
多重共線性についてわかりやすく解説!定義とVIFとその基準について詳しく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回は多重共線性について解説していきます!
多重共線性とは「説明変数のある変数同士が強く相関している状態が複数起きている状態」と定義されています。
多重共線性がある場合、重回帰分析を適用することが難しく、目的変数に対して有意に影響を与える変数が増える、あるいは見逃す可能性があるので、データ分析においては対応しなければならない要素です。
この記事では、多重共線性の定義とそれを見分けるVIFについて解説します!
・多重共線性について解説!
・VIFについて解説!
多重共線性について解説!

早速、多重共線性について解説します!
多重共線性とは「説明変数のある変数同士が強く相関している状態が複数起きている状態」と定義されています。
多重共線性の問題点として、相関が高い説明変数があると目的変数に有意に影響する説明変数が増える、あるいは見逃してしまうことです。
例を見てみましょう!これは年齢・年収・足の遅さについて疑似相関があるか見たものです。
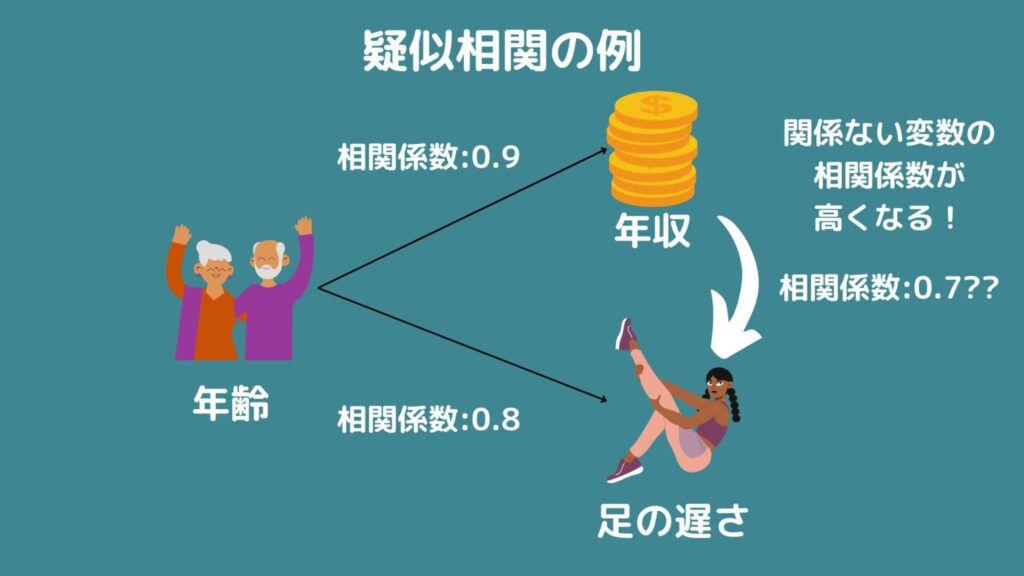
目的変数が年収、説明変数が年齢と足の遅さとしましょう。
この時、足の遅さと年齢は相関係数が高い状態、つまり多重共線性があると考えます。
そして年齢と年収は高い相関にあることも考えられますが、疑似相関により年収と足の遅さにも高い相関が生まれてしまいます。
したがって足の遅さは本来全く関係がないはずなのに、相関係数が高く見えてしまっているので、有意な変数として選択される可能性が非常に高いです。
疑似相関については以下の記事で解説しています!

このように、本来関係ない変数までも有意な変数として取り込んでしまう可能性が高いので注意する必要があります。
VIFについて解説!Pythonを使ってみてみよう!

そこで多重共線性を見分ける指標としてVIFが挙げられます。VIFは以下のような式で表せます。
\(VIF = \frac{1}{1-R_{j}}\)
\(R_{j}\)は説明変数jを他の全ての説明変数に回帰したときの決定係数となります。つまりある変数がほかの変数で説明できるのなら、その変数は不要であると考えることができます。
決定係数は以下の記事で記事で解説していますので合わせてチェックしてみてください!

多重共線性の基準として、VIFが10以上であれば多重共線性があると考えられています。またVIFが5以下であれば多重共線性を持っている可能性は非常に低いと考えられています。
実際にpythonを用いてカルフォルニアの住宅価格データからVIFを見てみましょう!
VIFを見るために、statsmodels.stats.outliner_influenceのvariance_inflation_factor関数を使用してみます!
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.datasets import fetch_california_housing
import pandas as pd
import numpy as np
df = fetch_california_housing()
x = pd.DataFrame(df.data,columns=df.feature_names)
vif = pd.DataFrame()
vif["VIF"] = [variance_inflation_factor(x.values, i) for i in range(x.shape[1])]
vif.index = x.columns
vif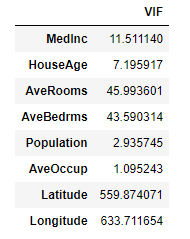
これを見るとVIFが高い変数がいくつかあることが分かりますね!実際に相関係数がどうなっているかヒートマップで見てみましょう!
import seaborn as sns
sns.heatmap(x.corr())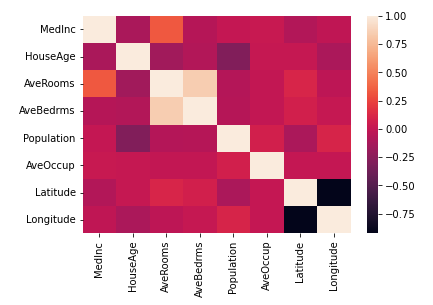
今回は比較的相関係数が高いAveRoomsとAveBedrmsに注目し、AveBedrmsを削除した場合のVIFを見てみましょう!
del x["AveBedrms"]
vif = pd.DataFrame()
vif["VIF"] = [variance_inflation_factor(x.values, i) for i in range(x.shape[1])]
vif.index = x.columns
vif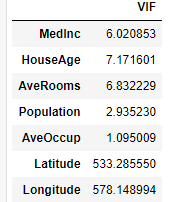
これでAveRoomsのVIFが10以下になり、先ほどのデータより多重共線性が低い状態になったことが分かりますね!
多重共線性 まとめ

ここまでご覧いただきありがとうございました!
本記事では多重共線性についてまとめました!
多重共線性が関わってくる手法として回帰分析が挙げられますので、こちらの記事も見ると良いでしょう!

このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















