートベクターマシン、ナイーブベイズ、ニューラルネットワーク、k近傍法の6手法で比較します!
基本的に引数は全部デフォルトで!果たして結果はどうなるでしょうか!
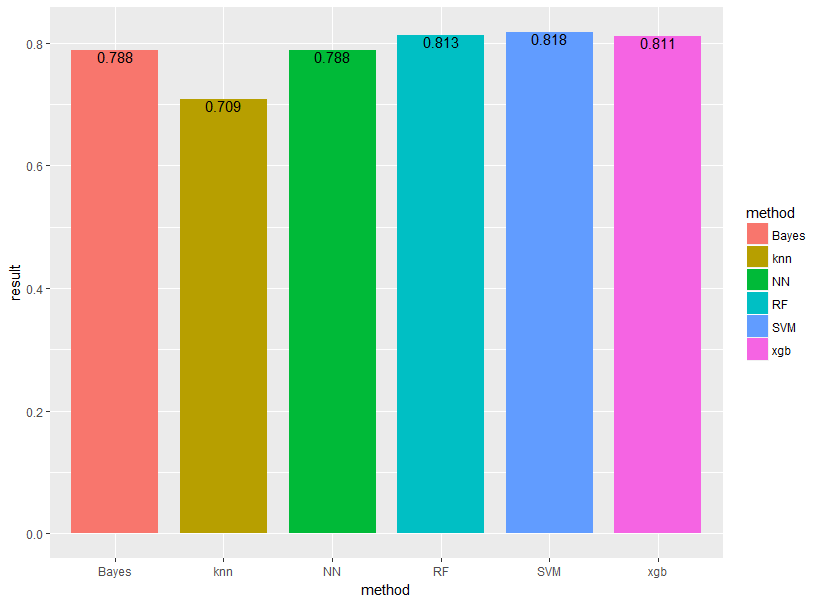
意外とランダムフォレストとSVMが強い!
シミュレーション10回なのでばらつき大きめですが、おおまかな精度の指標になるでしょう。
今回はパラメータをいじらずデフォルト設定で行ったためグリッドサーチなどでチューニングを行えば、もっと良い精度が出るでしょう。
機械学習の各種アルゴリズム・手法をPythonで実装してみよう!

続いて、Pythonで機械学習手法を実装していきましょう!
回帰タスクと分類タスクに分けて見ていきます。
回帰タスクに対して機械学習手法を実装
まずは回帰タスクに対して機械学習手法を実装していきます。
国産データコンペ Nishikaの「中古マンション価格予測」というトレーニングコンペのデータに対してLightGBMを実装してみたいと思います。
Pythonであればいとも簡単に実装することができるんです!
まず![]() Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして中古マンション価格予測のデータから学習データとテストデータをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
得られたデータを結合しデータフレームを作成し、データクレンジングをおこなった上でLight gbm を実装していきます。
全コードは以下になります!
このタスクでは評価指標がMAE(平均絶対誤差)であり、バリデーションの推定精度は
0.0764となりました!
テストデータをサブミットすることでコンペにスコアを提出することももちろん可能です。
df_test = pd.read_csv("test.csv", index_col=0)
df_test = data_pre(df_test)
predict = model.predict(df_test)
df_test["取引価格(総額)_log"] = predict
df_test[["取引価格(総額)_log"]].to_csv("submit_test.csv")以下の記事でより詳しく解説していますので是非チェックしてみてください!
また、機械学習による需要予測の解説と実際のPythonでの実装を以下の記事で行っていますのでそちらもぜひチェックしてみてください!

分類タスクに対して機械学習手法を実装
先程は価格の予想ということで、回帰タスクでしたが続いては分類タスクに対して機械学習手法を実装していきたいと思います。
使う手法は先程も使った人気の勾配ブースティング手法「Xgboost」「LightGBM」「Catboost」
使用するデータセットは画像識別のベンチマークによく使用されるMnistというデータです。
Mnistは以下のような特徴を持っています。
・0~9の手書き数字がまとめられたデータセット
・6万枚の訓練データ用(画像とラベル)
・1万枚のテストデータ用(画像とラベル)
・白「0」~黒「255」の256段階
・幅28×高さ28フィールド
ディープラーニングのパフォーマンスをカンタンに測るのによく利用されますね。
それぞれの手法のコードをざっと並べて見ていきましょう!
結果は以下のようになりました!
■Xgboost
精度:0.9764 処理時間:1410秒
■LightGBM
精度:0.972 処理時間:178秒
■Catboost
精度:0.9567 処理時間:260秒
精度はXgboostが最もよくLightGBMが最も処理が早いという結果になりましたー!
以下の記事で各手法の実装に関しては詳しく解説していますのでぜひチェックしてみてください!

ちなみに2020年にリリースされた機械学習のライブラリ「PyCaret」を使えば多くの機械学習手法を簡単に比較することが出来るので簡易的に実装したい場合をPyCaretを使ってみてください。
機械学習を勉強するのにおすすめなサービス・本

非常に幅広く、様々な手法が混在する機械学習手法について見てきましたがこれらを学習するのにおすすめなサービスや書籍を紹介していきます!
Udemy
公式サイト:https://www.udemy.com/
なかなか初心者向けの書籍がないので最初はUdemyというオンライン学習プラットフォームで学習を進めることをオススメします!
Udemyは世界最大の教育プラットフォームです。
・世界最大のオンライン学習プラットフォーム
・日本事業ではベネッセがパートナーになっている
・15万種類ものコース
・約3億人のユーザー登録
※2020年3月時点
Udemyにはいくつかの講座がありますが、機械学習が広く学べてデータ分析の実践まで行える講座としては以下の僕の講座がオススメです!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
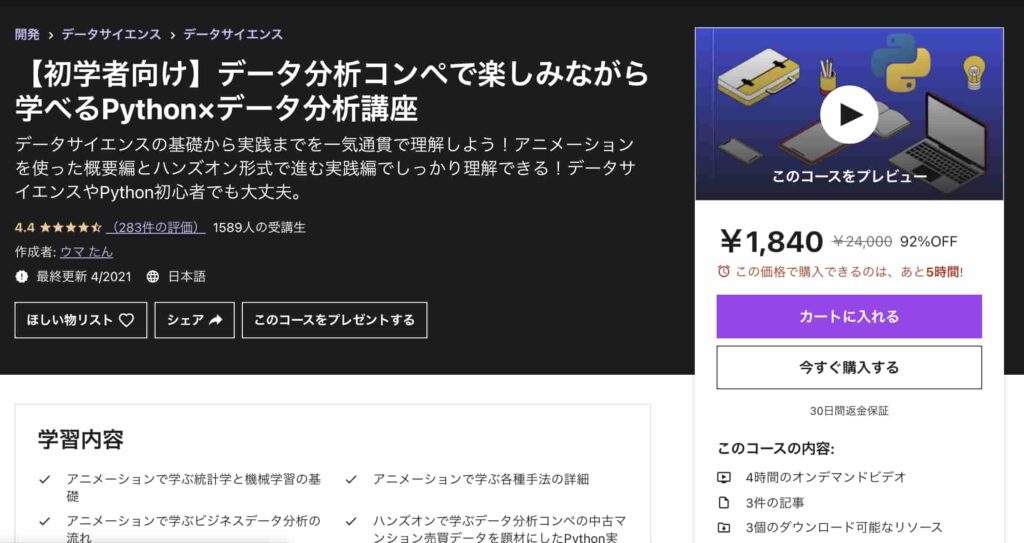
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編では体系的にデータ分析・機械学習導入の文脈でまとめています。
プログラミングスクール
プログラミングスクールは高額でなかなか手が届かないという人も多いですが、使い方によっては非常にコスパのよいサービスです。
僕自身通った経験のあるプログラミングスクールでオススメなのはテックアカデミー!
現役エンジニアのパーソナルメンターがつくので分からないところも解消しやすく書籍などで進めるよりは圧倒的に進みが早いです。
価格は3か月で284,900円!
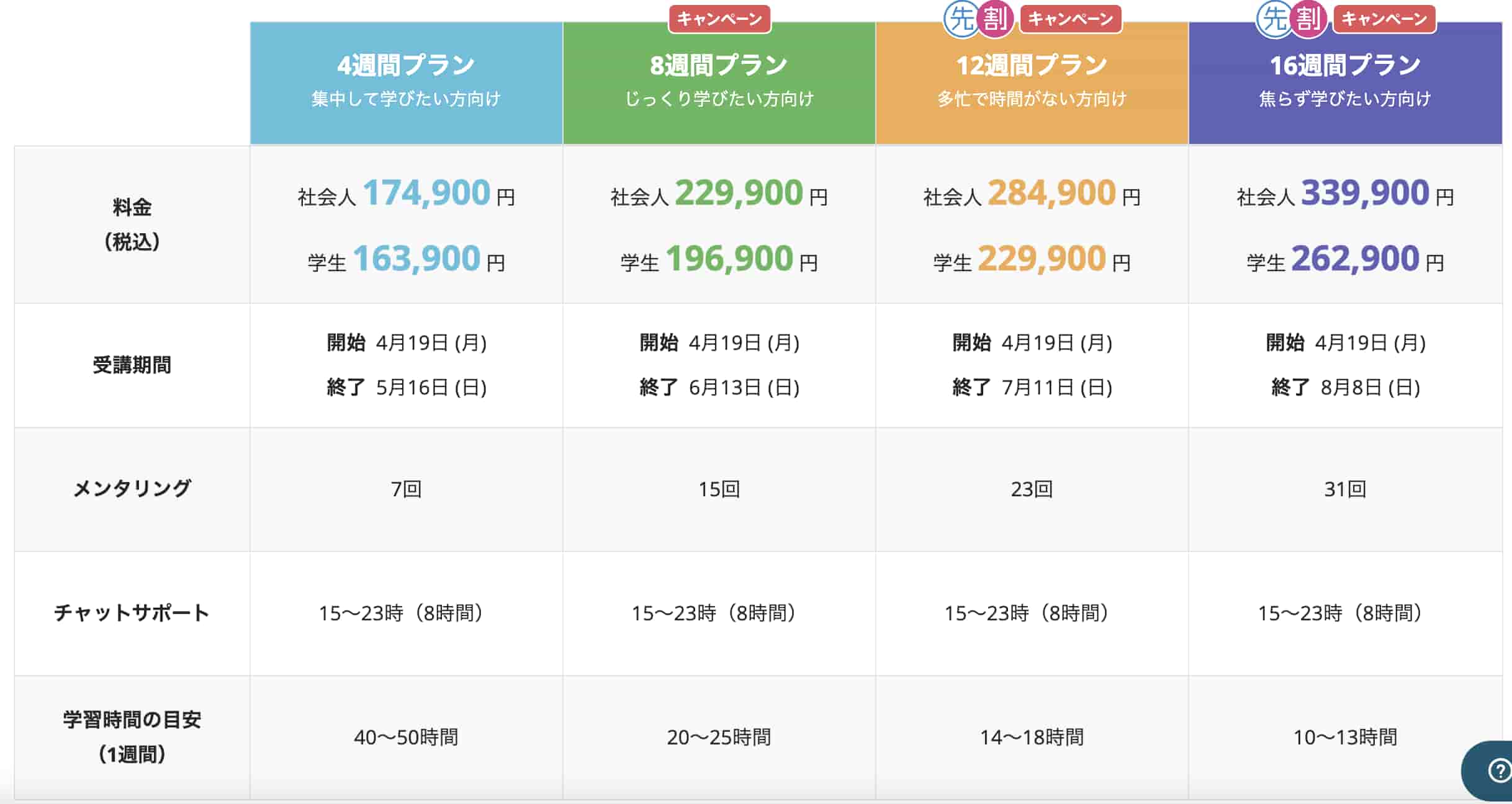
価格は少々かかりますが、その文お尻に火が付きます。
メンターのレベルは非常に高いので自分のやる気さえあれば教材の範囲を超えた内容をガツガツ学ぶことが可能!
僕自身3か月のコースを1か月で終わらせて、応用をガツガツ学んでました。
ただテックアカデミーはそれなりに高い・・・ということで・・・
作っちゃいました!業界最安級AIデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
機械学習やデータサイエンスを学べるスクールは他にもたくさんあります。
以下の記事でまとめていますのでこちらも合わせてチェックしてみてください!

データ分析コンペサービス
データ分析コンペは自分の実力を試す場としては非常に効果的です。
他の人の回答なども見ることができるので勉強にもなりますし、入賞するとお金がもらえるケースも多いのでモチベーションにもなります。
ある程度勉強したらNishikaなどのデータ分析コンペで実践を積むことをオススメします。
NishikaはKaggleよりも扱いやすい題材が取り上げられているので初心者が腕試しをするのにちょうど良いです。
今回取り上げたテーブルデータ以外にも以下のような画像データやテキストデータのトレーニングコンペがあります。
・画像データ:![]() 【トレーニングコンペ】絵巻物・絵本の画像分類
【トレーニングコンペ】絵巻物・絵本の画像分類
・テキストデータ:![]() 【トレーニングコンペ】文学:芥川龍之介
【トレーニングコンペ】文学:芥川龍之介
以下の記事でデータ分析コンペの比較していますので是非チェックしてみてください!

書籍:データ解析のための統計モデリング入門

データ解析のための統計モデリング入門は、統計学の基本的な線形モデルから徐々に拡張していってベイズモデリングまで領域を広げていきます。
統計学や機械学習領域について広く学んだ後に読むと理解が深まると思うのでぜひ呼んでみてください!
書籍:これなら分かる最適化数学

こちらの書籍は機械学習のアルゴリズムに対しての理解をもっと深めたい!理論をもう少し踏み込んで学びたい!という方におすすめな書籍です。
結構難解な内容もありますが、しっかり読めば機械学習理論の力がしっかり付くこと間違いなし!
書籍:Kaggleで勝つデータ分析の技術

機械学習を使った実践について学びたいのであればこちら!
「Kaggleで勝つデータ分析の技術」
先ほども軽く登場したKaggleというデータ分析コンペの猛者が著者で書かれている実践的なデータ分析のための書籍です。
機械学習のアルゴリズムや手法の内容よりも、どのようにデータを調理してデータ分析に活かせばよいかという話がしっかり載っている最強の書籍です!
機械学習のおすすめ本については以下の記事でも詳しくまとめていますので是非チェックしてみてください!

機械学習の勉強法については以下の記事でまとめていますので是非チェックしてみてください!

機械学習のアルゴリズムと手法 まとめ
本記事では機械学習についてみてきましたー!
機械学習は、非常に簡単に実装できます。
ただその分、機械学習が実装できるだけでは意味がありません。
どのようなデータを機械に与えて、得られた結果をどのように解釈するか。それが最も大事な部分になります。
得られた結果をどのようにビジネスに落とし込むか・ビジネスインパクトを出すか。ここがデジタルマーケター・データサイエンティストの腕の見せ所ですね!
機械学習と同時にPythonを学んだり、統計学を学んだり、ディープラーニングを学んだりしていきましょう!
ぜひ好きな方向に進んでくださいねー!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!

















