検索で用いられるn-gramとは?形態素解析にも触れながら見ていこう!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事ではn-gramについて解説していきます!
n-gram自体は非常にシンプルですぐ理解できるのですが、検索システムを作る際にどういうところに気をつけるべきかなどまで理解しておくことが大事です。
この記事ではそんなn-gramについて形態素解析にも触れながら簡単に見ていきましょう!
以下の動画でも解説しているのであわせてチェックしてみてください!
n-gramとは
n-gramは文章を特定のまとまりごとにまとめてグループ化するアプローチです。
nには数字が入るようになっており、1-gram(ユニグラム)、2-gram(バイグラム)、3-gram(トリグラム)の3つのパターンがあります。
そして最小単位を文字にするか単語にするかの2パターンが存在します。
具体的にどんな分け方になるのか見ていきましょう!
最小単位が文字の場合
スタビジは面白いサイトだ
という文章があった時にそれを文字単位で分割すると
・1-gramの場合
ス/タ/ビ/ジ/は/面/白/い/サ/イ/ト/だ
となります。これはシンプルですね。
・2-gramの場合
スタ / タビ / ビジ / ジは / は面 / 面白 / 白い / いサ / サイ / イト / トだ
となります。2個ずつの文字が1つの塊になり、それぞれが1個ずつズレていることが分かります。
・3-gramの場合
では3-gramはどうなるでしょう?
スタビ / タビジ / ビジは / ジは面 / は面白 / 面白い / 白いサ / いサイ / サイト / イトだ
3文字ごとの塊になり1文字ずつズレていることが分かります。
最小単位が単語の場合
最小単位が単語の場合はどうなるでしょう?
まず、最小単位を単語にするには形態素解析をする必要があります。
例えば先ほど使った以下のような文書を形態素解析すると・・・
スタビジは面白いサイトだ
以下のようになります。
スタビジ / は / 面白い / サイト / だ
意味のある単語ごとに分かれているのが分かると思います。
これにn-gramを適用させると、以下のようになります。
・1-gram
(スタビジ) / (は) / (面白い) / (サイト) / (だ)
・2-gram
(スタビジ、は) / (は、面白い) / (面白い、サイト) / (サイト、だ)
・3-gram
(スタビジ、は、面白い) / (は、面白い、サイト) / (面白い、サイト、だ)
文字単位の場合とルールは変わらず最小単位だけが変わっているということが分かります。
形態解析に関しては以下の記事で詳しく解説しているので興味のある方はチェックしてみてください!

n-gramを検索でどう使う?
ここまでn-gramの定義について見てきましたが、ここからはn-gramを実際に使うシーンについて見ていきましょう!
n-gramは検索システムにおいて使うことが多いです。
大量の文章から特定のキーワードに基づいて文章を検索する際に、毎回毎回全ての文章に対して部分一致するものがあるかを調べにいくとものすごい時間がかかります。
そんな時に利用されるのが「n-gram」もしくは「形態素解析」によってインデックスをはっておくという作業なのです。
例えば先ほどの
スタビジは面白いサイトだ
という文書を文書1として形態素解析で分解してインデックスをはる場合は
以下のようにインデックスがはられます。
| スタビジ | 文書1 |
| は | 文書1 |
| 面白い | 文書1 |
| サイト | 文書1 |
| だ | 文書1 |
そして他の文書2として
データサイエンスは面白い
という文書があった場合、この文書は以下のように形態素解析で分解できるので、
データサイエンス / は / 面白い
文書1と文書2をあわせて以下のようにインデックスがはられることになります。
| スタビジ | 文書1 |
| は | 文書1, 文書2 |
| 面白い | 文書1, 文書2 |
| サイト | 文書1 |
| だ | 文書1 |
| データサイエンス | 文書2 |
このようにインデックスがはられた状態で、例えば「面白い」とキーワードを入れて検索してみると、文書1,2がどちらもヒットすることになります。
「面白いサイト」と調べると、「面白いサイト」自体を形態素解析した結果である「面白い」と「サイト」にインデックスがはられている文書1だけがヒットすることになります。
このようにインデックスをはることで検索精度を落とさずに高速に結果を表示することができるのです!!
しかしこの時、「面白サイト」みたいな検索をする人がいたとしましょう。このキーワードだと文書1はヒットしないのです。。。
そこでn-gramの出番!
2-gramで分解してインデックスをはる場合は以下のようになります。
| スタ | 文書1 |
| タビ | 文書1 |
| ビジ | 文書1 |
| ジは | 文書1 |
| は面 | 文書1 |
| 面白 | 文書1 |
| 白い | 文書1 |
| いサ | 文書1 |
| サイ | 文書1 |
| イト | 文書1 |
| トだ | 文書1 |
ここで「面白サイト」と検索された場合、前から順番に2文字抽出して「面白」「サイ」「イト」に引っかかる文書として文書1がヒットします!
検索キーワードである「面白サイト」を分解する際は2-gram分解ではなくて先頭から2文字ずつ抽出して最後だけ余るので「イ」を重複させて「イト」としています。
このようにn-gramを使うことで形態素解析よりも、検索キーワードを省略した場合に検索精度が高くなります。
ただ、その分検索にノイズが入りやすくなります。
ちなみに今回は「面白い」「サイト」の全てに一致するAND条件で検索するロジックや「面白」「サイ」「イト」の全てに一致するAND条件で検索するロジックで考えましたが、どちらかに一致するOR条件にすることも可能です。
そうすると検索ヒットの幅が大きく広がりますが、その分検索にノイズが入りやすくなります。
ここらへんは検索の精度や処理速度との相談になるかと思います。
ちなみに書籍まとめのサービス「Yomeru(ヨメル)」というものを開発しているのですが、こちらでは形態素解析とn-gramを使ってインデックスをはってAND条件で検索しています!
月間20万人くらいが使ってくれてるサービスで絶賛頑張って開発中なので是非使ってみてください!!
n-gramをPythonで実装!
ここまででn-gramの定義や使い方について解説してきました。
ここで、非常にシンプルですが、n-gramをPythonで実装するならどんなコードになるか見ていきましょう!
例えば
スタビジは面白いサイトだ
という文章に3-gramを適用させる場合は以下のようなコードになります。
text = "スタビジは面白いサイトだ"
n_grams = [text[i:i+3] for i in range(len(text)-2)]
n_grams
非常にシンプルなコードになっているのが分かりますね!
テキストの文字数を最大値として最大値に達するまでfor文で取り出してtextをスライスで塊に分けています。
これで
3-gramの
スタビ / タビジ / ビジは / ジは面 / は面白 / 面白い / 白いサ / いサイ / サイト / イトだ
というリストが取得できます。
n-gram まとめ
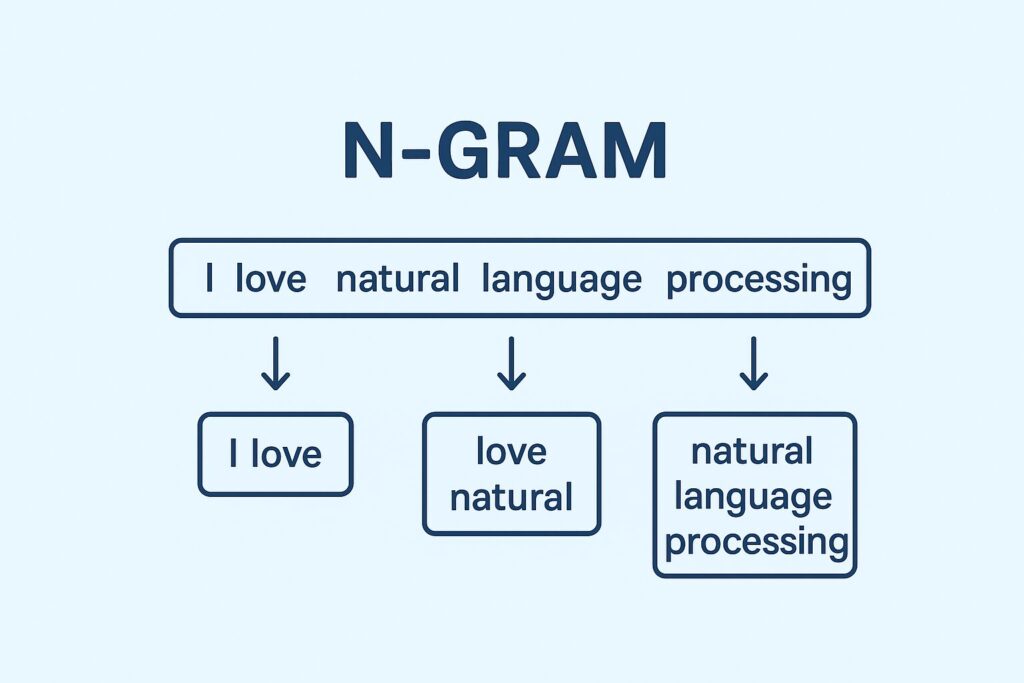
この記事ではn-gramの定義・使い方・Pythonでの実装方法についてまとめてきました。
n-gramの考え方はおさえておいていざとなった時に使えるようになっておきましょう!
さらに詳しく自然言語処理について勉強したい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスの「自然言語処理」コースで体系的に学ぶことが可能ですので是非参考にしてみてください!n-gramは取り上げていません。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!