機械学習で重要な特徴量エンジニアリングとは?手法やコツを紹介!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
機械学習を使ってモデルを構築する上で、非常に重要なのが特徴量エンジニアリング。
特徴量とは、モデルにインプットする要素・変数のこと。
例えばお店の売上を予測するために気温や曜日のデータを使う場合、気温や曜日が特徴量になります。
統計学の世界では変数という言葉を使いますが、専ら機械学習界隈では特徴量と言いますね。
そんな特徴量を上手く作り出し精度を高めようとする取り組みが特徴量エンジニアリングなのです。

この記事では、そんな特徴量エンジニアリングに必要な考え方やテクニックを紹介していきます!
特徴量エンジニアリングについて詳しく学びPythonで実装していきたい方は、以下の私のUdemy講座で詳しく解説していますのでチェックしてみてください!
【初心者向け】機械学習モデル構築で重要な特徴量エンジニアリングのテクニックをPythonを使って学んでいこう!
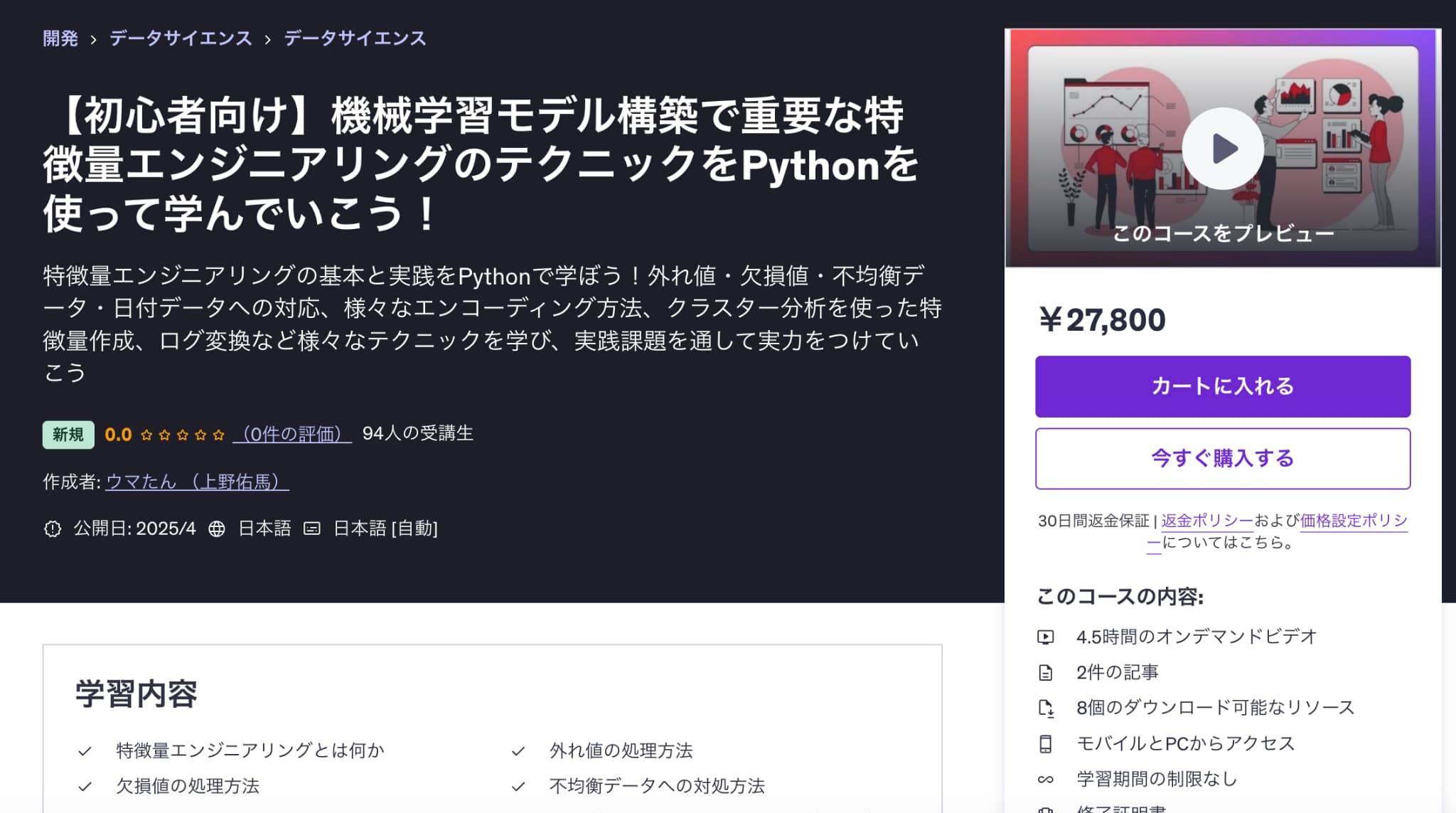
| 【時間】 | 4.5時間 |
|---|---|
| 【レベル】 | 初級 |
特徴量エンジニアリングについて学びたいならこのコース!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
特徴量エンジニアリングに必要な考え方

特徴量エンジニアリングの目的は予測精度を上げるコトであり様々なアプローチがあります。
・全く新しい特徴量を追加する
・特徴量の集計方法を変える
・特徴量を変換する
・既存の特徴量を組みあわせて新たな特徴量を作り出す
・サンプルを操作する
などなど。
特徴量エンジニアリングには、ドメイン知識が非常に重要。
ドメイン知識とは、そのデータセットの領域に関係する知識のこと。
業界や職種によってドメインは区切られます。
BtoBとBtoCの商材ではもちろん特徴量の勘所は違いますし、BtoCでも車を扱う会社と日用品を扱う会社で違うというのは理解できるでしょう。
そのドメイン特有の考え方や重要指標が存在するので、それをしっかり理解して特徴量として追加したり加工したりすることがモデルの精度を高める上で非常に重要になってきます。
自分の担当する分野にアジャストするのがコツになりますが、いくらドメイン知識があっても特徴量エンジニアリングのテクニックを知らないと筋の良いモデルは作り出せません。
いくつかある特徴量エンジニアリングについて解説していきます!
特徴量エンジニアリングのテクニック

ここでは、既存のデータを加工したり、既存の特徴量を組みあわせて新たな特徴量を作り出すテクニックを紹介します。
Kaggleなどのデータコンペでは全員に決まったデータが与えられるので、与えられたデータの中でどのような特徴量を生み出すかが肝になりますが、実務ではそもそもデータを計測するところから設計したり、他のテーブルデータから必要なデータを引っ張ってきたりすることも多いです。
特徴量エンジニアリングのテクニックを知っておくのは大事ですが、近視眼的になるのではなく広い視野で特徴量を見つけられるようにしておきましょう!
one-hot-encoding
one-hot-encodingは、統計学の世界で言うダミー変数化とほぼ同義で多クラスのカテゴリーを01ラベルで表す特徴量として展開していきます。
例えば以下のようなケースだと、
| カテゴリ |
| A |
| B |
| A |
| C |
| ・・・ |
| A |
| B |
one-hot-encodingをすることにより以下のようなデータ構造に変換されます。
| A | B |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
| 0 | 0 |
| 1 | 0 |
| 0 | 1 |
この時、Aが0でBが0であればCということが明示的に分かるのでCのカラムは必要ありません。
逆にCのカラムを追加してしまうと変数同士の重複が起き「多重共線性」という問題が生じ、推定精度が不安定になります。
Pythonでは、pandasのget_dummiesを使って簡単にone-hot-encoding化することができます。
XgboostやLightgbmなど決定木モデルの場合は、one-hot-encoding化を行わずそのままカテゴリでデータをインプットしても問題ないのですが、それ以外の学習器を使用する場合はone-hot-encoding化が必要です。
Feature hashing
one-hot-encodingでは、10の水準を持つカテゴリの場合、新たな特徴量が9つ生成されることになります。
つまり水準が多ければ多いほど特徴量が増え高次元になっていき計算が不安定になる可能性が考えられます。
そこで行われるのがこのFeature hashingです。
Feature hashingでは、複数の水準を1つのカラムで表現します。
例えば
| カテゴリ |
| A |
| B |
| D |
| C |
| ・・・ |
| A |
| B |
の場合Feature hashingを使うと例えば以下のようになります。
| AかつC | B |
| 1 | 0 |
| 0 | 1 |
| 0 | 0 |
| 1 | 0 |
| 1 | 0 |
| 0 | 1 |
これにより特徴量が増えすぎるのを防ぐことができます。
Frequency encoding
各水準の出現回数でカテゴリ変数を置き換えます。
例えば以下のような特徴量は、
| カテゴリ |
| A |
| A |
| C |
| C |
| A |
| A |
| B |
は以下のように変換できます。
| カテゴリ |
| 4 |
| 4 |
| 2 |
| 2 |
| 4 |
| 4 |
| 1 |
target encoding
目的変数の情報を使ってカテゴリ変数を置き換える方法です。
| カテゴリ | 目的変数 |
| A | 1 |
| A | 1 |
| C | 0 |
| C | 1 |
| A | 0 |
| A | 1 |
| B | 0 |
この場合、それぞれの平均を取って以下のように変換できます。
A=(目的変数の総計が3)/4=0.75
B=(目的変数の総計が0)/1=0
B=(目的変数の総計が1)/2=0.5
| カテゴリ | 目的変数 |
| 0.75 | 1 |
| 0.75 | 1 |
| 0.5 | 0 |
| 0.5 | 1 |
| 0.75 | 0 |
| 0.75 | 1 |
| 0 | 0 |
ただ、この場合目的変数の情報を特徴量に用いることになるので、リーク(知らないはずのデータを情報として取り入れてしまい予測精度の悪化を招くこ)に気を付けなくてはいけません。
以下の書籍に詳しいので詳しく知りたい方は、ぜひチェックしてみてください!

日付の処理
インプットするデータが時系列データの場合は日付の処理が非常に重要です。
一口に日付と言っても本当に様々なデータの処理が可能なのです。
例えば、テーブルに日付データが2021-03-31と入っていたとしましょう。
この日付データを年月日、そして曜日データにブレイクダウンするのは最初に思いつく変換方法です。
他にも月の中での上旬・中旬・下旬に分けて特徴量に追加したり、季節ごとに分けて特徴量に追加したりすることも考えられます。
また、日付データを他の特徴量と組みあわせて様々な粒度の特徴量を生成することが可能です。
例えば、2021-03-31の売上を予測する上で過去30日の訪問回数や売上を集計して特徴量にしたり過去7日ログデータを集計して特徴量にしたり、など集計する期間を変えることで様々な期間の特徴量を生成することが可能です。
クラスタリングで特徴量作成
実は大学時代に研究でクラスタリングで特徴量を生成して精度を高めるという研究をしていたことがあるのですが、この方法も精度を高めるのに有効です。

複数ある説明変数をクラスタリングにかけて、新たなカテゴリを生成しそれを新たな説明変数として加えることで精度が上がるコトがあります。
クラスタ中心からの距離を特徴量とするテクニックもデータセットによっては有効になります。
主成分分析で次元圧縮
主成分分析とは、複数の特徴量を圧縮して少なくする手法です。

精度を追い求める場面ではそれほど使われることはありませんが、あまりにも特徴量の多い高次元データには有用です。
既存の特徴量から演算で特徴量作成
複数の変数の特徴量を組みあわせて新たな特徴量を生成する方法も有用の時があります。
例えば、顧客別の購入金額と購入件数があった時にそれらを除算して購入単価という変数を作ることで精度が上がる場合があります。
モデル構築時の過程で、このような効果も加味してくれますが、明示的に特徴量を生成した方がよいことが多いです。
欠損値の処理
欠損値(欠測値)の処理も重要な特徴量エンジニアリングの1つです。
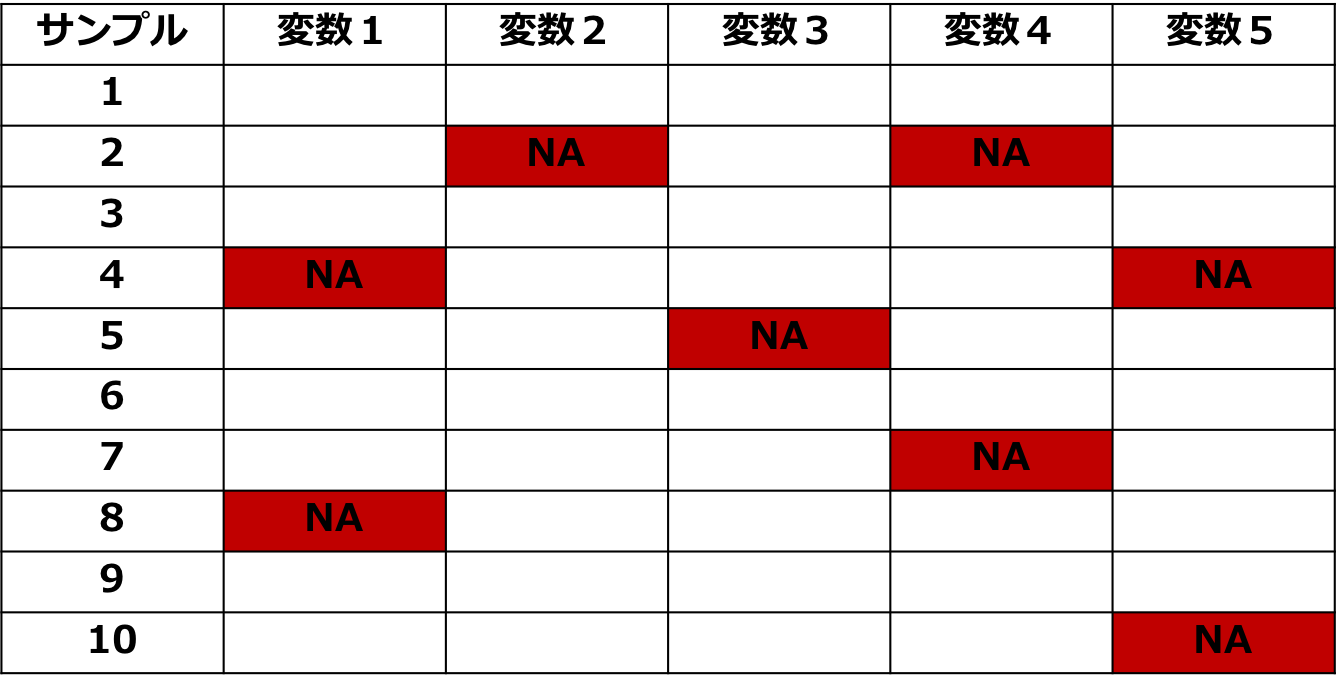
Xgboostなどの決定木モデルでは、欠損値を含んでいてもそのまま学習データとしてインプットが可能なので特別な処理をせずそのまま使うことが多いですが、他の手法を使用する場合は欠損値の処理が必要です。
欠損値の処理には、
・代表的な値で補完する
・欠損値そのものを目的変数にして予測補完する
などがあります。
ちなみに欠損値が生じる原因によってタイプが分かれており、
によって対応が変わってきます。

スタッキング
機械学習における定番手法であるアンサンブル学習。
データコンペティションのKaggleでもよく使われるXgboostやLightgbmもアンサンブル学習を使っています。
そんなアンサンブル学習の1つであるスタッキング!
スタッキングはアンサンブル学習ですが、新たな特徴量を作る方法でもあります。
僕自身普段スタッキングは使わないのですが、簡単に説明します。
Step1:いくつかのFold(グループ)にデータを分けて、それぞれを各モデルで予測する(いわゆるクロスバリデーションを色んなモデルでやる)
Step2:それぞれの予測値を新たな特徴量とする
Step3:何回か繰り返して最終アウトプット算出
アンサンブル学習のついては以下の記事でまとめています!

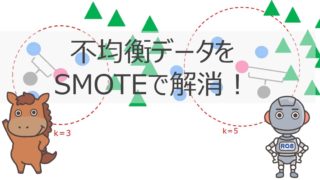
アンダーサンプリング
実データを扱っていると度々現れるのが不均衡データ!
不均衡データとはデータの比率に偏りがあるもの。
金融取引の不正利用データやメールのCVデータなど、母数が大量にありその中で該当する正例が非常に少ないケースはよくあります。
アンダーサンプリングは、そのような不均衡データに対して「少数派のデータ群にあわせて多数派のデータ群を削除する」という方法です。
オーバーサンプリング
オーバーサンプリングはアンダーサンプリングとは違い、逆に「少数派のデータを多数派にあわせて増やす」という方法です。
オーバーサンプリングの中で特によく使われる手法がSMOTEと呼ばれるものです。
SMOTEは、Synthetic Minority Over-sampling TEchniqueの略でK近傍法のアルゴリズムを利用して少数派のサンプルを増やしていきます。
不均衡データに関しては以下の記事でまとめています!
特徴量同士の組み合わせで特徴量作成
その他にも特徴量同士を組み合わせることで新しい特徴量を作成するアプローチもあります。
たとえば、商品のサイズとカラーという質的な特徴量があった時にそれらを組みあわせてサイズ×カラーという組み合わせの特徴量を作成して精度を向上させることが可能です。
特徴量エンジニアリングを学ぶのにオススメな本・サービス
特徴量エンジニアリングを学ぶためにはどうすればよいか見ていきましょう!
Kaggleで勝つデータ分析の技術
特徴量エンジニアリングを学ぶのにオススメな本がこれ!
Kaggleで使用される特徴量エンジニアリングについて分かりやすく解説してくれます。
Kaggleでの具体例を出しながら、どのようなデータでどのようなテクニックが有効だったのか非常に分かりやすく学べるのでめちゃくちゃオススメです!
Kaggleはやらない人でも、実務で役立つエッセンスが詰まっていますよー!
ぜひ手に取って読んでみましょう!
Udemy
Udemyというサービスでは、世界中の講師が素晴らしい講座を公開しています。
僕自身もコースを公開していて特徴量エンジニアリングについて分かりやすく学べる講座にしているので興味のある方は是非受講してみてください!
【初心者向け】機械学習モデル構築で重要な特徴量エンジニアリングのテクニックをPythonを使って学んでいこう!
| 【時間】 | 4.5時間 |
|---|---|
| 【レベル】 | 初級 |
特徴量エンジニアリングについて学びたいならこのコース!
今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
Udemyについて詳しく知りたい方は以下の記事を参考にしてみてください!
スタアカ(スタビジアカデミー)
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる1週間に1回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
特徴量エンジニアリングについても実践的なカリキュラムとともに手を動かしながら学んでいきます。
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
特徴量エンジニアリング まとめ
本記事では、特徴量エンジニアリングについて解説してきました!
機械学習の手法自体は誰でも簡単に実装できますが、同じ機械学習手法でもそこにどのような特徴量をインプットするかで得られる結果は全く違います。
それゆえ、良いモデルを作るために特徴量エンジニアリングがめちゃくちゃ大事なんです!
最後にここで紹介してきた特徴量エンジニアリングのテクニックを再度まとめておきましょう!
機械学習・データサイエンス・Pythonなどの勉強法については以下の記事で詳しく解説していますのであわせてチェックしてみてください!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!