自然言語処理領域で重要なDoc2Vecの仕組みとPython実装についてわかりやすく解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
この記事では自然言語処理領域の中で非常に重要なDoc2Vecについて簡単に解説していきます。
文書をベクトル化する技術には古典的な手法でtf-idfなどがあり、最近では大規模言語モデルの台頭で自然言語処理領域に様々なアプローチが生み出されています。
Doc2Vecは少し枯れた技術と思われがちですが理解しておくことは最新の技術を理解する上でも非常に大事。
ここでしっかり理解しておきましょう!
以下のYoutube動画でも詳しく解説していますので合わせてチェックしてみてください!
Doc2Vecとは?
Doc2Vecとはその名の通り
「ドキュメント(文書)をベクトルに変換する」アプローチです。
提案論文は以下です。
Doc2Vecの論文は2014年に発表されていて、Word2Vecの発表から1年後にあたります。
Word2Vecは「ワード(単語)をベクトルに変換する」アプローチですので、Doc2VecはWord2Vecの応用版と考えることができます。
ちなみにWord2VecもDoc2VecもGoogleの研究員らによって発表され、そのうちの1人はTomas Mikolov氏でどちらの論文にも名前を連ねています。
文書をベクトル化するのはどういうことかというと以下のようにいくつかの文書があった時にそれをベクトル化して可視化できるということです。
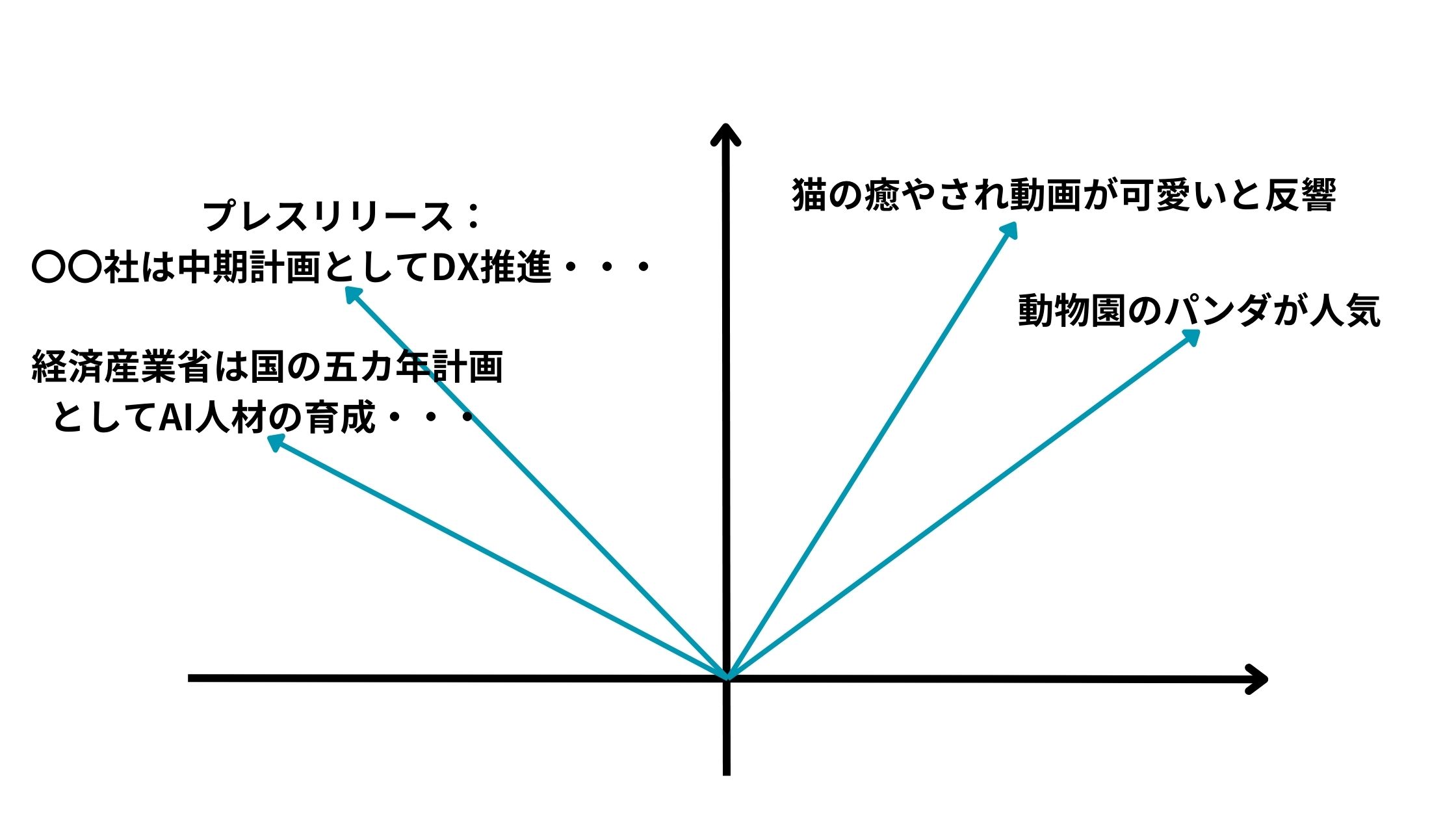
これにより特定の文書は近い意味合いを持っていて、特定の文書は遠い意味合いを持っているというのが分かるのです。
これにより、トピックの近い文書を探すこともできたり文書のコピペ判定などに使うこともできたりします。
Doc2Vecの仕組み
それでは簡単にDoc2Vecの仕組みを見ていきましょう!
Doc2Vecには2つのアプローチがあります。
・PV-DM
・PV-DBOW
PV-DM
まずはPV-DM!
PV-DMはWord2VecのCBOWに対応するようなアルゴリズムです。
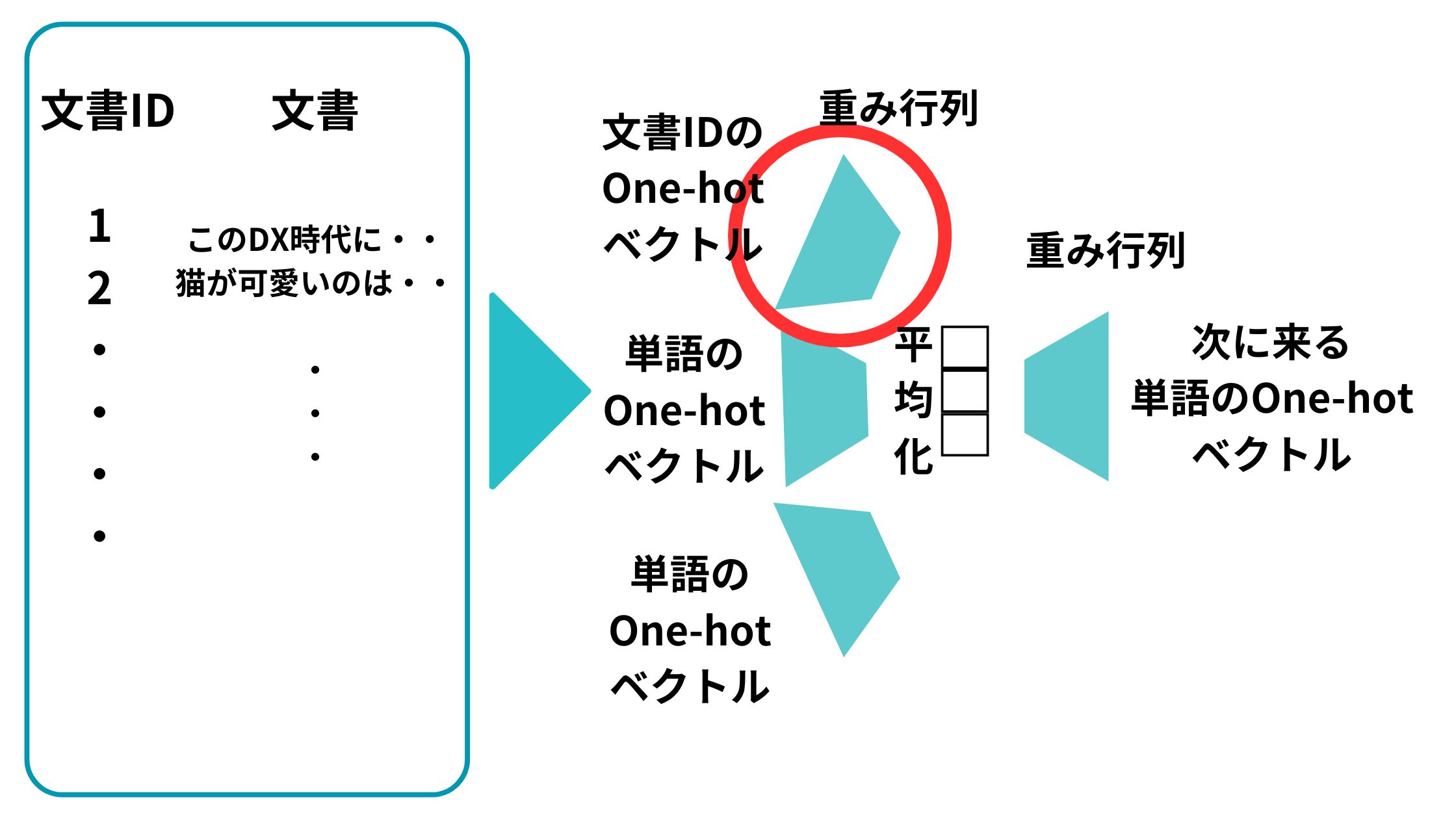
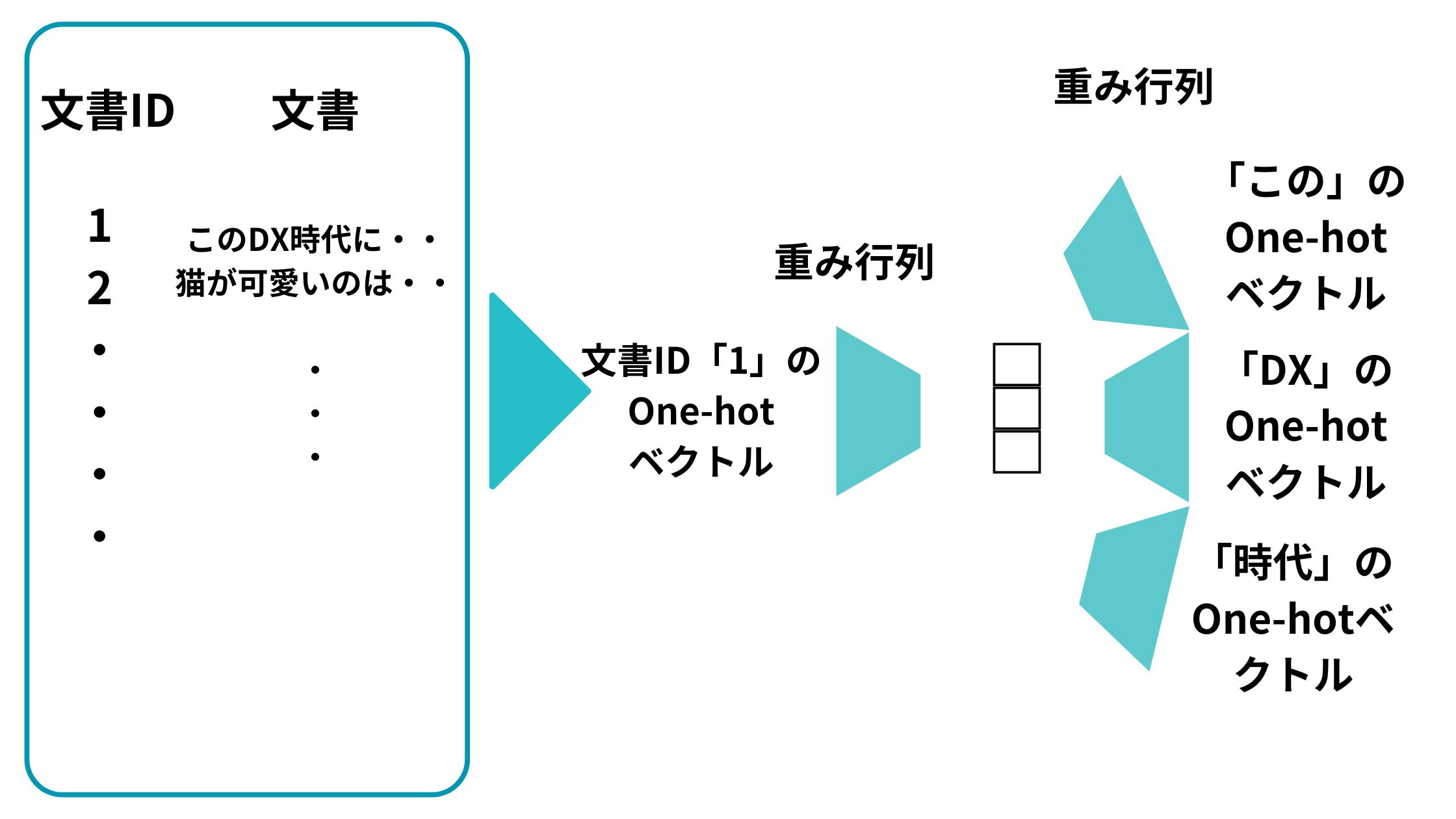
以下のように文書IDのone-hotベクトルと単語のone-hotベクトルをインプットとして投入して、それらを重みベクトルで圧縮したものを平均化して、重み行列で変換して次の単語を予測するニューラルネットワーク構造を構築します。
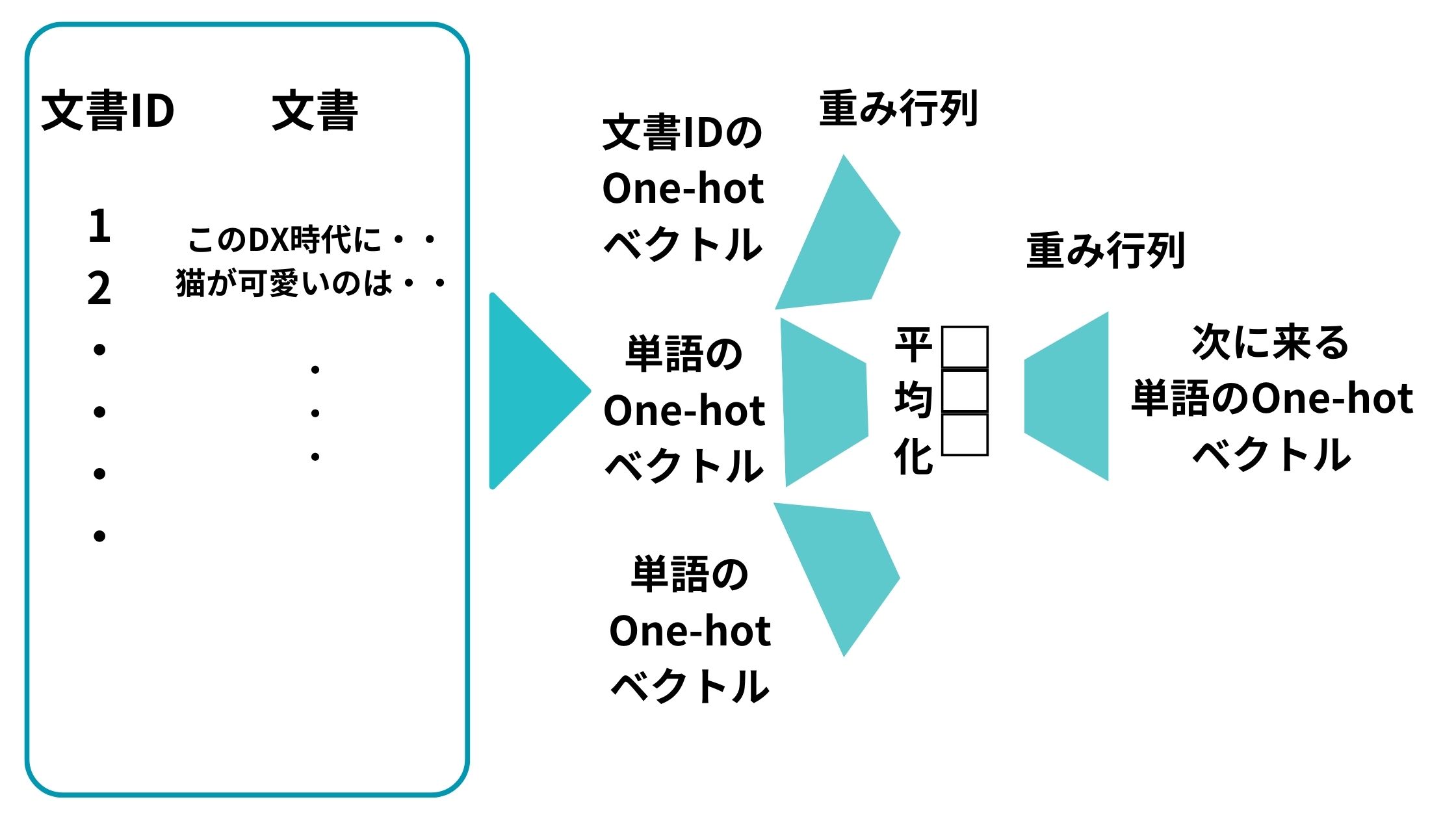
続いて、この予測問題を解くべく学習を進めます。
そして最終的に学習が進んだあとの文書IDのOne-hot ベクトルに対応する重み行列のベクトルがDoc2Vecで取得したい文書のベクトルになるんです。
この図で言うところの以下の部分のベクトルです。
例えば、文書ID「1」の場合は以下のようになります。
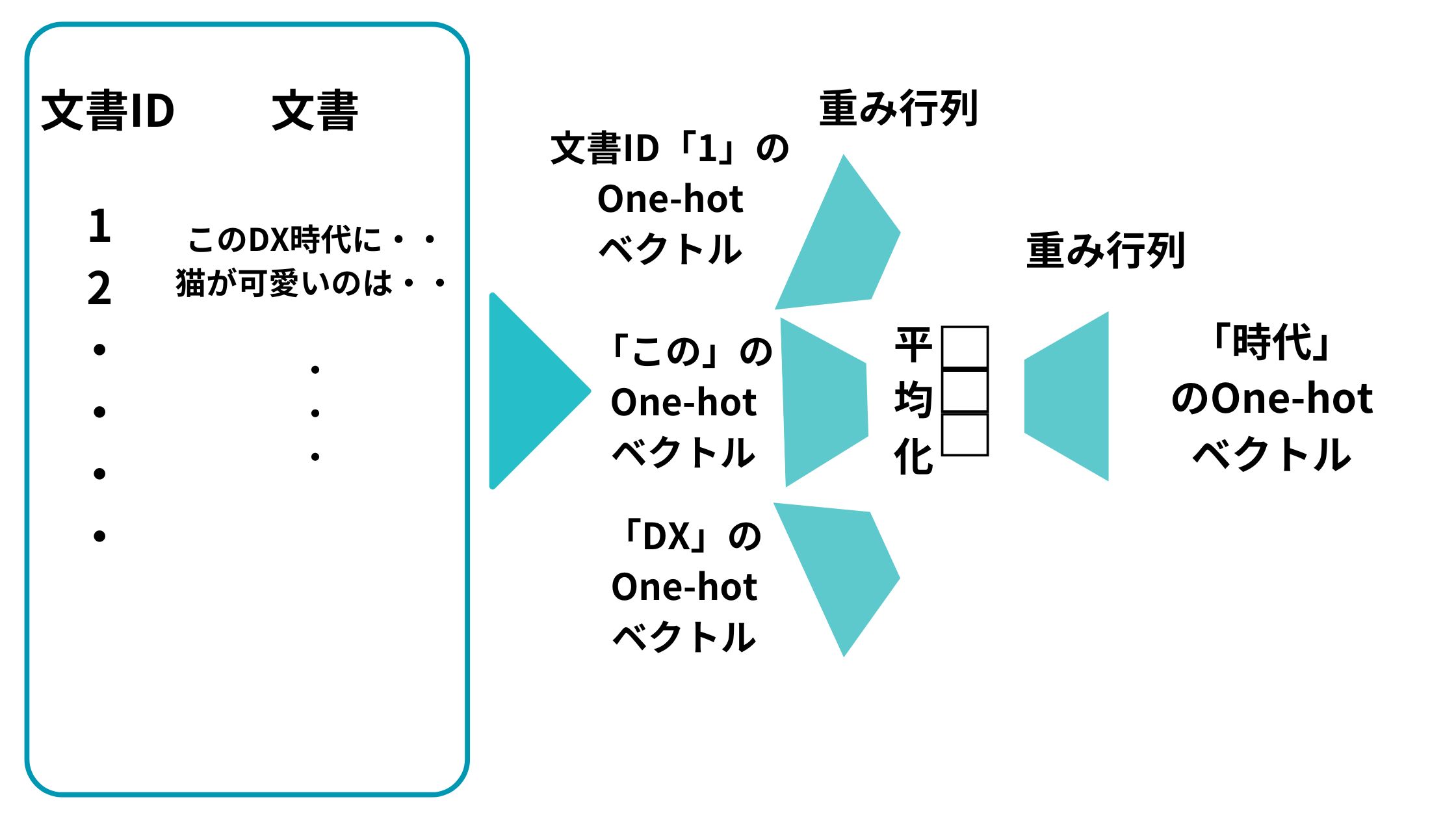
文書ID「1」のベクトルと「この」のベクトルと「DX」のベクトルを投入して「時代」のベクトルを予測するようなイメージになります。
ここらへんの話はWord2Vecと合わせて学ぶと分かりやすいと思うのでぜひWord2Vecも合わせて見てみてください。

PV-DBOW
続いてPV-DBOW!
こちらは、Word2Vecのskip-gramに対応するようなアルゴリズム。
文書IDのOne-hot ベクトルから特定の単語を予測するようなニューラルネットワークを構築してそれを解きます。
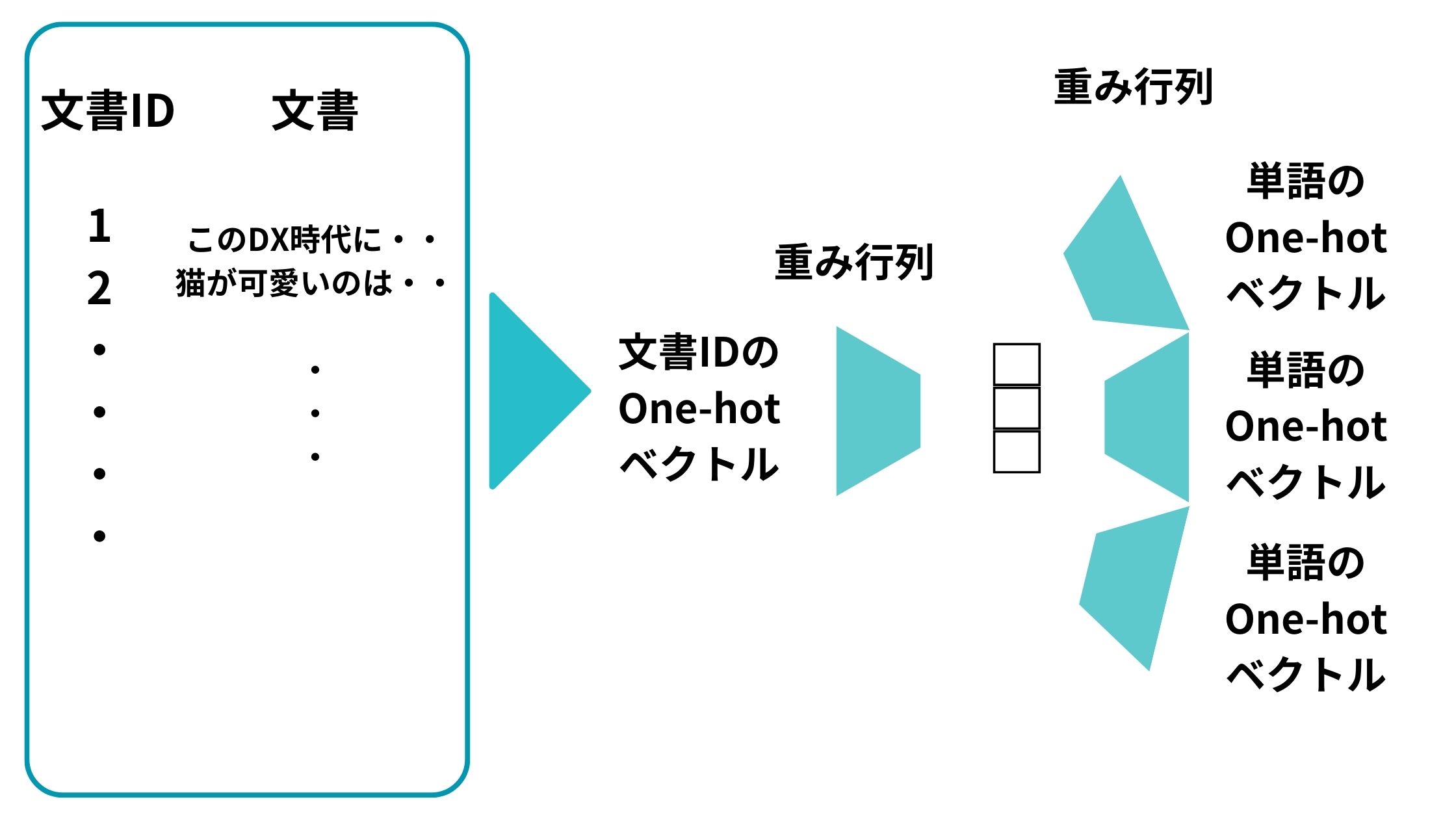
同様に、この予測問題を解くべく学習を進めた後の文書IDのOne-hot ベクトルに対応する重み行列のベクトルがDoc2Vecで取得したい文書のベクトルになるんです。
以下の部分ですね。
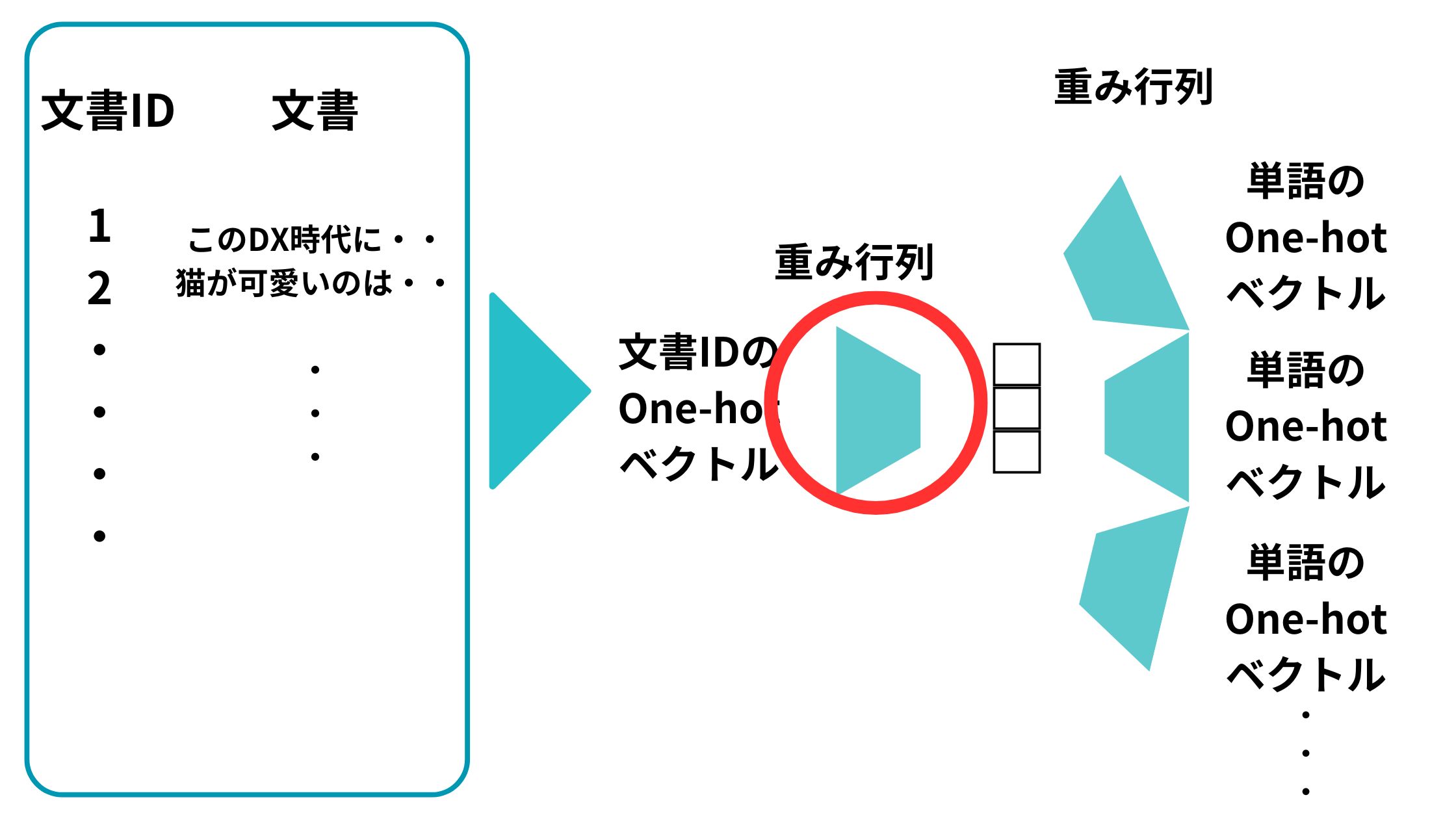
そして文書IDが1の場合は以下のようになり、最終的な出力ベクトルの単語は文書からピックアップした任意の単語になります。
一般的にPV-DBOWの方が学習速度は速いのですが、PV-DMの方が精度が高いと言われています。
Doc2VecをPythonで実装してみよう!
それでは続いてDoc2Vecを実際にPythonで簡単に実装していきましょう!
gensimというライブラリを使ってDoc2Vecを実装していきます。
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
import nltk
from nltk.tokenize import word_tokenize
nltk.download('punkt')
# サンプルデータ
data = ["I love machine learning",
"I love coding in Python",
"Machine learning is an exciting field",
"Python is a versatile programming language"]
# データをトークン化してTaggedDocument形式に変換
tagged_data = [TaggedDocument(words=word_tokenize(_d.lower()), tags=[str(i)]) for i, _d in enumerate(data)]
# モデルのパラメータを設定
max_epochs = 100
vec_size = 20
alpha = 0.025
model = Doc2Vec(vector_size=vec_size,
alpha=alpha,
min_alpha=0.00025,
min_count=1,
dm =1)
model.build_vocab(tagged_data)
# モデルの学習
for epoch in range(max_epochs):
print(f"Iteration {epoch}")
model.train(tagged_data,
total_examples=model.corpus_count,
epochs=model.epochs)
# 学習率の減少
model.alpha -= 0.0002
model.min_alpha = model.alpha
# 保存と読み込み
model.save("d2v.model")
# 保存したモデルをロード
model = Doc2Vec.load("d2v.model")
# 新しい文書に対するベクトルを推測
test_data = word_tokenize("I love coding with Python".lower())
v1 = model.infer_vector(test_data)
print(v1)これで以下のようにベクトルが出力されたはず!
[-0.02893877 0.0092387 -0.01232865 -0.02127847 0.00525628 -0.016203 0.0165593 0.00745648 0.02004363 0.00751371 0.00826285 -0.01215482 -0.00552002 -0.01216448 -0.02003857 -0.00662984 -0.02081434 0.00908031 -0.02296249 -0.00416257]
ちなみにライブラリgensimのDoc2Vecのパラメータdmに1を指定するとアルゴリズムとしてPV-DMを指定します。
今回はサンプルの文章を作成して簡易的に実装をおこなったのでベクトル化の精度は低いことが見込まれますので、本格的に実装する際は大規模の文書データセットを用いて学習を行うもしくは学習済みモデルを使用するとよいでしょう!
当メディアが運営する教育サービス「スタビジアカデミー」の自然言語処理コースでは、livedoorニュースのテキストを利用してDoc2Vecで学習していますので参考にしてみてください。

Doc2Vecまとめ
ここまでご覧いただきありがとうございました!
本記事ではDoc2Vecについて簡単に解説してきました!
Doc2Vecは2014年に登場したアプローチで、枯れた技術と思われがちですが理解しておくことは非常に大事です。
Doc2Vecを理解した上で他の自然言語処理アプローチもしっかりおさえておきましょう!
先ほどもお伝えしましたが、自然言語処理についてもっと詳しく知りたいという方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の自然言語処理講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!