
Pythonを使って文章に対して感情分析をしてくれるAIを作ってみよう!


こんにちは!スタビジ編集部です!
近年、SNSやレビューサイト、アンケートといった膨大なテキストデータから感情を分析して、マーケティングに活用する動きが増えてきています。
今回はそんな感情分析を”Python“を使って実装する方法について見ていきます!
「感情分析」を使うとより幅広い分析が出来るようになるよ!
ちなみに、Pythonで感情分析を使ったチャットボットを作る方法を知りたい方は以下のUdemyコースでうまたんが講師として教えていますので参考にしてみてください!
【初心者向け】Pythonで感情分析AIや大規模言語モデル(LLM)を使った様々な種類のチャットボットを作ろう!
| 【時間】 | 3時間 |
|---|---|
| 【レベル】 | 初級 |
Pythonで色々なチャットボットを作ってみたいならこれ!今なら購入時に「USTHVU4USSS6」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
感情分析については以下のYouTube動画でも解説していますので合わせてチェックしてみてください!
目次
感情分析とは
実装を行う前にまずは、「感情分析」について概要を見ていきます。
感情分析とは
「感情分析(Sentiment Analysis)」とはテキストや音声、顔の表情、生体情報から人の感情を判別する技術になります。
感情分析のメリットは以下です。
- 定性的なデータからユーザーの情報を可視化・定量化できる
- ユーザーの感情を測定することで、効果的な対応が可能になる
- テキストデータの場合、大量のデータから重要な情報を抽出できる
感情分析を行うことでユーザーが抱える潜在的な気持ちを効率的に理解し、マーケティングや企業の意思決定に役立てることが出来ます。
感情分析の利用例
実際どんな場面で感情分析が使われているのでしょうか。
感情分析の利用例は以下が挙げられます。
- カスタマーサービスで、感情分析AIは顧客の感情をリアルタイムで解析し、オペレーターが適切に対応できるよう支援
- 大手ECサイトで、感情分析活用により商品レビューを自動でカテゴリー分けし、顧客満足度の指標として経営判断に反映
- TwitterやInstagramなどSNS上の膨大な発言をリアルタイムに追跡し、世間の意見を可視化
Pythonで感情分析を行う方法
Pythonで感情分析を行うには大きく「ルールベース」と「機械学習ベース」の2つのアプローチが考えられます。
| ルールベース | 機械学習ベース |
|---|---|
| 概要 | |
事前に”ポジティブ単語辞書”と”ネガティブ単語辞書”を用意、文章中に含まれる単語を見つけるたびにスコアを加算・減算して感情を判定 | 「ポジティブ/ネガティブ」のラベルが付けられた学習データ(テキストと感情ラベル)を用意、分類器で学習したモデルを使って文章の感情を判定 |
| 利用のしやすさ | |
○ 辞書を用意すれば動作するため、実装がシンプル | △ 学習データの準備やモデルの開発に時間がかかる |
| 精度 | |
○ 言葉の頻出度合いで判定するので、直接的な表現を分析しやすい、一方で文脈理解に弱い | ◎ 大量の学習データを使い、単語の共起関係や文脈情報をモデルが学習するため、比較的柔軟な表現にも対応できる |
機械学習ベースはテスト文章を学習させて、文脈を踏まえた分析が出来るよ!
機械学習については以下の記事で解説しているのでチェックしてみて下さい。

Pythonで文章を感情分析してみる
ここからは実際にPythonを使って文章の感情分析を行っていきます。
今回はルールベースと機械学習の2つの方法をそれぞれ見ていきましょう。
本記事でのPythonの作業は「Jupyter Notebook」で行っています。
Jupyter NotebookはWebブラウザ上でPythonプログラムを書いて・実行出来る環境です。
プログラムの実行結果を毎回確認できるので初心者におすすめのツールになります。
Jupyter Notebookについて以下の記事で解説しているので、参考にしてみて下さい。

ルールベースの感情分析
ルールベースの感情分析を試していきましょう。
以下の方針で実装していきます。
・ポジティブ・ネガティブ辞書を用意
・入力された文章を形態素解析
・ルールベースで文章を感情評価
ポジティブ・ネガティブ辞書を用意
まずはルールベースの元になるポジティブ・ネガティブ辞書を作成していきます。
自分で辞書を作成してもいいですが、手間がかかるので、今回は東京工業大学の高村研究室で公開されている「単語感情極性対応表」を用いて作成していきます。
「単語感情極性対応表」は日本語や英語の単語に対して一般的に持つ印象(ポジティブ/ネガティブ)を数値化した一覧表になります。
ダウンロードした単語感情極性対応表を”dic.txt”としてローカルにダウンロードし、Pythonに取り込みます。
import MeCab
import os
# ================================
# 1. dic.txt を読み込み、単語スコア辞書を生成する
# ================================
def load_score_dictionary(dic_path: str):
"""
dic.txt の各行は「表層形:読み:品詞:スコア」の4列想定。
例: 優れる:すぐれる:動詞:1
良い:よい:形容詞:0.999995
読み込み後、{表層形: スコア(float)} という dict を返す。
"""
scores_map = {}
if not os.path.exists(dic_path):
print(f"ファイルが見つかりません: {dic_path}")
return scores_map # 空のまま返す
with open(dic_path, "r", encoding="utf-8") as f:
for line in f:
line = line.strip()
if not line:
continue # 空行スキップ
parts = line.split(":")
if len(parts) != 4:
# 想定通り「4列」になっていない場合はスキップ or ログ出力など
continue
surface, reading, pos, score_str = parts
try:
score = float(score_str)
except ValueError:
# 数値変換できなければスキップ
continue
scores_map[surface] = score
return scores_map
ダウンロードしたファイルから”scores_map”という辞書型配列に単語・スコアの組み合わせを追加していきます。
入力された文章を形態素解析
次にユーザーから入力された文章を「形態素解析」します。
「形態素解析」とは、文章を意味を持つ最小単位(形態素)に分割し、品詞などを判別する方法になります。
自然言語処理(NLP)の一種で、Pythonでは「MeCab」や「PyKNP」といったライブラリで形態素解析を行うことが出来ます。
「MeCab」については以下の記事で詳しく解説しているので、参考にしてみて下さい。

形態素解析で文章を解析する関数は以下になります。
# ================================
# 2. 形態素解析で文章を分割する関数
# ================================
def tokenize_japanese_text(text: str):
"""
MeCab を使って日本語文章を形態素解析し、
表層形(単語)だけのリストを返す。
"""
tagger = MeCab.Tagger("")
parsed = tagger.parse(text)
tokens = []
for line in parsed.split("\n"):
if line == "EOS" or line == "":
break
# MeCabの出力は「表層形\t品詞情報...」の形式
surface = line.split("\t")[0]
tokens.append(surface)
return tokens
受け取ったメッセージを形態素解析し、分解した形態素を”tokens”に格納していきます。
ルールベースで文章を感情評価
ここでは形態素解析した結果とポジティブ・ネガティブ辞書を突き合わせて、感情スコアを算出します。
# ================================
# 3. ルールベースの感情分析を行う関数
# ================================
def rule_based_sentiment_analysis(text: str, scores_map) -> float:
"""
文章を形態素解析で分割して、
- dic.txt 由来の scores_map から該当単語のスコアを取得
- すべて合計して返す
"""
tokens = tokenize_japanese_text(text)
total_score = 0.0
for token in tokens:
if token in scores_map:
total_score += scores_map[token]
return total_scorefor文のところで分解した単語がポジティブ・ネガティブ辞書に当てはまるか確認し、当てはまる場合はスコアを抽出して加算する流れになります。
実行結果
実際にこれらの関数を動かすため、メイン関数を作成し、実行してみます。
メイン関数は以下の通りです。
# ================================
# 4. メイン処理
# ================================
def main():
dic_path = "dic.txt" # dic.txt のパス
# dic.txt から単語スコアの辞書を作成
scores_map = load_score_dictionary(dic_path)
if not scores_map:
print("dic.txt の読み込みに失敗、または中身がありません。")
return
print("=== ルールベース感情分析 ===")
print("文章を入力してください。終了する場合は exit と入力してください。")
while True:
user_input = input("\n文章: ")
if user_input.lower() == "exit":
print("終了します。")
break
# --- 4-2. 感情分析を実行 ---
score = rule_based_sentiment_analysis(user_input, scores_map)
# --- 4-3. スコアから感情を判定 ---
# 閾値は例として 0 を境に、プラス/マイナス判定
if score > 0:
sentiment_label = "ポジティブ"
elif score < 0:
sentiment_label = "ネガティブ"
else:
sentiment_label = "ニュートラル"
# --- 4-4. 結果を表示 ---
tokens = tokenize_japanese_text(user_input)
print(f"スコア合計: {score} -> 判定: {sentiment_label}")
if __name__ == "__main__":
main()
メイン関数ではポジティブ・ネガティブ辞書を作成し、ユーザーからの入力を受け付けます。
受け付けられた文章を感情分析し、結果を表示する処理を行っています。
プログラムを動かした結果を見ていきましょう。

狙い通り、ポジティブな文章はポジティブにネガティブな文章はネガティブに分類されています。
一方でポジティブな意見とネガティブな意見を混ぜた場合はどちらかの意見によってしまうことが多いです。
作成した辞書内での言葉の点数によってポジティブ・ネガティブ度合いが変化するため、閾値やスコアの算出方法をいろいろ変えてみて下さい。
# --- 4-3. スコアから感情を判定 ---
# ニュートラルの幅を広げる
if score >= 0.5:
sentiment_label = "ポジティブ"
elif score <= -0.5:
sentiment_label = "ネガティブ"
else:
sentiment_label = "ニュートラル"上記はスコアから感情判定する際の閾値を調整してニュートラルの意見を取り込みやすくした例になります。
機械学習ベースの感情分析
機械学習ベースの感情分析を試していきましょう。
以下の方針で実装していきます。
・データセットを用意
・特徴量の抽出
・感情分析モデルの作成
データセットを用意
感情分析に使うデータセットを用意します。
今回は「Hugging Face」で公開されている「Amazonのレビューデータ」をデータセットとして利用します。
from datasets import load_dataset
# データセットのロード
dataset = load_dataset("SetFit/amazon_reviews_multi_ja")
# 訓練データ、検証データ、テストデータの取得
train_data = dataset['train']
validation_data = dataset['validation']
test_data = dataset['test']データセットはHugging Faceの”datasets“ライブラリを使うことで簡単にロードできます。
続いて、収集したデータを学習しやすくするように前処理を行います。
import re
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report
from sklearn.model_selection import train_test_split
import numpy as np
import pandas as pd
import fugashi
# ストップワードの定義
stop_words = set(["の", "に", "は", "を", "た", "が", "で", "て", "と", "し", "れ", "さ", "ある", "いる", "も", "する", "から", "な", "こと", "として", "い", "や", "れる", "ない", "よう", ""])
# テキストの前処理関数
def preprocess_text(text):
# 小文字化
text = text.lower()
# 数字の置換
text = re.sub(r'\d+', '0', text)
# 記号の除去
text = re.sub(r'[^\w\s]', '', text)
return text
# 形態素解析器の初期化
tagger = fugashi.GenericTagger("-Owakati -d 'C:\Program Files (x86)\MeCab\dic\ipadic'")
# トークン化関数
def tokenize(text):
return [token.surface for token in tagger(text) if token.surface not in stop_words]
# データフレームに変換
train_df = pd.DataFrame(train_data)
validation_df = pd.DataFrame(validation_data)
test_df = pd.DataFrame(test_data)
# テキストの前処理
train_df['text'] = train_df['text'].apply(preprocess_text)
validation_df['text'] = validation_df['text'].apply(preprocess_text)
test_df['text'] = test_df['text'].apply(preprocess_text)
# トークン化
train_df['tokens'] = train_df['text'].apply(tokenize)
validation_df['tokens'] = validation_df['text'].apply(tokenize)
test_df['tokens'] = test_df['text'].apply(tokenize)
# トークンをスペースで結合
train_df['processed_text'] = train_df['tokens'].apply(lambda x: ' '.join(x))
validation_df['processed_text'] = validation_df['tokens'].apply(lambda x: ' '.join(x))
test_df['processed_text'] = test_df['tokens'].apply(lambda x: ' '.join(x))日本語の助詞を学習から省くため、ストップワードを設定し、形態素解析で分解した単語(トークン)から除く処理をしています。
また、”preprocess_text”関数で感情分析の統一性を確保するため、小文字化や数字の変換を行っています。
特徴量の抽出
前処理したテキストデータを機械学習モデルが理解できる数値に変換するため、「特徴量の抽出処理」を行います。
# TF-IDFベクトライザーの定義
vectorizer = TfidfVectorizer()
# 訓練データの特徴量抽出
X_train = vectorizer.fit_transform(train_df['processed_text'])
y_train = train_df['label']
# 検証データの特徴量抽出
X_validation = vectorizer.transform(validation_df['processed_text'])
y_validation = validation_df['label']
# テストデータの特徴量抽出
X_test = vectorizer.transform(test_df['processed_text'])
y_test = test_df['label']特徴量の抽出には”TF-IDF“という手法を用いて行います。
TF-IDFについては以下の記事で詳しく解説しているので、参考にしてみて下さい。
感情分析モデルの作成
成形したテストデータを元にモデルの訓練を行います。
# モデルの定義
model = MultinomialNB()
# モデルの訓練
model.fit(X_train, y_train)今回は単語ごとの出現確率を考慮して分類を行うため、”ナイーブベイズ“をモデルとして使用します。
# モデルの定義
model = MultinomialNB()
# モデルの訓練
model.fit(X_train, y_train)ナイーブベイズについては以下の記事で詳しく解説しているので、参考にしてみて下さい。

検証データを使ってモデルの評価を実施します。
# 検証データでの予測
y_pred_validation = model.predict(X_validation)
# 精度の表示
print("Validation Accuracy:", accuracy_score(y_validation, y_pred_validation))
# 分類レポートの表示
print("Validation Classification Report:")
print(classification_report(y_validation, y_pred_validation))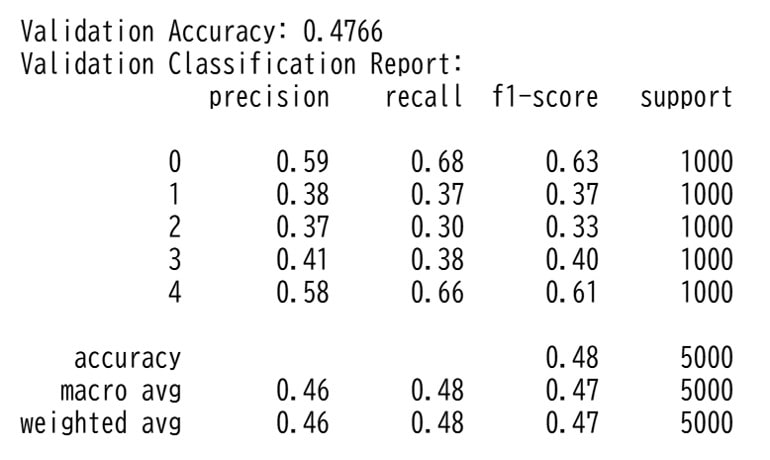
今回はレビュー内容から満足度(0~5)を予測しています。
そのため、学習データを増やしたり、満足度を3段階(良い・普通・悪い)に分けることで精度を向上させられます。
実行結果
作成したモデルを使って、新しいレビューから満足度を分析します。
新しいレビューも分析のためにデータ処理を行ってから実施します。
import re
import fugashi
from sklearn.feature_extraction.text import TfidfVectorizer
# 形態素解析器の初期化
tagger = fugashi.GenericTagger("-Owakati -d 'C:\Program Files (x86)\MeCab\dic\ipadic'")
# **前処理関数**
def preprocess_text(text):
text = text.lower() # 小文字化
text = re.sub(r'\d+', '0', text) # 数字の統一
text = re.sub(r'[^\w\s]', '', text) # 記号削除
return text
# **トークン化関数**
def tokenize(text):
return ' '.join([token.surface for token in tagger(text)])
# **新しいレビュー**
new_reviews = [
"この商品はとても良い!使いやすくて満足しています。",
"最悪の体験でした。二度と買いません。",
"デザインは素敵だけど、機能がイマイチ。",
"価格以上の価値があると思います!また購入します。",
"品質が悪く、すぐに壊れました。返品したい。"
]
# **前処理とトークン化**
new_reviews_processed = [tokenize(preprocess_text(review)) for review in new_reviews]
# **TF-IDFベクトルに変換**
new_reviews_vectorized = vectorizer.transform(new_reviews_processed)
# **予測**
predictions = model.predict(new_reviews_vectorized)
# **結果の表示**
for review, sentiment in zip(new_reviews, predictions):
print(f"Review: {review}")
print(f"Predicted Sentiment: {sentiment}\n")
実行結果は下記になります。

レビューから推測できる満足度結果と機械学習ベースの結果はあっているように見えます。
感情分析を使う場面に合わせて、機械学習モデルを変えていこう!
Pythonで感情分析 まとめ
Pythonで感情分析を実装していきました。
感情分析のメリットをおさらいすると以下です。
- 定性的なデータからユーザーの情報を可視化・定量化できる
- ユーザーの感情を測定することで、効果的な対応が可能になる
- テキストデータの場合、大量のデータから重要な情報を抽出できる
いろんなPythonのアプリに組み込んでみよう!
別のAIを実装してみたい方は以下の記事をチェックしてみて下さい。
・LangChain・LangGraphを使ったAIエージェントの作り方を分かりやすく解説!
・自分の声のクローンを音声AIで生成してPythonから呼び出して使う方法!
・【初心者向け】ドル円予想AIをPythonを使って構築してみよう!
また、初心者だけど本格的にPythonでアプリ開発をやってみたい方は、当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」を以下の講座チェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















