
母集団と標本の違いについて解説!標本の抽出方法もわかりやすく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回は母集団と標本について解説していきます!母集団とは「本来知りたいと考えている集団全体」であり、標本は「母集団から抽出した一部」を意味します。
例えば日本人全員の身長が知りたいと考えます。そして母集団は日本人1.2億人と考えたとき、全員の身長を調べるのは時間的・金銭的なコストが莫大になることは想像できます。
そこで一部の日本人の身長を調べて日本人全員の身長を推定することで、莫大なコストを省けるメリットが考えられます。このような考え方に基づいた統計学を「推測統計学」と呼びます。

この記事では、母集団と標本について解説しつつ、標本の抽出方法について解説します!
・母平均と標本の定義について解説!
・標本の抽出方法について解説!
母集団と標本に関しては以下の動画でも解説していますのであわせてチェックしてみてください!
統計学の用語やその他のAI用語を一挙にまとめた以下の記事も合わせて要チェックです!

母集団と標本の違いについて解説!
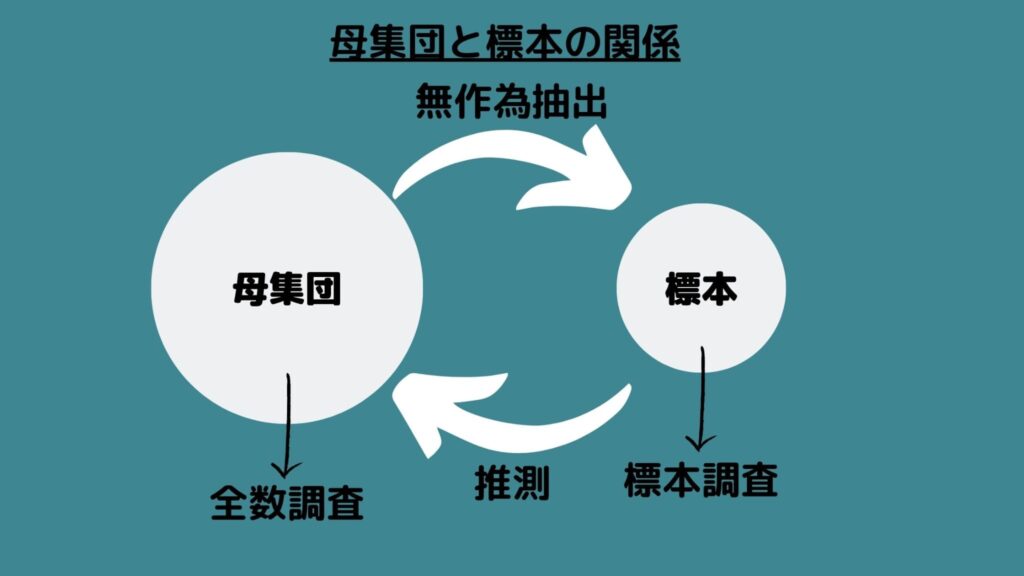
早速、母集団と標本の違いについて解説します!
母集団は「本来知りたいと考えている集団全体」であり、標本は「母集団から抽出した一部」を意味します。
例えば日本人全員の身長を知りたいと考えます。この時日本人全員を調べる方法を「全数調査」、一部の日本人を調べることを「標本調査」と呼びます。一般的には標本調査が行われることがほとんどです。
しかし前述したとおり、標本の性質が偏っていれば推測する母集団の性質も偏ってしまいます。例えば小学生1000人を標本として抽出して、母集団(日本人全員の身長)の平均値は120cmだ!と言っても説得力がありませんよね?
したがって完全にランダムに標本を抽出する必要があります。つまり小学生だけでなく、様々な年代の人を抽出して母集団の性質を推測すれば正確に出せると考えます。このような抽出方法を「単純無作為抽出」と呼ばれています。
標本の抽出方法について解説!

標本の抽出方法はいくつかありますが、その中でも代表的な抽出方法について解説していきます!
これらの抽出方法は目的にあわせて行うことで大きな効果を発揮するので、必ず中身とメリット・デメリットを把握しておきましょう!
層化抽出法
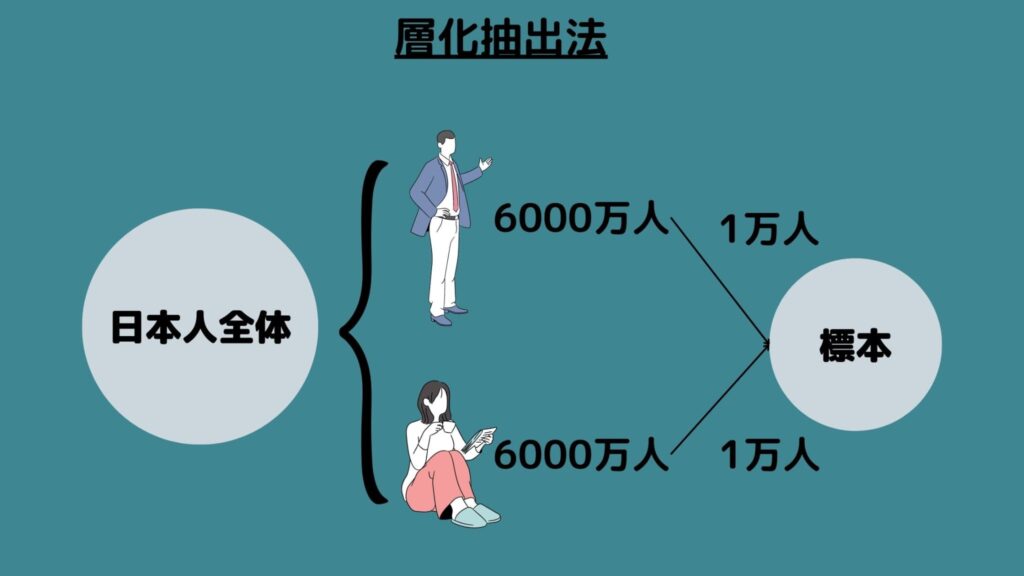
層化抽出法は「母集団をいくつかの層に分けて、それぞれの層から必要な数だけ抽出する方法」を意味します。
例えば日本人全員の身長を知りたいとき、男性と女性から半分ずつ無作為に抽出する場合を指します。
この方法は母集団の性質を正確に反映させやすく、層ごとの比較が行えますが、事前に母集団の構造を理解しておく必要があります。
集落抽出法
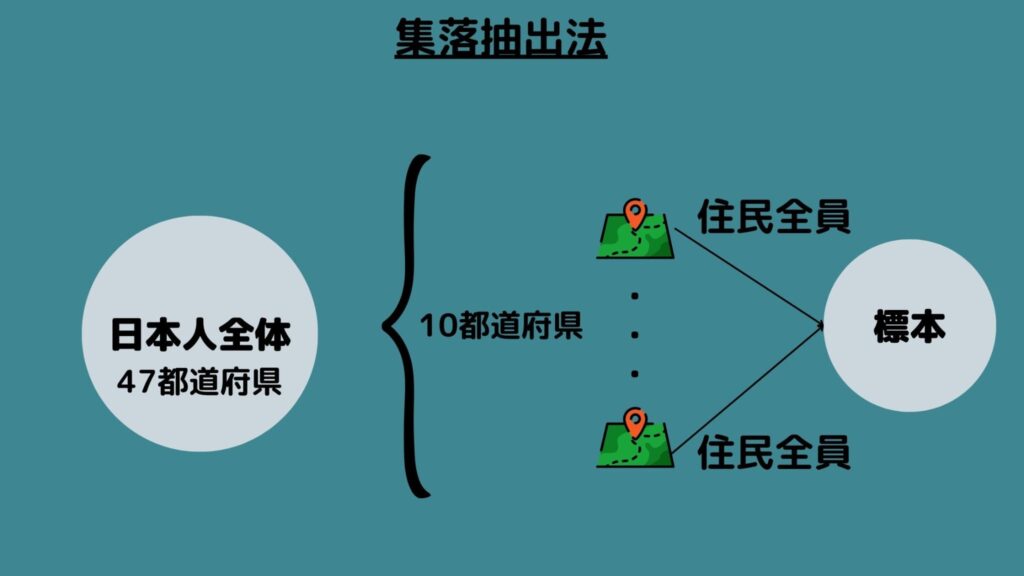
集落抽出法とは「母集団をいくつかの集落(クラスター)に分け、複数の集落を無作為に抽出し、それぞれの集落で全数調査を行う」方法です。
例えば日本人全員の身長を知りたいとき、都道府県を集落とみなし、都道府県からいくつかランダムに抽出した後、抽出した集落に所属する日本人全員を調べる場合を指します。
この方法はクラスターの情報を知っていればコストを削減できますが、クラスターそのものに偏りがある場合は標本に偏りが発生する可能性がある点に注意する必要があります。
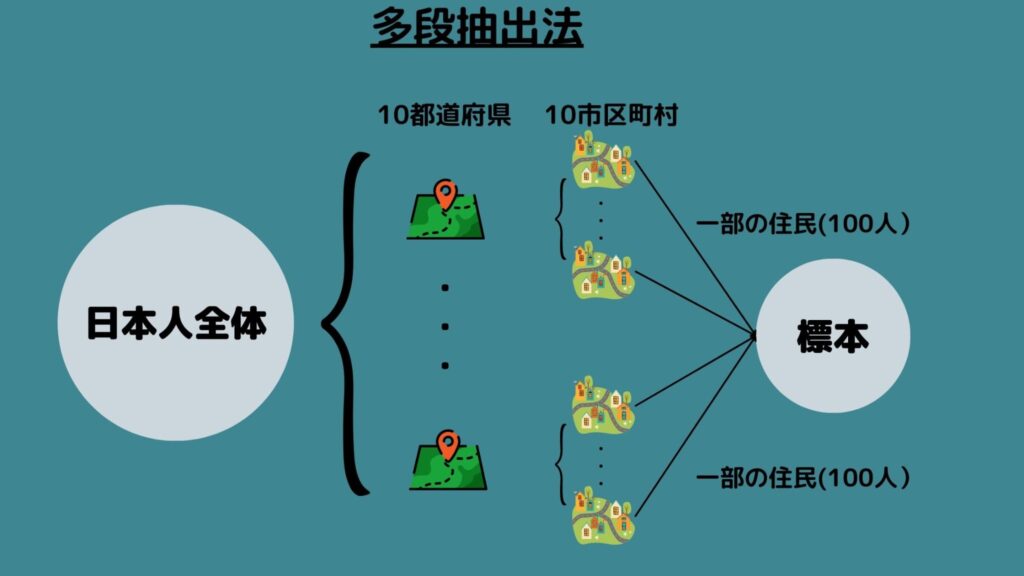
多段抽出法
多段抽出法とは「母集団をいくつかのグループに分け、その中から無作為にグループを抽出することを繰り返し、最終的なグループから無作為抽出する」方法です。
例えば日本人全員の身長を知りたいとき、まず母集団を都道府県に分けて複数の都道府県を無作為に抽出します!次に抽出した都道府県から複数の市区町村を無作為に抽出し、さらに抽出した市区町村から日本人を無作為に抽出する場合を指します。
この方法はコストが抑えられて推測した時の精度が高い一方、サンプルサイズが小さいと標本に偏りが出る点に注意しましょう!
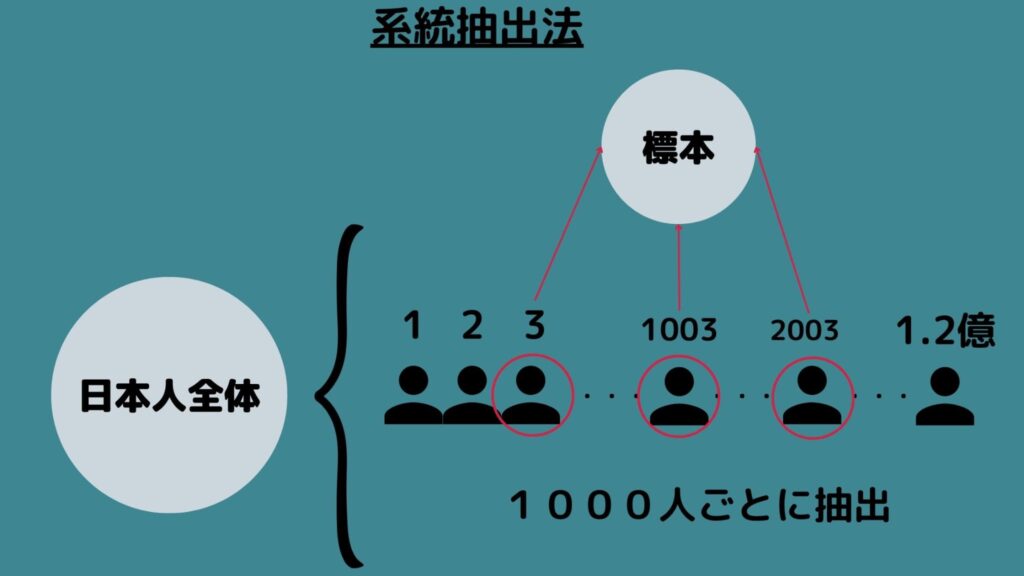
系統抽出法
最後に系統抽出法とは「通し番号を付けた名簿を作成して、1番目を無作為に選び、その後は一定の間隔で抽出する」方法です!
例えば日本人全員の身長を知りたいとき、1.2億人の通し番号を付けた名簿を作成し、ランダムに選ばれた番号から、1000人おきに抽出する場合を指します。
この方法もコストが抑えられる一方、通し番号に何らの周期があった場合は標本が偏る場合があるので注意が必要です!
母集団と標本 まとめ

本記事では母集団と標本についてまとめました!
母集団の性質として平均と分散が挙げられます!当サイトスタビジではどちらもわかりやすく解説しているので、ぜひ学んでいってください!


このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















