
データマイニングとは!事例や手法、Pythonでの実装をわかりやすく解説!


こんにちは!スタビジ編集部です!
私たちの周りには膨大な量のデータが蓄積されており、その中には貴重な情報や洞察が隠れています。
そこで欠かせないのがデータマイニング!
今回はデータマイニングについて詳しく解説し、有名な手法のPythonでの実装まで行っていきます!
・データマイニングとは?
・データマイニングの代表的な手法
・データマイニングの各分野での活用事例
・ビジネスを意識したPythonでのデータマイニング実装
以下の動画でも解説していますので合わせてチェックしてみてください!
目次
データマイニングとは

まずはじめに、「データマイニングとはそもそも何のことなのか?」について解説していきます!
データマイニングは、インターネットからあらゆるデータが入手可能な現代においてますます重要性を増しているデータ解析の手法です!
この手法は、大量のデータからパターンや規則性を抽出し、有益な知見や価値のある法則を得ることを目的としています。
技術が進化し多くのデータを取得し保有することができる時代になりました。今の時代データなくしてビジネスは語れません。
そんな重要なデータから重要な示唆を生み出すプロセスこそデータマイニングなんですね。
データマイニングは主に、ビジネスや科学の分野における意思決定や問題解決の支援のために幅広く利用されます。
例えば、企業は顧客の購買履歴から嗜好を分析し、顧客ごとに適したマーケティング戦略を展開するのに役立てることができます!
またデータマイニングにより科学者や研究者は、実験データからパターンやトレンドを見出し、新たな仮説や発見を導き出すことができます。

~データマイニングは、大規模なデータセットに埋もれた貴重な情報を発掘し、ビジネスや科学の進歩に貢献しています~
ちなみにデータマイニングとデータサイエンスが結構違いが曖昧で難しいのですが、データマイニングはデータを分析し示唆出しすることのみにフォーカスしているのに対して、データサイエンスはビジネス課題特定やデータ取得・蓄積など幅広い過程全体を守備範囲をしています。

代表的なデータマイニング手法

データマイニングには実にさまざまな手法が存在しています!
ここでは代表的な手法を4つのカテゴリーに分けて紹介していきます!
クラスタリング
クラスタリングは、似たような特性を持つデータをグループ化する手法です!
この手法では、指標をもとにデータ間の類似度や距離を計算し、類似したデータを同じグループに割り当てていきます。
クラスタリングの目的は、データ内の構造や傾向/パターンを特定し、データの特徴を理解することにあります!
クラスタリングの代表的なアルゴリズムには、K-meansや階層的クラスタリングがあります。
アルゴリズムの詳細についてやクラスター分析のRとPythonを用いた実装については以下の記事で確認できます!

分類
続いて分類。
分類は、あらかじめ定義されたカテゴリにデータを分類する手法です。
この手法では、訓練データを使用してモデルをトレーニングし、未知のデータを特定のカテゴリに分類します。
分類は基本的に、教師あり学習として利用されます。
教師あり学習と教師なし学習の違いについてはこちらの記事をぜひご参考に!

代表的なアルゴリズムには、決定木やロジスティック回帰、サポートベクターマシンがあります。
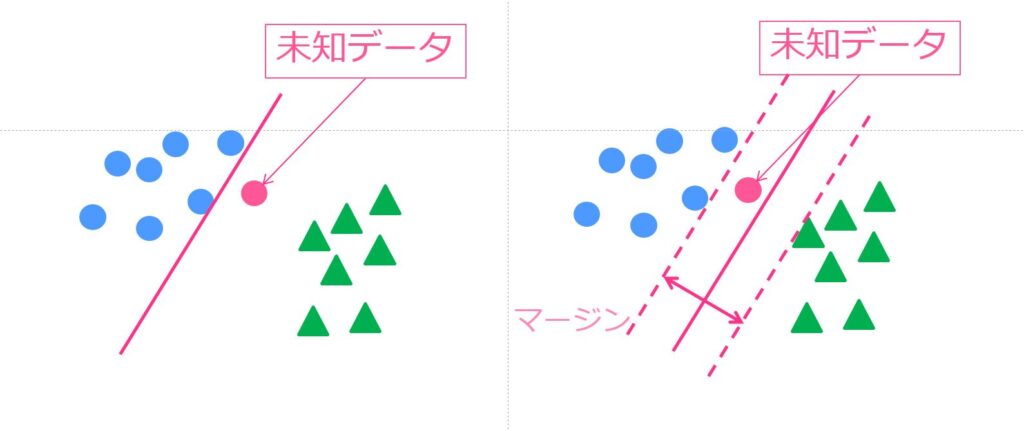
例えばサポートベクターマシンではデータを最適に分離する境界線を見つけます!
その際、クラス間の最大マージンを持つ境界線を求め、新たなデータがその境界線に対してどちら側に寄っているかでデータを分けていく流れです!
詳しくは以下の記事をチェックしてみてください!

回帰
回帰は、入力変数と出力変数の関係をモデル化し、入力変数から出力変数の値を予測するための手法です。
回帰分析では、説明変数と目的変数の間の関係を数学的なモデルで表現し、未知のデータに対して目的変数の値を予測します。
つまり、与えられたデータから、連続的な値を持つ目的変数の予測を行います。
代表的なアルゴリズムには、線形回帰、多項式回帰、ランダムフォレスト回帰などがあります!
回帰分析(線形回帰)についてはイメージしやすい具体例と共に以下の記事でまとめておりますのでぜひご覧ください!

異常検知
異常検知は、通常とは異なる振る舞いを示すデータを検出する手法です!
異常検知の主な目的は、異常なパターンや不審な行動を特定し、問題の早期発見やセキュリティの向上に役立てることにあります。
有名なアルゴリズムには、k近傍法やMT法・ホテリング管理図、オートエンコーダなどが挙げられます!
異常検知については以下のYoutubeの動画でも解説していますのであわせてチェックしてみてください!



データマイニングの実際の活用事例
データマイニングは、実際に様々な分野で幅広く活用されています!
ビッグデータ時代の到来によりデータの蓄積量が急速に増加し、その中から価値のある情報を抽出することが求められるようになりました。
以下では、データマイニングがどのような分野でどのように活用されているかを具体的に見ていきましょう!
小売業
小売業界では、データマイニングを用いて顧客の行動パターンや嗜好を分析し、個別のマーケティング戦略を立案します。
例えば、大規模な小売店は顧客の購買履歴や行動データを分析して、購買傾向や好みを把握し、ターゲティング広告やユーザーに刺さる特別な販促イベントを実施します!
これにより、顧客満足度の向上や売上の増加が期待されます。
医療分野
医療分野では、データマイニングが臨床データの解析や治療効果の予測に活用されています。
例えば、病院や医療機関では患者の電子カルテや検査結果、治療記録などのデータを分析して、特定の疾患のリスク因子や治療法の効果を評価します!
また、遺伝子解析やゲノムデータの解析を通じて、個々の患者に最適な治療法を提案する研究も進んでいます。
データマイニングにより、さらに効果的な医療サービスの提供や健康管理が可能になります!
金融業界
金融業界では、データマイニングがリスク管理や顧客サービスの向上に活用されています。
例えば、銀行やクレジットカード会社は、顧客の取引履歴や支出パターンを分析して、不正取引や信用リスクを検出し防止します。(異常検知など)
また、顧客の財務情報を活用して、適切な金融商品やサービスを提供することで、顧客満足度の向上や収益の増加を図っています!
Pythonでデータマイニングを実装してみよう

ビジネスの現場では、膨大なデータが日々生成されていますが、このデータを活用することでビジネスの課題解決や意思決定の支援が可能です。
ここでは、実務でのデータマイニングの活用を少しでもイメージして頂きながら、クラスタリングと分類の手法を用いてPythonでの実装をしていきます!
以下の流れで進めていきます!
1. クラスタリングによる顧客のグルーピング
2. 分類による購買パターンの予測モデルの作成
1. 「クラスタリング」を用いた顧客グループの特定
顧客セグメンテーションは、顧客を異なるグループに分けることでそれぞれのグループに適したマーケティング戦略を展開する手法です。
クラスタリングを用いることで、顧客間の類似性を把握し、顧客セグメントを特定することができます。
例えば、顧客の購買履歴や属性情報を用いて、顧客を価値の高いグループ、中程度のグループ、低いグループなどに分類することが可能です。
以下に、Pythonを用いたクラスタリングの実装例を記載します!
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# データの準備(X:顧客ごとの購買単価や購買頻度だと仮定)
X = [[5, 3], [10, 15], [15, 12], [24, 10], [30, 45], [85, 70], [71, 80], [60, 78], [55, 52], [80, 91]]
# クラスタリングモデルの構築
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
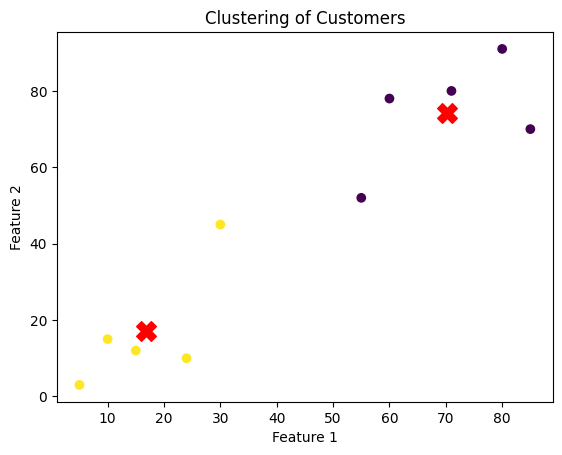
# クラスタリング結果の可視化
plt.scatter(*zip(*X), c=kmeans.labels_, cmap='viridis')
plt.scatter(*zip(*kmeans.cluster_centers_), marker='X', color='red', s=200)
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.title('Clustering of Customers')
plt.show()
結果を見てみましょう。
2. 「分類」を用いた購買パターンの分析と予測
顧客の購買行動の予測では、分類を用いることが一般的です。
これは、顧客の購買履歴や属性情報をもとに、将来の購買行動を予測することを意味します。
例えば、過去の購買履歴から特定の商品を購入する顧客の傾向を分析し、将来の購買行動(買いそうか?買わなそうか?)を予測することができます。
これにより、需要予測や販売戦略の最適化などが可能になります!
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# データの準備(X:顧客の過去の購買履歴や属性情報、yは実際の購買行動だと仮定)
X = [[5, 3], [10, 15], [15, 12], [24, 10], [30, 45], [85, 70], [71, 80], [60, 78], [55, 52], [80, 91]]
y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1] # 0: 購買しない、1: 購買する
# データの分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルの構築と学習
model = LogisticRegression()
model.fit(X_train, y_train)
# モデルの評価
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
学習データとテストデータに分け、実際に分類をさせてみたところ、今回の例では、
Accuracy: 1.0
となりました。
今回作成したモデルで実際の予測を行った結果の精度が100%であることを意味します!
まとめ

ここまでご覧いただきありがとうございました!
本記事では、データマイニングの基本概念や手法、そして実際の活用事例とPythonでの実装方法について解説しました!
データマイニングは大量のデータから価値ある情報を抽出するための重要な手法であり、ビジネスや科学分野で幅広く活用されています!
顧客セグメンテーションや購買行動の予測など、実務でよく用いられるデータマイニングの事例も紹介しましたが、これらの考え方を知っておくだけでもビジネスのあらゆる場面で応用することが出来ると思います!
データマイニングは色んな業界で利用されているプロセスであり、データが増えていきデータの価値が高まっていく今の時代において非常に重要です。
ただデータマイニングという言葉自体の定義は曖昧で、データサイエンスなどと混同して使われていることは多いです。
あくまでもデータマイニングは、その言葉通りデータから何かしらの示唆を掘り起こすことに焦点が当てられているのだということを頭に入れておいてください。
実際に使う手法はその時々で色んな手法がありますので、機械学習・統計学の様々な手法を幅広く頭に入れておくとよいでしょう!
ぜひ一度、気になる手法で実装まで行ってみてください!
今回分析に用いたPythonについて勉強したい方は以下の記事を参考にしてみてください!

さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















