
Pandasより優秀!?Pyhonでデータ加工集計するならPolars!


こんにちは!データサイエンティストのウマたん(@statistics1012)です。
Pythonでデータ加工集計をするとなるとよく使われるPandasですが、データ量が多くなると処理が極端に重くなってしまうのです。
そんな時に非常に便利なのがPolarsというライブラリ。
この記事では、そんなPolarsというライブラリの仕様や書き方にフォーカスして見ていきたいと思います!
もっと詳しくPolarsについて知りたい方は以下のUdemyのコースで私が解説していますのでチェックしてみてください!
【初心者向け】PythonのPolarsを使ってデータ加工集計・データ分析を高速化!Pandasと比較してみよう!
| 【時間】 | 3時間 |
|---|---|
| 【レベル】 | 初級 |
Pythonの高速化ライブラリであるPolarsについて知りたいならこのコース!
今なら購入時に「ZEJ2UK7YVZFV」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
以下のYoutube動画でも解説していますので合わせてチェックしてみてください!
PolarsとPandasの違い
それではまずPolarsと定番のPandasとの違いについて見ていきましょう!
処理の速さ
PolarsはRustというプログラミング言語で書かれているため、Pandasよりも処理が高速になっています。
大体の処理でPolarsの方が早いですが、Pandasの方が早い場合も少なからずあります。
またPandasはデータをメモリに読み込んでから処理するため、大量のデータを扱う際はメモリ不足に陥ってしまうことがある一方で、Polarsであればその心配がいりません。
書き方の差異
PandasとPolarsでは、書き方が若干変わってきます。
例えば以下のようなデータセットがあったとしましょう。
import pandas as pd
df = pd.DataFrame({
"department": ["HR", "HR", "IT", "IT", "IT"],
"salary": [40000, 45000, 60000, 70000, 65000]
})特定のユーザーの部門と給与データが格納されているデータです。
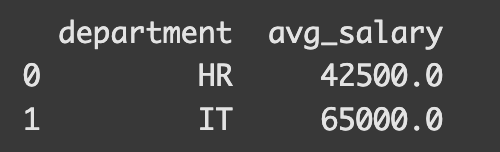
この時、各部門ごとの平均給与を計算するにはどうすればよいでしょうか?
Pandasだと以下のように書くことができます。
agg = df.groupby("department")["salary"].mean().reset_index()
agg.rename(columns={"salary": "avg_salary"}, inplace=True)
print(agg)
まずgroupbyで部門ごとの給与を計算し、それらの平均を取りインデックスをリセットしてカラム名を修正しています。
結果は以下のようになりました。
それでは、これと同じ処理をPolarsで行うとどのようになるのでしょうか?
まずデータフレームの作成はPandasとほぼ同じコードで実装することができます。
import polars as pl
df_pl = pl.DataFrame({
"department": ["HR", "HR", "IT", "IT", "IT"],
"salary": [40000, 45000, 60000, 70000, 65000]
})
そして、こちらに対して以下のようにコードを記述することで同様の処理を実装することができるのです
agg = df_pl.group_by("department").agg(
pl.col("salary").mean().alias("avg_salary")
)
print(agg)
この時、Polarsの場合はgroupbyがgroup_byになっていることに注意してください。
記述方法が若干違いますが、慣れるとPolarsの方がシンプルでよいかなとも思います。
aggメソッドの中で対象のカラムをpl.colで指定してmean()を取りカラムをaliasで修正しているんですねー。
結果はこのようになりました。

集計結果は同じですが、表現の仕方が変わっているのが分かると思います。
リファレンスの多さや安定性
ここまで見てくるとどうしてもPolarsの方がよさそうな気がしてきますが、やはりPandasの方が圧倒的に情報が多く安心感があります。
またライブラリとしての安定性もPandasの方が高く、今のところは出来ることの幅もPandasに分があるようです。
Polarsで様々な集計処理を実装してみよう!
それではPandasとの違いが分かったところで、Polarsで様々な集計処理を実装してみましょう!
今回使うデータは、そこそこレコード数の多い1000万行のデータ。
まずは今回使うデータを以下のように作成して、それぞれデータフレームに格納しておきましょう!
import pandas as pd
import polars as pl
import time
import numpy as np
# サンプルデータの作成
rows = 10000000 # 1000万行のデータ
data = {
"id": np.arange(rows),
"value1": np.random.randint(0, 100, rows),
"value2": np.random.randint(0, 100, rows),
"category": np.random.choice(["A", "B", "C", "D"], rows)
}
# Pandasデータフレーム
df_pd = pd.DataFrame(data)
# Polarsデータフレーム
df_pl = pl.DataFrame(data)1000万行のデータに対して、2つの量的変数と1つの質的変数と乱数で与えています。
フィルタリング
まずはデータをフィルタリングする処理。
# Pandas
start = time.time()
filtered_pd = df_pd[df_pd["value1"] > 50]
elapsed = time.time() - start
print(f"Pandas Filtering: {elapsed:.4f} seconds")
# Polars
start = time.time()
filtered_pl = df_pl.filter(pl.col("value1") > 50)
elapsed = time.time() - start
print(f"Polars Filtering: {elapsed:.4f} seconds")Polarsではfilterメソッドを使うことで条件を絞り込むことができます。
結果は以下のようになりました。
Pandas Filtering: 0.2446 seconds
Polars Filtering: 0.1491 seconds
Polarsの処理の方が早いことが分かります。
ちなみにPythonではqueryメソッドを使うことで様々な条件式を書いて絞り込むことができるのですが、queryメソッドを使うとどうなるでしょうか?
start = time.time()
filtered_pd = df_pd.query("value1 > 50")
elapsed = time.time() - start
print(f"Pandas Filtering: {elapsed:.4f} seconds")結果は以下のようになり、Pandasの処理がさらに遅くなっているのが分かりますね!
Pandas Filtering: 0.3478 seconds
グループ化と集計
続いて先ほども紹介したグループ化と集計を見ていきましょう!
以下のように記載してください。
# Pandas
start = time.time()
grouped_pd = filtered_pd.groupby("category")["value2"].mean()
elapsed = time.time() - start
print(f"Pandas Grouping and Aggregation: {elapsed:.4f} seconds")
# Polars
start = time.time()
grouped_pl = filtered_pl.group_by("category").agg(pl.col("value2").mean().alias("mean_value2"))
elapsed = time.time() - start
print(f"Polars Grouping and Aggregation: {elapsed:.4f} seconds")結果は以下のようになりました。
Pandas Grouping and Aggregation: 0.4294 seconds
Polars Grouping and Aggregation: 0.3724 seconds
若干ですが、Polarsの方が速いことが分かります。
今回は1000万レコードのデータを使っているのでこのような結果となりましたが、データが少ないと、このグループ化の処理に関してはPandasの方が速くなる可能性が高いです。
列の追加処理
続いてデータフレームに列を追加する処理を見ていきましょう!
# Pandas
start = time.time()
df_pd["new_col"] = df_pd["value1"] + df_pd["value2"]
elapsed = time.time() - start
print(f"Pandas Adding Column: {elapsed:.4f} seconds")
# Polars
start = time.time()
df_pl = df_pl.with_columns((pl.col("value1") + pl.col("value2")).alias("new_col"))
elapsed = time.time() - start
print(f"Polars Adding Column: {elapsed:.4f} seconds")
これを見るとPandasの方が直感的に分かりやすく、Polarsは少し複雑になっていますねー。
処理時間は以下のようになりました。
Pandas Adding Column: 0.1100 seconds
Polars Adding Column: 0.0795 seconds
こちらもPolarsに分があるようです。
ソート
続いてソートの処理を見ていきましょう!
start = time.time()
sorted_pd = df_pd.sort_values(by="value1")
elapsed = time.time() - start
print(f"Pandas Sorting: {elapsed:.4f} seconds")
start = time.time()
sorted_pl = df_pl.sort("value1")
elapsed = time.time() - start
print(f"Polars Sorting: {elapsed:.4f} seconds")
Polarsの方がコードがシンプルで分かりやすくなってますね。
結果は以下のようになりました。
Pandas Sorting: 3.1892 seconds
Polars Sorting: 2.8915 seconds
やはりPolarsの方が速いです。
ここまででいくつかデータ加工集計処理について見てきましたが、Pandasでの様々なデータ加工集計に興味のある方は以下の記事をチェックしてみてください!

Polars まとめ
ここまでご覧いただきありがとうございました!
本記事では、Pythonのデータ加工集計処理のライブラリであるPolarsについて解説してきました!
Pandasに慣れている方がPandasの方は、よいと感じる場面も多いと思いますが、処理の遅さに課題を感じていたり、メモリ不足で処理が回らない場合などは、ぜひPolarsを使ってみて下さい!
冒頭でもお伝えしましたが、もっと詳しくPolarsについて知りたい方は以下のUdemyのコースで私が解説していますのでチェックしてみてください!
【初心者向け】PythonのPolarsを使ってデータ加工集計・データ分析を高速化!Pandasと比較してみよう!
| 【時間】 | 3時間 |
|---|---|
| 【レベル】 | 初級 |
Pythonの高速化ライブラリであるPolarsについて知りたいならこのコース!
今なら購入時に「ZEJ2UK7YVZFV」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください!
また、さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















