
【入門】Vision Transformerについてわかりやすく解説!Pythonで画像分類実装!

こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では、Transformerを画像認識の世界に応用した手法であるVision Transformerについて解説していきます!
昨今様々なAI手法が登場して玉石混交状態になっていますが、各時代に注目されてきた主要な手法はおさえておくとよいでしょう!
Vision Transformerは論文発表時点でSOTA(State-of-the-Art※特定評価軸で最高評価)を獲得した手法なのです。
見ていきましょう!
以下の動画でもわかりやすく解説していますのであわせてチェックしてみてください!
Vision Transformerとは?
Vision Transformer(ViT)とは2021年にGoogleから発表された画像認識用のtransformerです。
論文は以下です。
transformerは2017年にGoogleから発表され、従来のリカレント層などを使わずAttention層だけを使い高い精度を達成しました。
このtransformerのアーキテクチャを元に自然言語処理ではなく画像認識の領域に応用したのがVision Transformerなのです。
transformerについて詳しくは以下の記事にまとめていますので是非チェックしてみてください!
それでは実際にVision Transformerがどんな手法なのか見ていきましょう!
論文からアーキテクチャを拝借しちゃいましょう!
Vision Transformerは以下のようなアーキテクチャになっています。
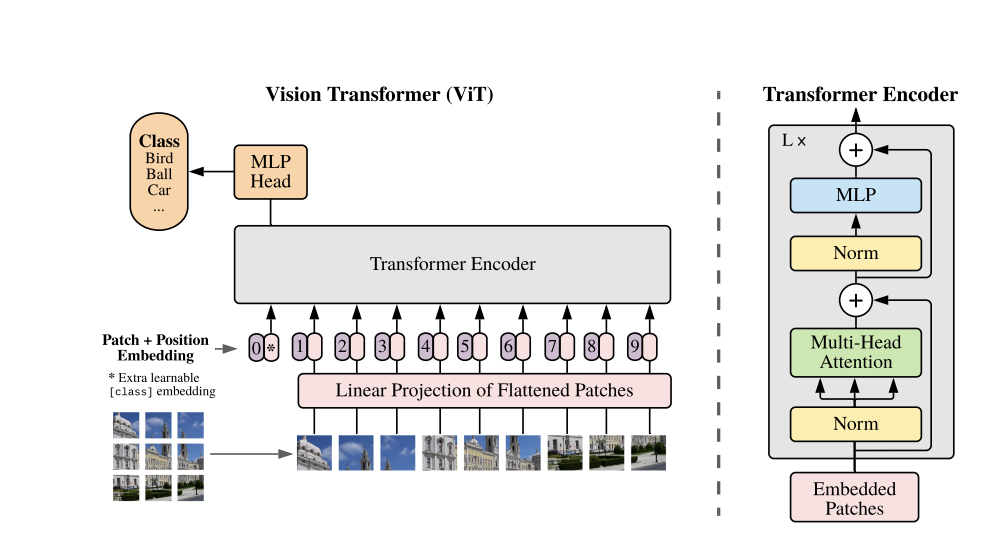
非常にシンプルでほぼTransformerのアーキテクチャと変わりません。
一応以下がTransformerの論文に記載されているアーキテクチャです。
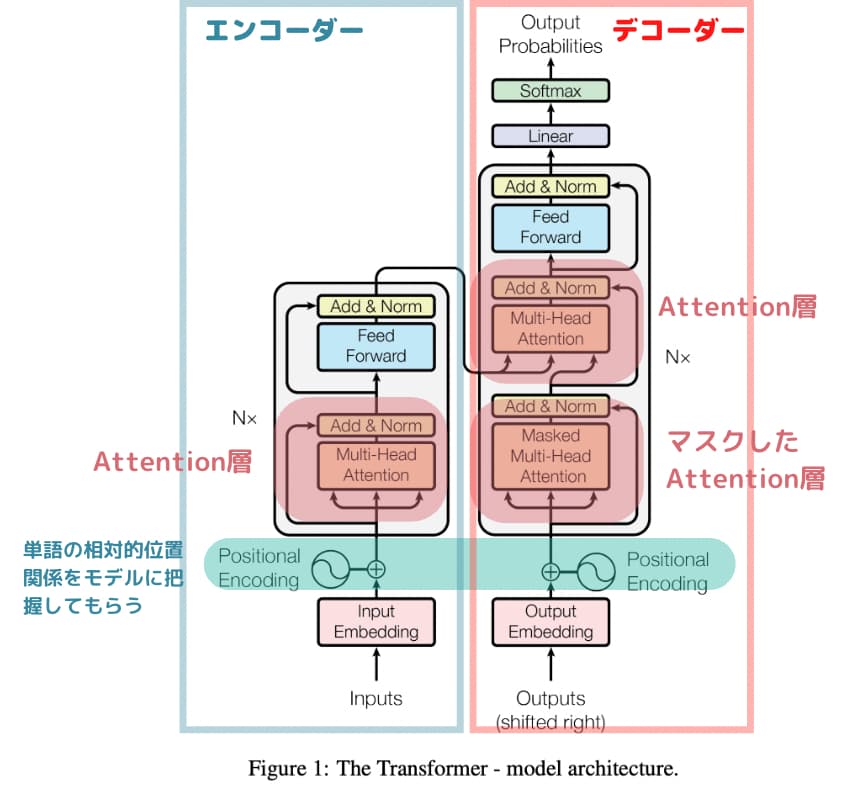
Transformerでは文章を分かち書きしたもの(例:私 / は / 猫 / を / 飼っている)をエンコーダーに入れておりましたが、画像認識では画像を分割したもの(Patch)をエンコーダーに投入しています。
少し表現が違うのですが、Vision Transformerも元祖transformerもどちらも入力をEmbedding(ベクトル化)して位置関係を考慮(Position Encoding / Position Embedding)してMulti Attention層と正規化と通常の多層パーセプトロン(MLP / Feed Forward)の組み合わせでアーキテクチャが構築されています。
位置関係を考慮してる部分はそれぞれVision TransformerではPosition Encoding 、Transoformerでは Position Embeddingと表現されているのが分かりますね!
また、Vision TransoformerのMLPは多層パーセプトロンを表現しており、Transoformerのアーキテクチャの中だとFeed Forwardにあたります。
順番が前後しているところはありますが、大枠はどちらも変わっていないことが分かるでしょう!
Vision Transformerのパフォーマンス
それでは続いてVision Transformerのパフォーマンスについて見ていきましょう!
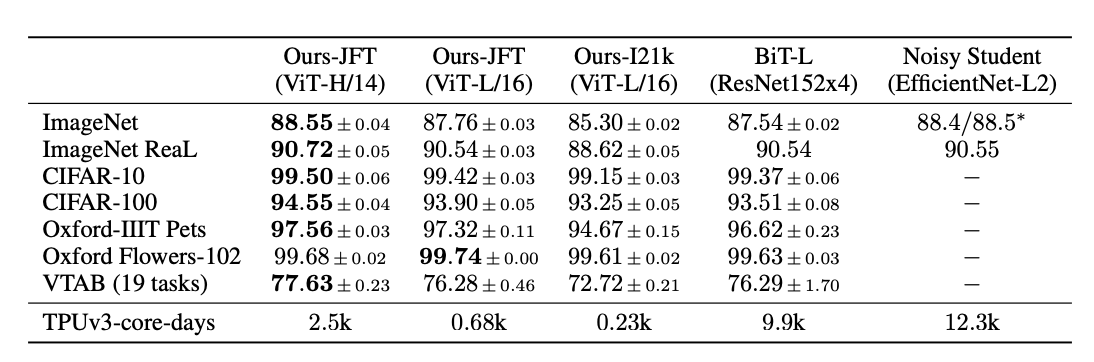
様々な画像データセットで各手法の精度を比較した結果が掲載されています。
ちなみにImageNetは画像データセットの中でも非常に古くから使用されている有名なデータセットです。
これを画像分類の識別精度を表しており、100%に近ければ近いほど良いスコアとなります。
結果を見るとViT(Vision Transformer)-H/14のモデルがほとんどのデータセットで最高評価を出力していることが分かります。
H/14やL/16というのはモデルのバリエーションを表しており、HがHuge、LがLargeで以下のような違いがあります。
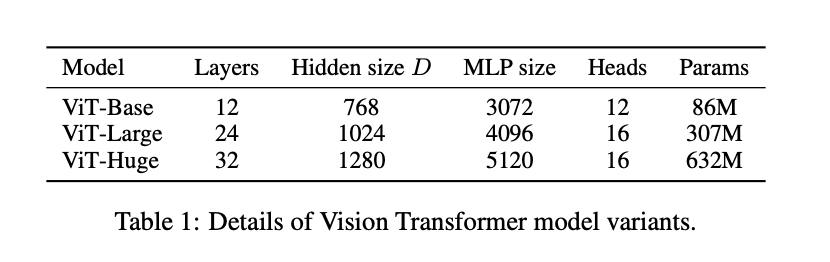
シンプルにHugeの方がモデルが複雑になっているので計算量は多くなりますが精度は高くなりますね。
また14, 16はPatch Sizeのことで、1枚の画像をPatch Sizeに分割してモデルにインプットするので小さい方が細部を学習してモデルの精度が上がると考えられます。
Vision Transformerを実装
それでは簡易的にVision TransformerをPythonで実装していきましょう!
今回はGoogle Colabを使っていきます。
事前にランタイムのタイプをGPUにしておいてください。
必要なライブラリをインポートしていきます。
import torch
from vit_pytorch import ViT
from torchvision import transforms
from torchvision.datasets import CIFAR10
from torch.utils.data import DataLoader, Subset
import numpy as npPytorchのライブラリを使っていきます。
続いて、データの前処理とデータセットの準備を行っていきます。
# データの前処理とデータセットの準備
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
])
train_dataset = CIFAR10(root='./data', train=True, transform=transform, download=True)
indices = np.random.choice(len(train_dataset), size=5000, replace=False)
train_subset = Subset(train_dataset, indices)
train_loader = DataLoader(train_subset, batch_size=32, shuffle=True)ここでは「CIFAR10」というデータセットを利用していきます。CIFAR10は比較的小規模な画像データセットです。
ただそれでも学習するには時間がかかるのでここでは5000枚ランダムサンプリングして学習していきます。
続いてモデルの定義です。
学習にかかる時間を早めるため小さいモデルで定義します。
model = ViT(
image_size=32,
patch_size=8,
num_classes=10,
dim=128,
depth=3,
heads=2,
mlp_dim=256,
)
# 損失関数と最適化手法の定義
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
パラメータは以下の通りです。
image_size: 入力画像のサイズ。
patch_size: 画像をどのサイズのパッチに分割するか。
num_classes: 分類するクラスの数。
dim: 埋め込みの次元数。
depth: Transformer ブロックの数。
heads: Transformer 内の multi-head attention のヘッド数。
mlp_dim: Transformer 内のMLPの次元数。
また、損失関数と最適化手法の定義をしています。
CrossEntropyLoss は、クラス分類タスクにおける標準的な損失関数です。
Adam は最適化アルゴリズムの一つで、ここでは学習率を 0.001 に設定しています。
続いて実際に学習を進めていきます。
エポック数は10回と少なめにしています。
# 学習ループ
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for batch_idx, (data, targets) in enumerate(train_loader):
optimizer.zero_grad()
outputs = model(data)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
if batch_idx % 10 == 0:
print(f"Epoch {epoch}/{num_epochs} - Batch {batch_idx}/{len(train_loader)} - Loss: {loss.item()}")
結果は、、、38.7%となりました。10個の多クラス分類ですが、それでも低い精度。
今回はテスト実装ということでなるべく早く実行するためにCIFAR10という小規模なデータセットから5000個ランダムサンプリングし、モデルも小規模にしたのでこのような精度になりましたが、もっと大規模データセットを使って複雑なモデルで学習すれば精度が高くなるはずです!
興味のある方は試してみてください!
Vision Transformer まとめ
ここまでご覧いただきありがとうございました!
本記事では、Vision Transformerについて解説してきました。
transformerの登場でAI業界に大きなブレークスルーが起き、そこから日々さらなる進化を遂げています。
最新の生成系AIについて知りたいという方はぜひスタビジアカデミーの大規模言語モデル・生成系AIコースを覗いてみてください!
「スタアカ(スタビジアカデミー)」は当メディアが運営するAI特化の教育サービス。興味のある方はチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















