
探索的データ分析(EDA)の手順と方法について実データ×Pythonで理解しよう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!!
データ分析において非常に重要なのですがあまり日の目を見ないステップが、探索的データ解析(EDA)。
どうしてもデータ分析というと機械学習の部分が注目されがちなのですが、精度の高い機械学習モデルを構築するためにはその前手のEDAが必要不可欠なんです!
そして、データ分析に費やす時間のうち9割以上は実はEDAやデータの前処理・特徴量エンジニアリングであるといっても過言ではありません。

この記事では、そんなEDAについてどんなことが必要になるのか解説しながら最終的に実データを使ってPythonでEDAをおこなっていきたいと思います。
それではいってみましょうー!
以下の動画でも詳しく解説していますのでチェックしてみてください!
目次
探索的データ分析(EDA)とは
まずは、EDAとは。
そもそもEDA自体なかなか聞き慣れない言葉かもしれません。
EDAとは「Exploratory Data Analysis」の略であり、日本語に訳すと探索的データ分析となります。
データ分析のステップには様々な工程があり、「CRISP-DM」と呼ばれるステップが非常に有名です。
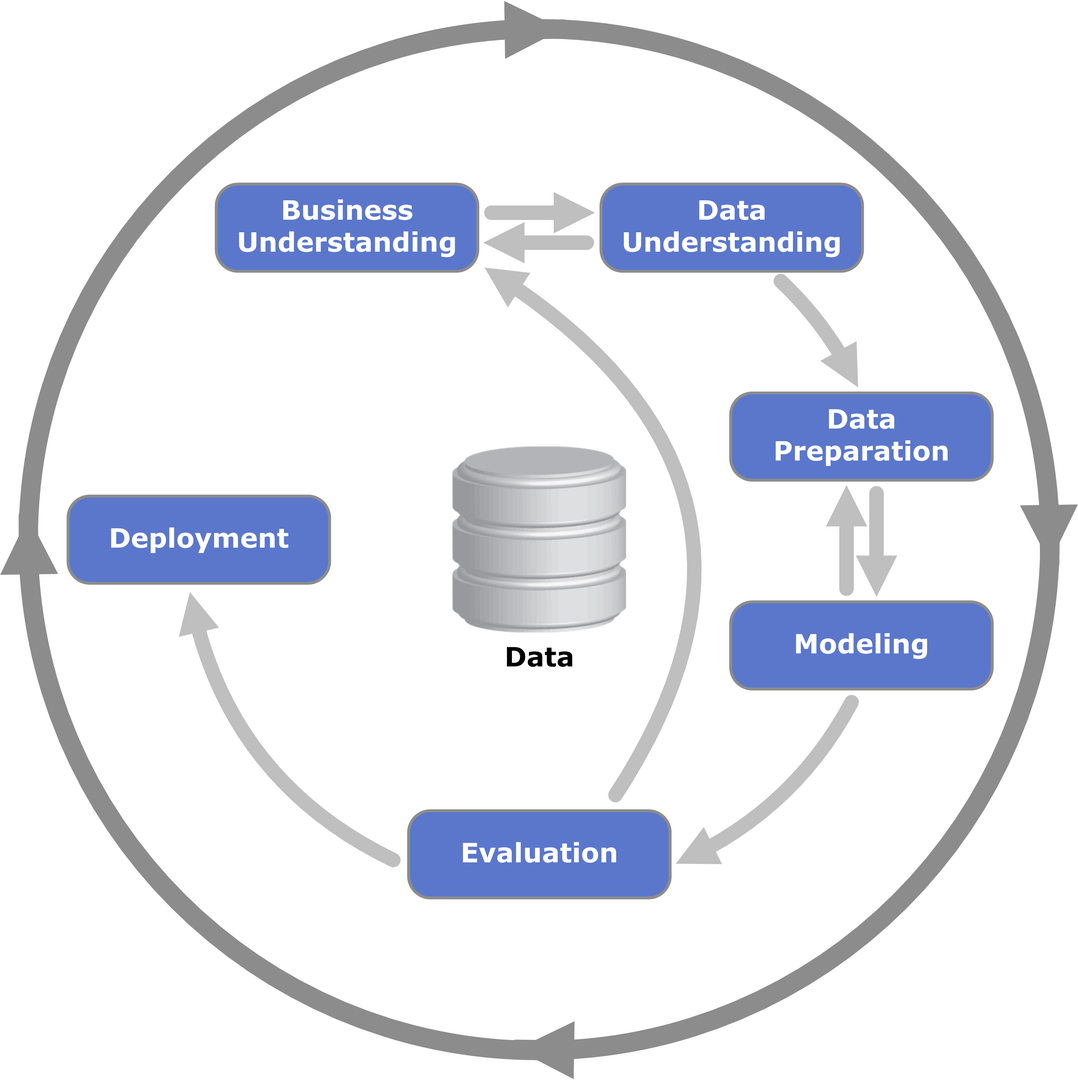
(出典:Wikipedia-‘Cross-industry standard process for data mining’)
CRISP-DMとは、「Cross-industry standard process for data mining」の略であり、データマイニング・データサイエンス・AI開発などにおいて業界横断で標準的に使えるデータ分析プロセスになります。
このCRISP-DMには全部で6つのプロセスがあります。
Business Understanding(ビジネス理解)
Data Understanding(データ理解)
Data Preparation(データ準備)
Modeling(モデル構築)
Evaluation(評価)
Deployment(実装)
この中でEDAはデータ理解の部分になります。
データの構造を理解して、前処理・特徴量エンジニアリングそしてモデル構築に進むための材料にします。
この部分を疎かにしてしまうと、結局意味のあるデータ分析は出来ません。
CRISP-DMの図でビジネス理解とデータ理解が行き来しているように、この工程ではEDAでデータを理解しながらビジネス課題の特定と筋の良い仮説出しをおこなっていきます。
非常に重要なステップだということが理解いただけたでしょうか?
CRISP-DMに関しては以下の動画や記事でも詳しく解説しているのでもう少し知りたいという方は是非見てみてください!

探索的データ分析(EDA)のステップ
続いて、EDAの手順について見ていきましょう!
どこにどんなデータがあるか確認する

当たり前ですが、どこにどんなデータがあるかまずは確認しなくてはいけません。
ER図などを基にして必ずどこにどんなデータがどのように格納されていてどのように関連付けられているか確認しましょう!
ER図とは、データベースの設計図のことで、Entity RelationshipからER図と呼ばれています。
ER図には様々なデータテーブルがどのように関連付けられていてどのようなカラムを持っているかが図で記載されています。
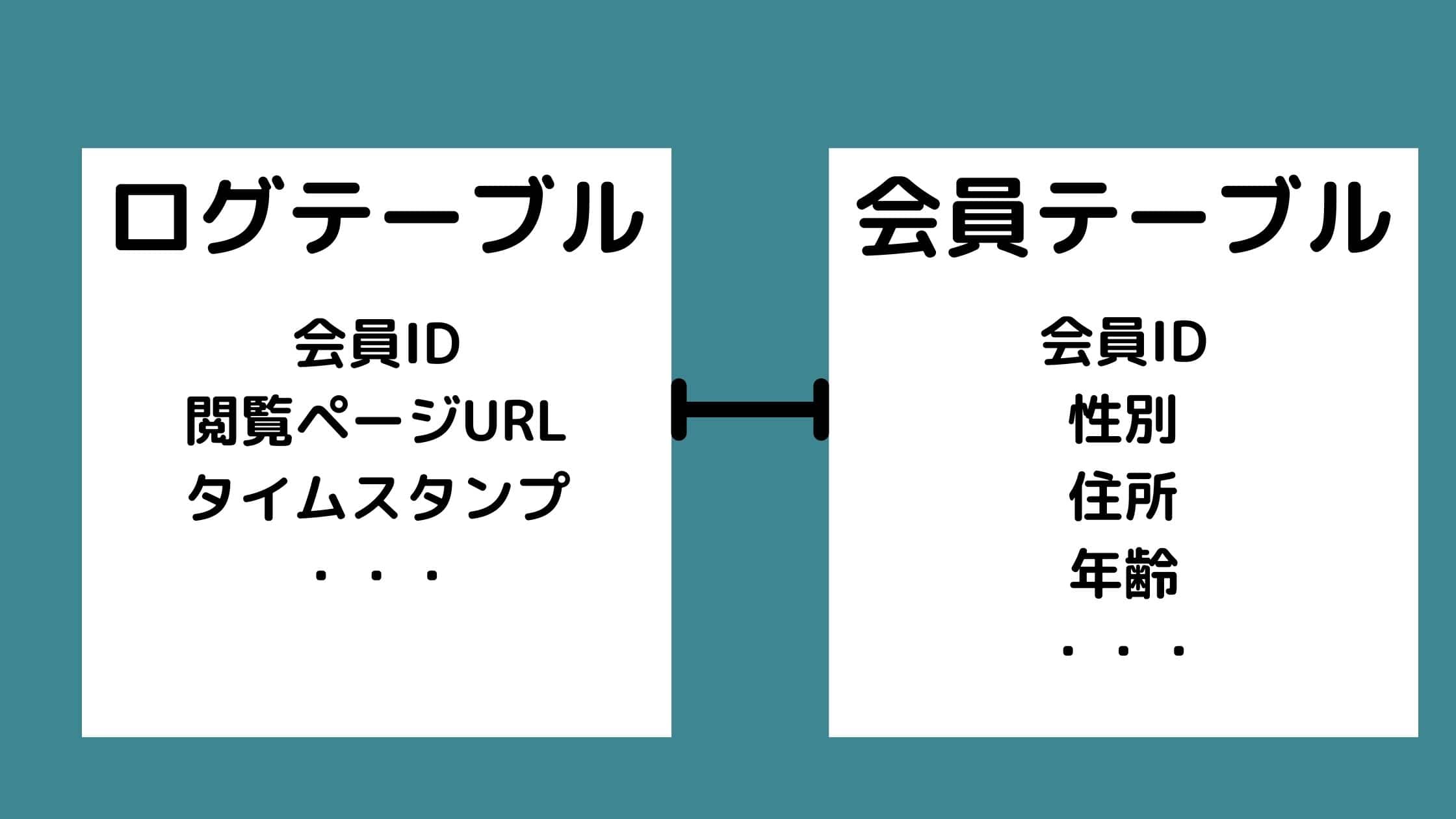
そして必要に応じてCRISP-DMのデータ準備の段階でそれぞれのデータテーブルの情報を連結するという作業が行われます。
例えば、Webサイトにおける顧客の行動ログデータのテーブルと顧客の会員情報のデータは別々のテーブルで管理されている、というような状況が考えられます。
この時、あるユーザーの購入確率みたいなものを予測する時には別々に存在するログデータと会員情報データを会員IDをキーにして紐づけて予測の元となるデータを構築していきます。
データの質と量をおおざっぱに把握する
続いてデータの質と量をおおざっぱに把握していきます。
データテーブルの行数と列数はどれくらいあるのか。
どんなカラムが入っているのか。
それぞれのカラムにはどんなデータがどんな型で格納されているのか。
ひとまずデータの質と量を確認することが大事です。
各種統計量を把握する
それぞれのカラムの平均値や最大値・最小値など基本的な統計量について確認していきましょう!
これによりデータの勘所を掴んでいきます。
相関関係を確認する

各種変数の相関関係を確認していきます。
仮にアイスクリームの売上を予測する際に気温を横軸に取って売上を縦軸に取った場合に気温が高ければ高いほど売上が高くなっていた場合は正の相関があるといい、相関関係は-1から1の間で表されます。

ただ注意しておいてほしいのが相関関係があると分かっても因果関係があるとは言えないということ。
AとBが原因と結果の関係になっているもので相関関係とは微妙に違います。
例えば、耳の大きさと学力の高さに正の相関関係があったときに、実はその裏には年齢という隠された因子があるという状況が考えられます。
赤ちゃんを含む全年齢を対象とした時、年齢が高いほど耳が大きくなり年齢が高いほど学力が高くなるので、一見耳の大きさと学力の高さには相関関係が生まれるのですが、そこには直接的な因果関係がないことが分かります。
このように相関関係をそのまま言葉通り鵜呑みにしてさも因果関係があるかのようにふるまうのは危険であるということはおさえておきましょう。

欠損値を把握する

続いて欠損値について確認していきましょう!
データによっては欠損値が存在する可能性があります。
欠損データをそのまま分析してしまうと様々な不都合が生じるので、欠損値に対しての対処方法はある程度おさえておくことが重要です。
欠損値については実はそれだけで1冊の書籍になってしまうのですが、ここでは簡単に確認しておきましょう!
実は欠損値には欠損の仕方によっていくつかのパターンがあります。
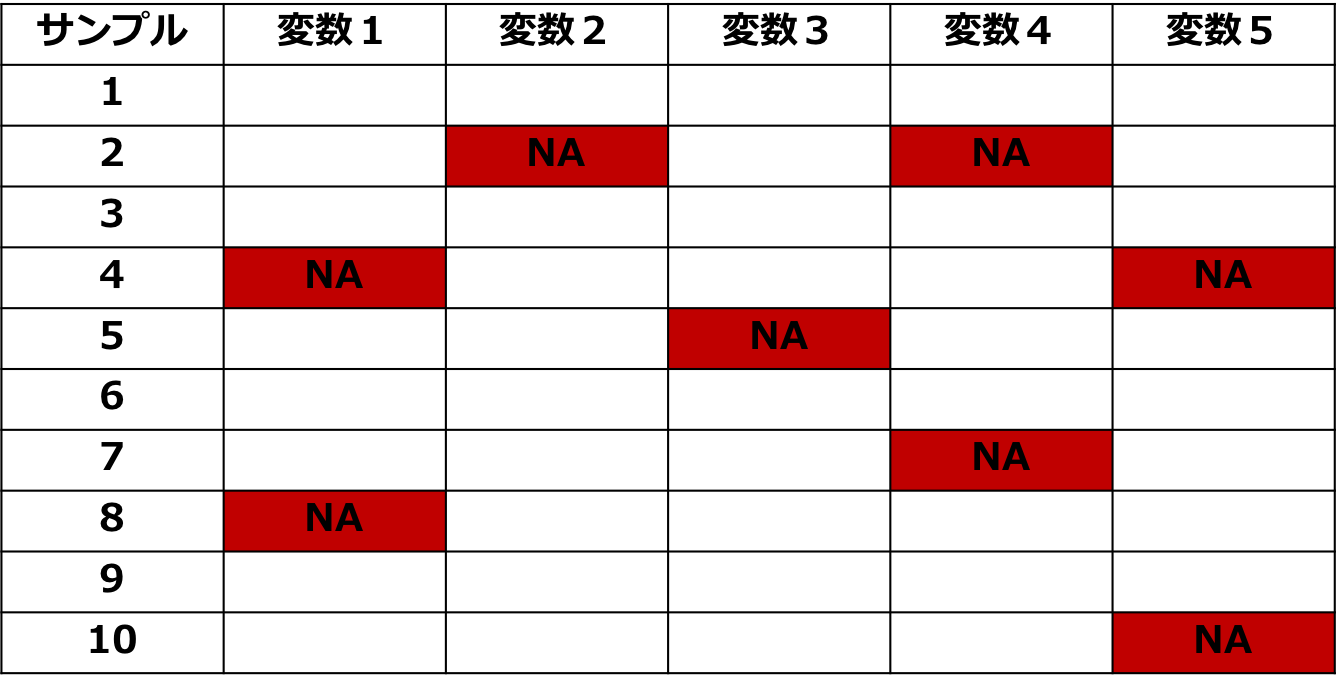
そしてそんな欠損値の対処方法として欠損の生じているデータを削除してしまう方法や何らかの処理によって欠損値を埋める方法がいくつかあります。
ただ、実はLight gbmをはじめとする決定木モデルの機械学習手法では欠損値が生じていても問題なく利用できるんです。
線形回帰モデルやニューラルネットワークを構築する場合は欠損値処理を行いましょう。
欠損値処理についてより詳しくは以下の記事で解説していますので是非チェックしてみてください!

外れ値を把握する

続いて外れ値を確認していきます。
外れ値があると推定精度が下がる可能性が高いので外れ値の有無を確認する作業は非常に大事です。
例えば、全く相関のないバラバラなデータがあったとき、そこに1つでも外れ値が紛れ込んでしまうと、一気に相関関係が生まれてしまうことになりかねません。
注意しましょう!
集計や層別を通してデータを可視化する

これ以外にもたくさんの切り口でEDAを行っていくことができます。
ある変数に注目して集計や層別を行うことが非常に重要です。
例えば、顧客の購入単価が毎年下がっていたとしても男女の性別データでデータを層別して見てみると男性は上がっていて女性が大きく下がっているのかもしれません。
月別に見てみると、冬のシーズンは変わらず夏のシーズンだけ極端に購入単価が下がっているかもしれません。
切り口を変えるとキリがないのですが、様々な観点でデータを切って可視化し比較していくクセはつけるようにしましょう!
探索的データ分析(EDA)を実データ×Pythonで実践!

それでは早速探索的データ分析(EDA)を実践してみましょう!
データコンペから実データを持ってこよう!
![]()
![]() Nishikaというデータコンペプラットフォームの中の「中古マンション価格」データを使います。
Nishikaというデータコンペプラットフォームの中の「中古マンション価格」データを使います。
![]()
![]() Nishikaに会員登録をして「中古マンション価格」データからtrain.zipをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
Nishikaに会員登録をして「中古マンション価格」データからtrain.zipをダウンロードしてください(※会員登録をしないとデータをダウンロードできません)。
train.zipを開くと中には以下のように複数のCSVファイルが入っています。
今回はこれらをデータフレームとして結合させるところからデータの確認・可視化をおこなっていきます。
そのためにまずはライブラリをimportしてあげましょう!
import glob
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inlineglobはディレクトリに格納されたファイル名を抽出するのに便利なライブラリで、今回は複数のファイルがtrainフォルダ内にデータとして格納されているのでそれらのファイル名を抽出するのに必要になります。

現在trainというフォルダにファイルが入っているとすると、以下のように記述することでtrain内のファイル名を全て抽出することができます。
files = glob.glob("train/*.csv")この時、*はワイルドカードと呼ばれ、このようにワイルドカードを指定することで全てのファイル名を該当させることができます。
filesを見てみると以下のようになっていることが分かります。
[‘train/40.csv’,
‘train/41.csv’,
‘train/43.csv’,
‘train/42.csv’,
‘train/46.csv’,
‘train/47.csv’,
‘train/45.csv’,
‘train/44.csv’,
‘train/37.csv’,
‘train/23.csv’,
‘train/22.csv’,
・・・
各ファイル名がリスト形式で格納されていることが分かりますねー!
globは非常によく使うので是非覚えておいてください。
このデータフレームの中身を見てみると・・・
pd.read_csv(files[0])以下のようになっていることが分かります。
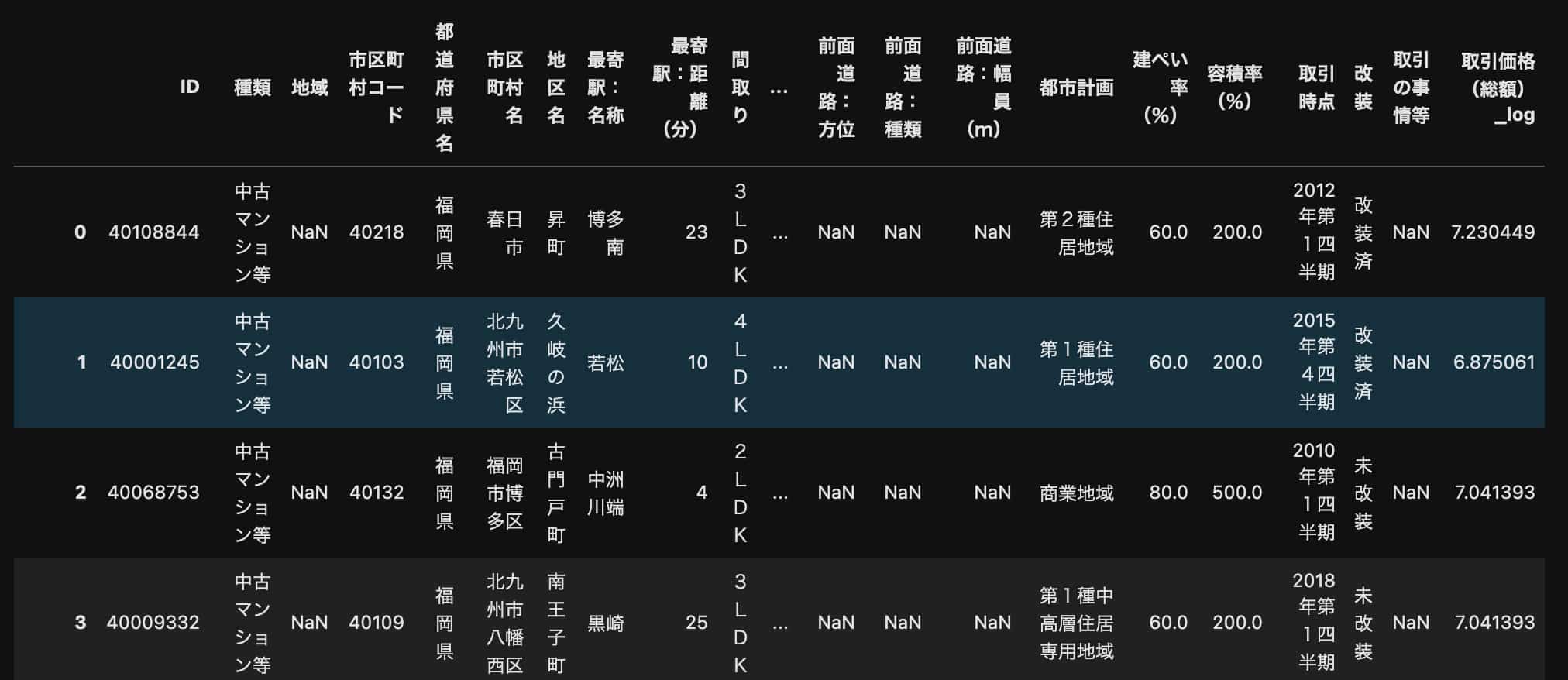
各ファイルそれぞれの格納されているサンプル数は違いますが、全て同じカラムになっています。
そのため、これらのデータをfor文で回して結合させ1つのデータフレームにしていきましょう!
data_list = []
for file in files:
data_list.append(pd.read_csv(file, index_col=0))
df = pd.concat(data_list)これにて使うデータの準備が完了です。

データの量と質・欠損値を確認していこう!
それでは、先程の流れの通り、まずはデータの量と質を確認していきます。
df.shapeこのように記述してあげることで、データがどれくらいの行数・列数で格納されているのかが分かります。
(637351, 27)
63万行ものデータ数がありますが、実務でログデータなどを扱う場合は何千万行ものデータ数を扱うことも多いので、それほど多くはないです。
カラムの数は27個あるようです。
それぞれのカラムについて確認してみましょう!
以下のように記述してあげることで、データフレームのカラムについて確認することが可能です。
df.info()
カラム名の隣にNon-Null Countというのがあり、ここは欠損していないデータがどのくらいあるかが記載してあります。
よくよく見てみると、0 Non-Null Countというカラムが結構ありますねー!
実はこれは、データが1つも入っていないゴミカラムです。
そうなんです。実データってかなり汚いんです。
EDAをせずにそのままモデルに投入すると大変なことになるのがなんとなく分かりますね。
さらにカラムの型がObjectになっていることが分かります。
Object型とは各要素の型が異なっており、文字列のstr型や数値のInt型で格納されています。
例えば、面積(㎡)もObject型になっていますがどんなデータが格納されているのか確認してみましょう!
以下のように記述してあげることで、面積にはどんなデータが格納されているのかが分かります。
pd.set_option('display.max_rows', 500)
df["面積(㎡)"].value_counts()
出力される行が省略されないようにpd.set_optionで最大出力を500行にしています。
出力されたデータを見てみると、実は2000㎡以上という文字列データが隠れていることが分かります。
このデータに関しては2000に変換してあげた方がよさそうですね。
以下のように変換してあげることで全て文字列が数値型にすることができました。
df["面積(㎡)"] = df["面積(㎡)"].replace("2000㎡以上", "2000")
df["面積(㎡)"] = df["面積(㎡)"].astype(float)この時、ポイントなのはfloat型に変換してあげることです。
この場合は、面積データに欠損値すなわちNull値がないのでfloatの部分をintにしてあげても問題ないのですが、Null値がある場合はint型に変換することができません。
実はNull値はfloat型として定義されているのです。
Pandasのデータフレームの型変換で数値型に変換する際はfloat型で変換するのがベターです。
統計量を見ていこう!
続いて統計量を見ていきましょう!
df["面積(㎡)"].describe()describeを利用することで、簡単な統計量を確認することができます。
count 637351.000000
mean 58.663570
std 26.712019
min 10.000000
25% 45.000000
50% 65.000000
75% 75.000000
max 2000.000000
Name: 面積(㎡), dtype: float64
データ数、平均値、標準偏差、最小値、4分位点、最大値などが分かります。
面積の最小値は10㎡、最大値は2000㎡となっており、平均値は58㎡ほどのようです。
面積ごとのヒストグラムを見てみましょう!
ここでデータ可視化のライブラリMatplotlibの出番です!
plt.hist(df["面積(㎡)"], bins=20, range=(0,200))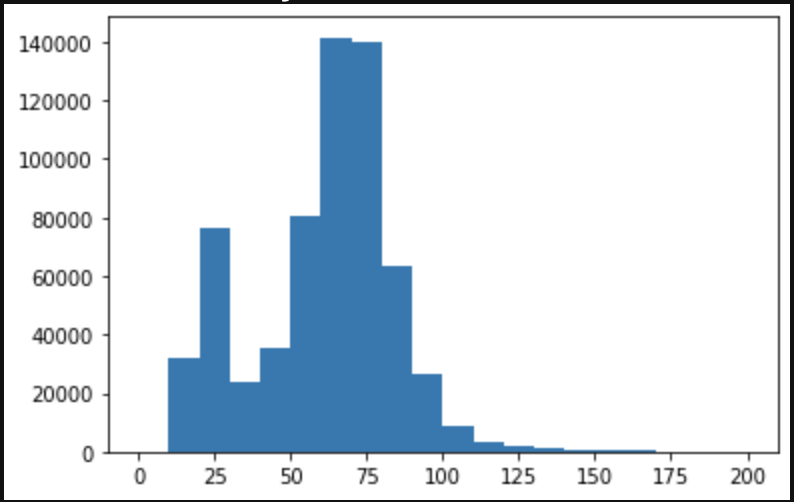
200㎡以上は非常に少数になっているので200㎡以下でX軸を切っています。
50㎡〜80㎡あたりが家族世帯でのボリュームゾーンになっていて、25㎡部分が一人暮らし需要によりボリュームゾーンになっていることが見て取れますね。
相関関係を見ていこう!
続いて、これらの面積と不動産の売上の相関関係について見ていきましょう!
df[["取引価格(総額)_log", "面積(㎡)"]].corr()相関係数を計算してみると・・・
0.382755
であり小〜中程度の相関があることが分かります。
また、以下のように散布図を見てみると・・・
plt.scatter(x="取引価格(総額)_log", y="面積(㎡)", data=df)
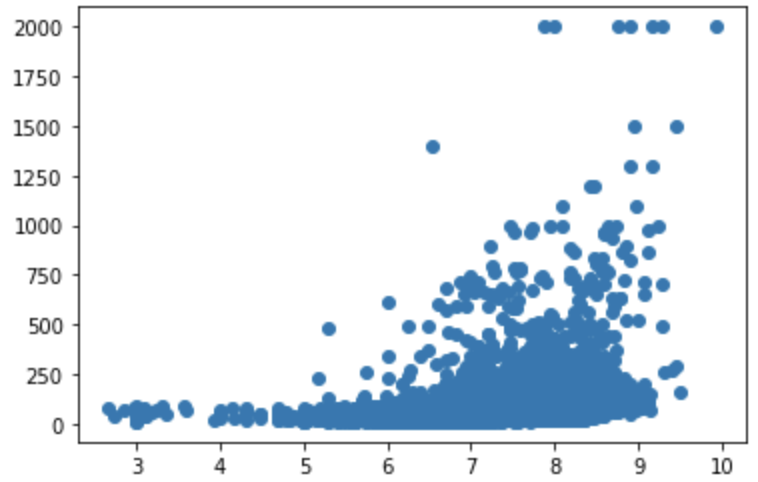
やはり中程度の相関があることが分かります。
この時2000㎡以上のデータは非常に少数であり、全て2000㎡に丸めてしまっているので相関係数に大きな影響を与えている可能性があります。
相関係数は外れ値の影響を非常に受けやすいのです。
念の為2000㎡以上のデータを除外して相関係数を見てみましょう!
df[df["面積(㎡)"]!=2000][["取引価格(総額)_log", "面積(㎡)"]].corr()0.390629!
それほど変わらないですね。
探索的データ分析(EDA)のステップ まとめ
本記事では、探索的データ分析(EDA)についてまとめてきました!
EDAを学ぶにはやはりしっかり手を動かしながら学ぶことが大事です。
ここで取り上げたステップを様々なデータで試してみながらEDAの勘所を掴んでいきましょう!
探索的データ分析(EDA)について詳しく知りたい方は以下のUdemy講座を僕が作成していますので是非参考にしてみてください!
【初学者向け】データ分析コンペで楽しみながら学べるPython×データ分析講座
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ1500円になる講師クーポンを発行いたします!
また、当メディアが運営するAIデータサイエンス特化スクールの「スタアカ(スタビジアカデミー)」では、EDAをはじめとしたデータ分析のステップについて網羅的に学べますのでぜひチェックしてみてください!
スタアカ(スタビジアカデミー)
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
24時間以内の質問対応と現役データサイエンティストによる1週間に1回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
EDAをおこなった後はデータの前処理や特徴量エンジニアリングといった作業に進んでいきます。
CRISP-DMでいうところのData preparation(データ準備)の工程であり地味ですが非常に重要であり、この部分がモデルの精度を左右します。
Data preparationにおいて重要な特徴量エンジニアリングについては以下の記事で解説していますので是非チェックしてみてください!

また機械学習手法については以下の記事でまとめていますのであわせてチェックしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















