勾配ブースティング決定木の手法をPythonで実装して比較していく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
Xgboostに代わる手法としてLightGBMが登場し、さらにCatboostという手法が2017年に登場いたしました。
これらは弱学習器である決定木を勾配ブースティングによりアンサンブル学習した非常に強力な機械学習手法群。
勾配ブースティングの仲間としてくくられることが多いです。
計算負荷もそれほど重くなく非常に高い精度が期待できるため、Kaggleなどのデータ分析コンペや実務シーンなど様々な場面で頻繁に使用されているのです。

この記事では、そんな最強の手法である「勾配ブースティング」について見ていきます!
勾配ブースティングの代表的な手法である「Xgboost」「LightGBM」「Catboost」をPythonで実装し、それぞれの精度と計算負荷時間を比較していきます!

目次
勾配ブースティングとは
詳細の数式は他のサイトに譲るとして、この記事では概念的に勾配ブースティングが理解できるように解説していきます。
動画でも勾配ブースティング手法のXGBoostやLightGBMについて解説していますのであわせてチェックしてみてください!
まず、勾配ブースティングは「勾配+ブースティング」に分解できます。
まずは、ブースティングから見ていきましょう!
機械学習手法には単体で強力な精度をたたき出す「強学習器(SVMとか)」と単体だと弱い「弱学習器(決定木とか)」あります。

弱学習器単体だと、予測精度の悪い結果になってしまいますが複数組みあわせて使うことで強力な予測精度を出力するのです。
それをアンサンブル学習と言います。
そしてアンサンブル学習には大きく分けて2つの方法「バギング」「ブースティング」があります(スタッキングという手法もありますがここではおいておきましょう)。
バギングは並列に弱学習器を使って多数決を取るイメージ。
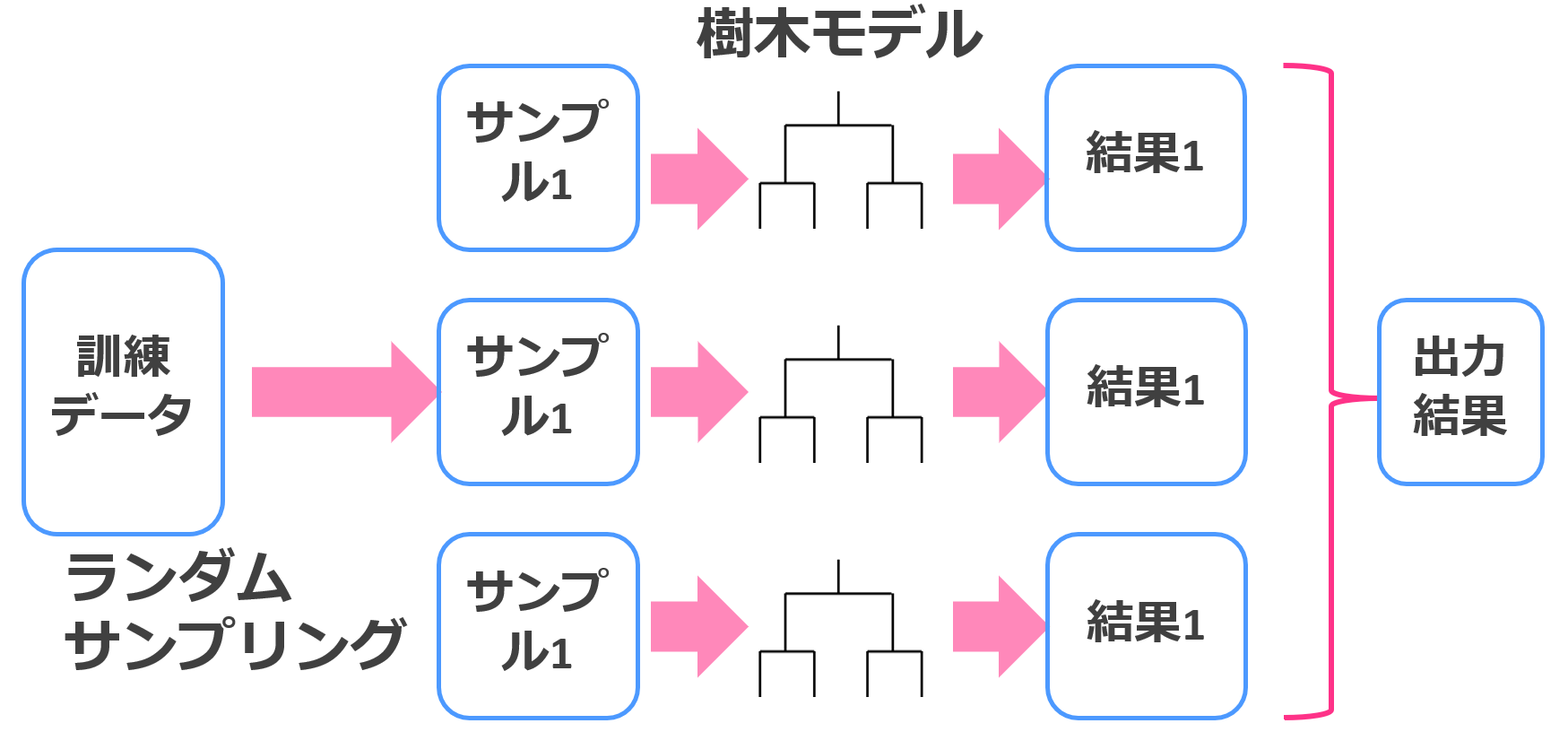
バギング×決定木はランダムフォレストという手法で、こちらも非常に強力な機械学習手法です。
一方、ブースティングとは前の弱学習器が上手く識別できなった部分を重点的に次の弱学習器が学習する直列型のリレーモデル。
以下のようなイメージです。
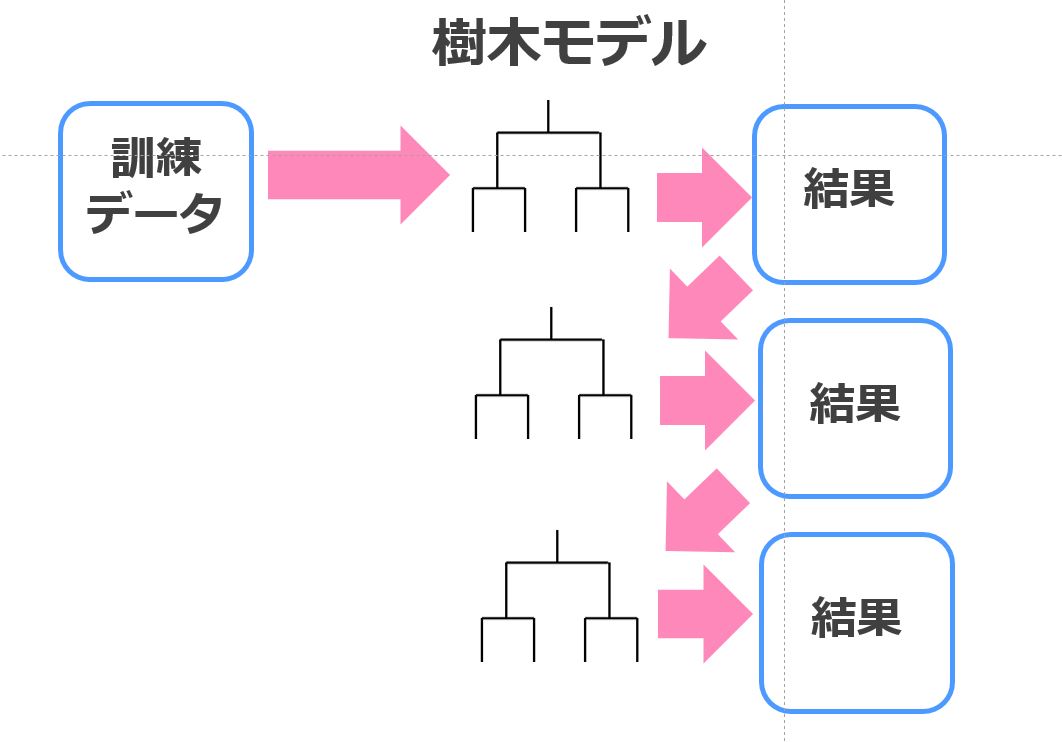
そして、「Xgboost」「LightGBM」「Catboost」はどれもブースティング×決定木との組み合わせなんです。
続いて勾配とは何を示しているのか。
ブースティングを行う際に損失関数というものを定義してなるべく損失が少なくなるようなモデルを構築するのですが、その時使う方法が勾配降下法。
そのため勾配ブースティングと呼ばれているんです。
最適化手法にはいくつか種類がありますが、もし興味のある方は以下の書籍が非常におすすめなのでぜひチェックしてみてください!

勾配ブースティングをPythonで実装
勾配ブースティングについてなんとなーくイメージはつかめたでしょうか?
それでは実際に勾配ブースティング手法をPythonで実装して比較していきます!
使用するデータセットは画像識別のベンチマークによく使用されるMnistというデータです。
Mnistは以下のような特徴を持っています。
・0~9の手書き数字がまとめられたデータセット
・6万枚の訓練データ用(画像とラベル)
・1万枚のテストデータ用(画像とラベル)
・白「0」~黒「255」の256段階
・幅28×高さ28フィールド
ディープラーニングのパフォーマンスをカンタンに測るのによく利用されますね。
Xgboost
さて、まずはXgboost。
Xgboostは今回比較する勾配ブースティング手法の中でもっとも古い手法です。
基本的にこの後に登場するLightGBMもCatboostもXgboostをもとにして改良を重ねた手法になっています。
どのモデルもIteration=100, eary-stopping=10で比較していきましょう!
結果は・・・以下のようになりました。
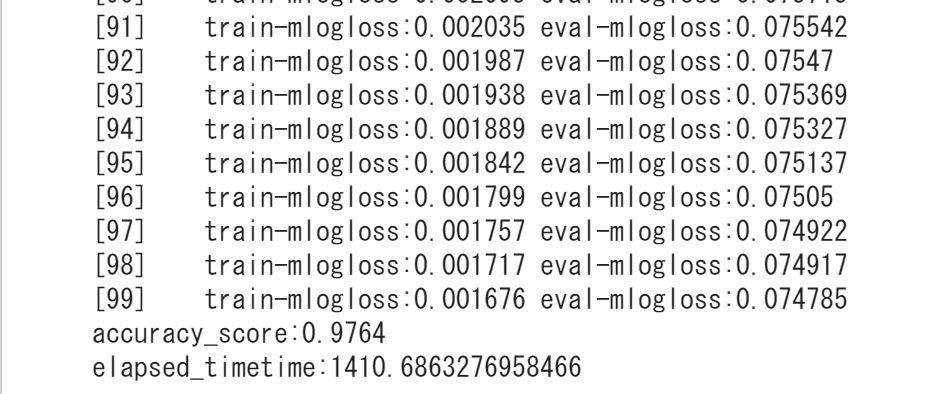
0.9764は普通に高い精度!!
ただ、学習時間は1410秒なので20分以上かかってます
Xgboostについては以下の記事で詳しくまとめていますのでこちらもチェックしてみてください!

Light gbm
続いて、LightGBM!
LightGBMはXgboostよりも高速に結果を算出することにできる手法!
Xgboostを含む通常の決定木モデルは以下のように階層をあわせて学習していきます。
それをLevel-wiseと呼びます。
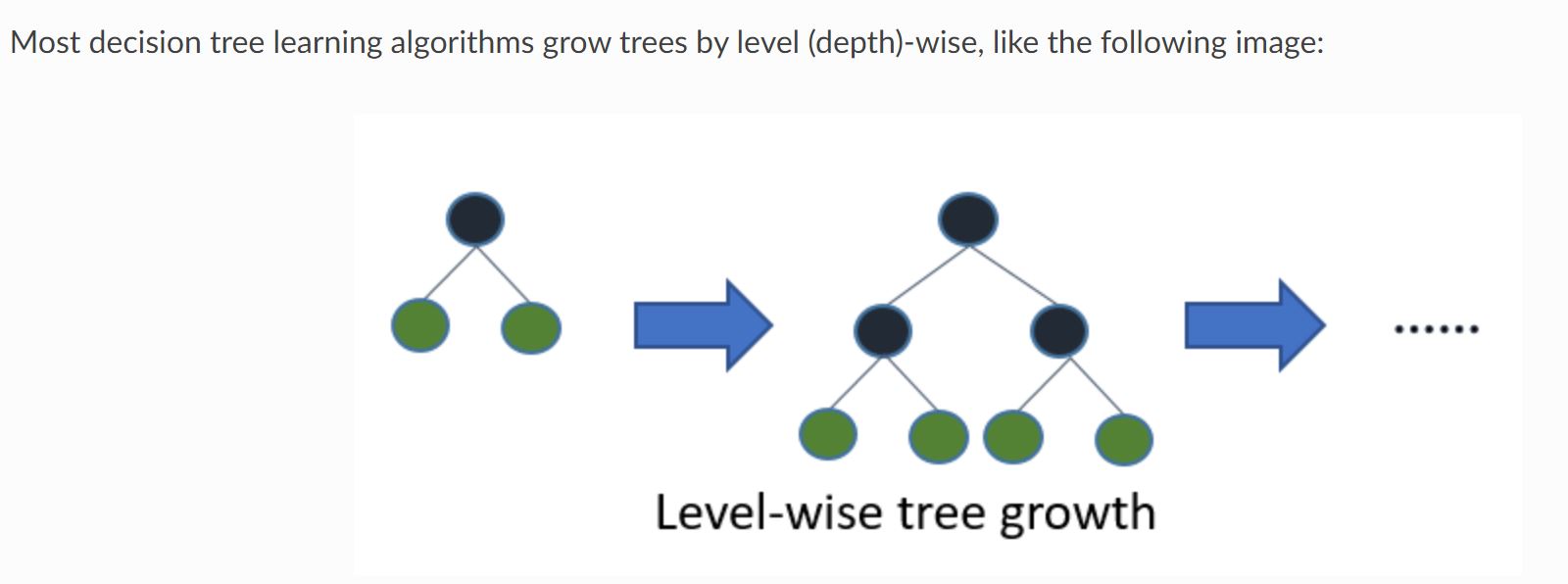
(引用元:Light GBM公式リファレンス)
一方Light GBMは以下のように葉ごとの学習を行います。これをleaf-wise法と呼びます。
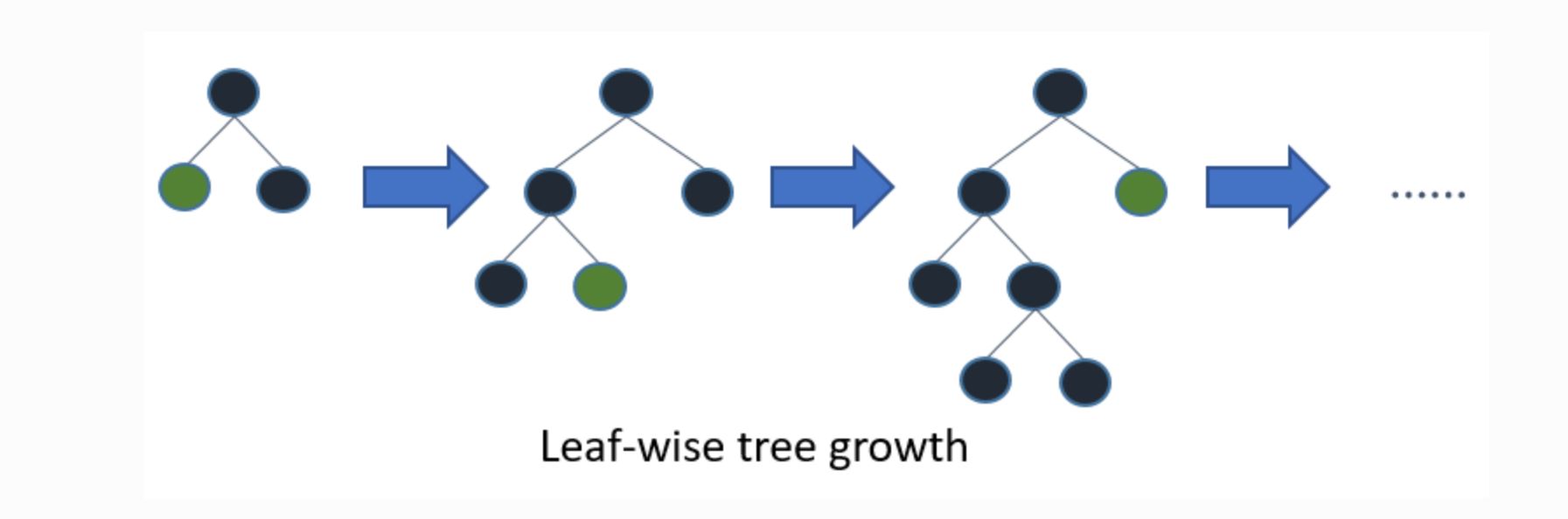
(引用元:Light GBM公式リファレンス)
これにより、ムダな学習をしなくても済むためよりXGBoostよりも効率的に学習を進めることができます。
Gradient Boosting Decision Tree (GBDT) is a popular machine learning algorithm, and has quite a few effective implementations such as XGBoost and pGBRT. Although many engineering optimizations have been adopted in these implementations, the efficiency and scalability are still unsatisfactory when the feature dimension is high and data size is large. A major reason is that for each feature, they need to scan all the data instances to estimate the information gain of all possible split points, which is very time consuming.
(引用元:Google-“LightGBM: A Highly Efficient Gradient Boosting
Decision Tree”)
詳しくは以下の記事でまとめていますのでチェックしてみてください!
それでは、LightGBMの結果はどのようになるでしょうか・・・?
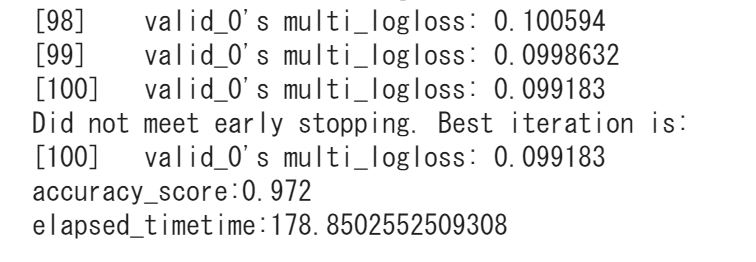
Light gbmは、0.972!若干Xgboostよりも低い精度になりました。
ただ、学習時間は178秒なので、なんとXgboostよりも8分の1ほどに短くなっています!
データサイエンスの特徴量精査のフェーズにおいて学習時間は非常に大事なので、この違いは大きいですねー!
Catboost
続いて、Catboost!
Catboostは、「Category Boosting」の略であり2017年にYandex社から発表された機械学習ライブラリ。
発表時期としてはLightGBMよりも若干後になっています。
Catboostは質的変数の扱いに上手く、他の勾配ブースティング手法よりも高速で高い精度を出力できることが論文では示されています。
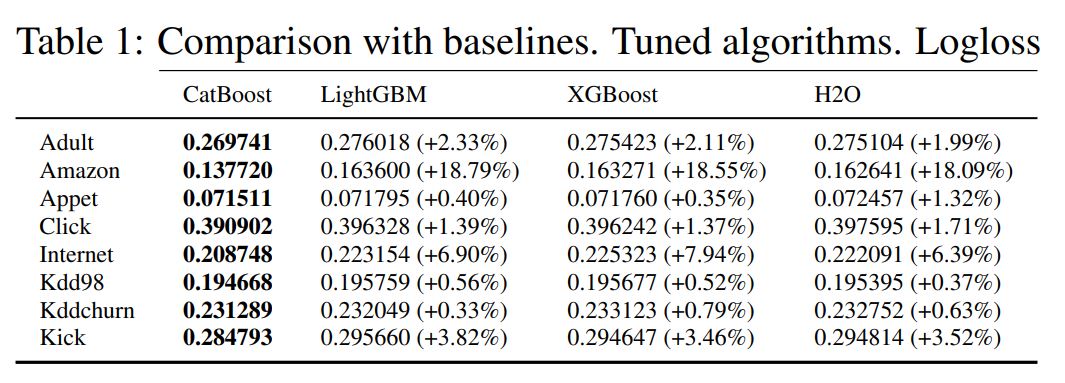
(引用元:”CatBoost: gradient boosting with categorical features support”)
以下の記事で詳しくまとめていますのでチェックしてみてください!

さて、そんなCatboostのパフォーマンスはいかに!?
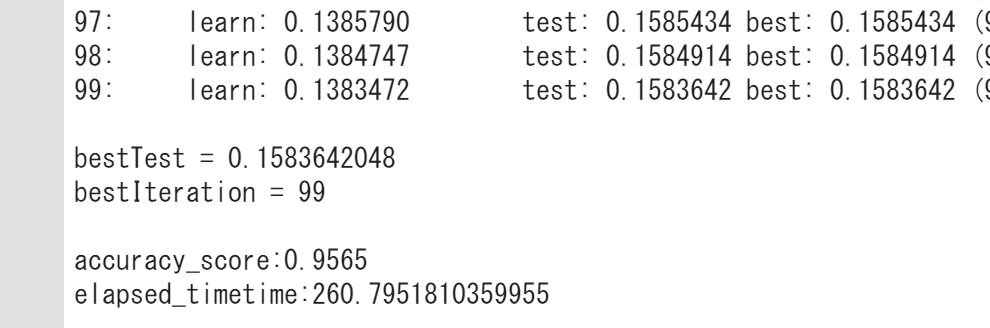
・・・・
精度は、0.9567・・
処理時間は260秒・・
何とも中途半端な結果におわってしまいましたー!
総合的に見ると、LightGBMが最も高速で実践的。
ただデータセットによって精度の良し悪しは変わるので、どんなデータでもこの手法の精度が高い!ということは示せない。
勾配ブースティングまとめ
本記事では、勾配ブースティングについて徹底的に比較してきました!
やはりLightGBMが最も高速で実用的なようです。
Xgboostはデータセットが膨大な場合、処理時間がかかり過ぎて実用的じゃなくなるケースがあります。
ぜひ勾配ブースティングの違いを理解して、実装してみましょう!
LightGBMを使ったデータ分析については以下のUdemy講座で詳しくまとめていますのでよければチェックしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ2000円以下になる講師クーポンを発行いたします!
またデータサイエンスを全般的にまとめて学びたい!という方には当メディアが運営するスクールであるスタビジアカデミー、略して「スタアカ」がオススメです!
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【Pythonの学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ 実際に実データを使った様々なワークを行う |
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
機械学習、データサイエンス、統計学、Pythonの勉強に関しては以下の記事を参考にしてみてください!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!