zero shot, one shot , few shot learning について解説!ファインチューニングとの違いとは?


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回は最近話題のGPTモデルなどのAIブームでよく聞くようになったzero shot(ゼロショット), one shot(ワンショット) , few shot (フューショット)learningについて解説していきたいと思います。
GPTモデルにおけるzero shot(ゼロショット), one shot(ワンショット) , few shot (フューショット)learningとはどんなアプローチなのでしょうか?
同時によく使用されるファインチューニングとの違いについても解説していきます!
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
目次
zero shot, one shot , few shot learningとは
これらの概念は以下のGPT-3の論文で登場します。
他の論文でも同様の言及はありますが、ここではあくまでGPTモデルの論文におけるzero shot, one shot , few shot learningについて解説していきます。
GPTモデルの詳しい解説については以下の記事で取り上げておりますのでこちらを参考にしてください!

この論文では以下のように各種zero shot, one shot , few shot learningについて記述があります。
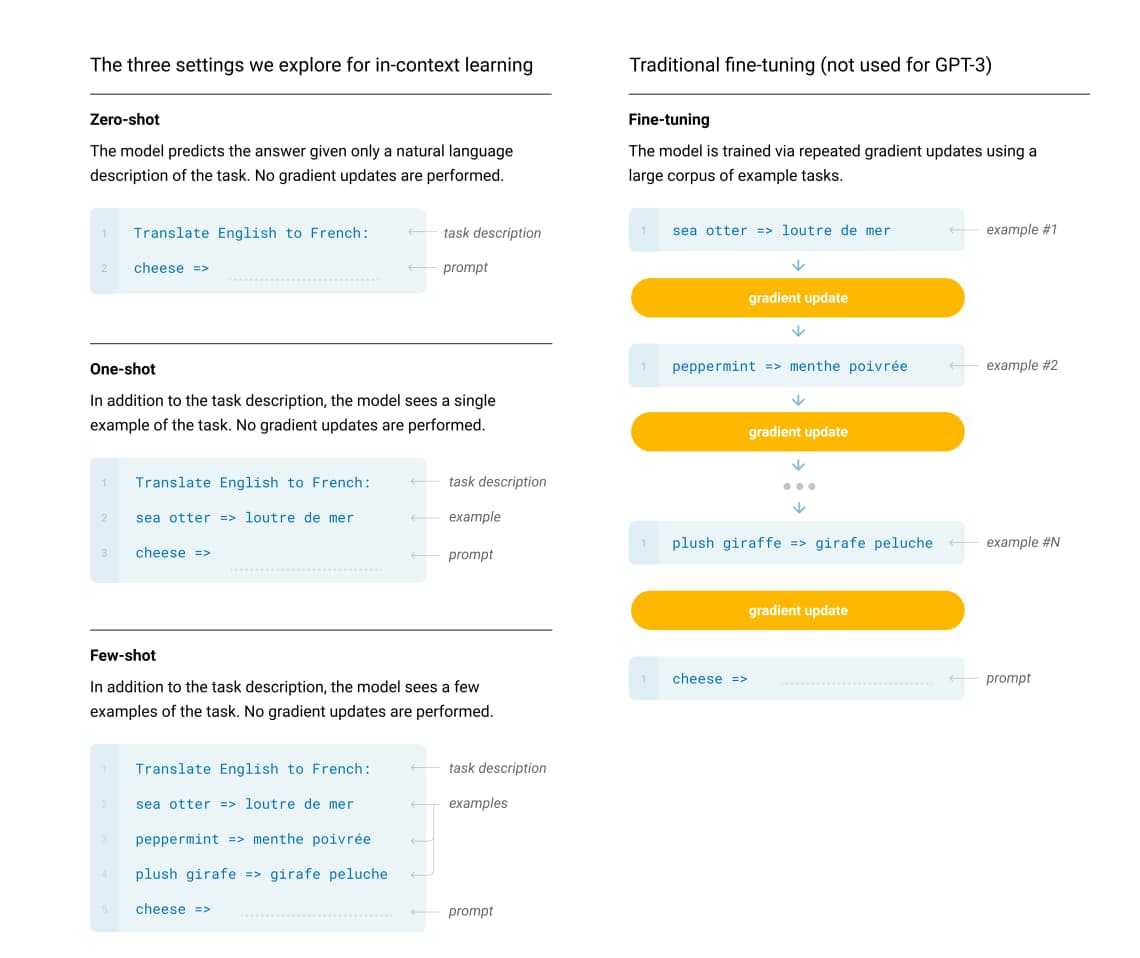
それぞれについて見ていきましょう!
zero shot
zero shotはその名の通り、何も追加情報を与えずに指示出しだけで回答を得ようとするアプローチです。
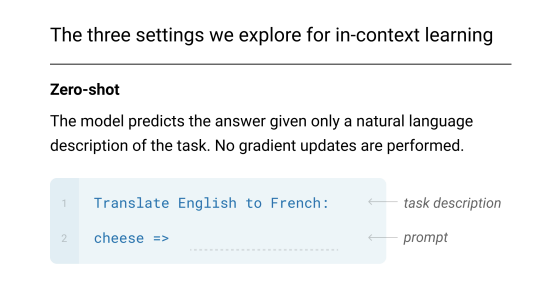
画像の例だと英語からフランス語に翻訳してという指示出しに対して特に翻訳の例を与えることなくチーズに対して翻訳を求めています。
これがzero shot
one shot
続いてone shotは、1つだけ例を与えてあげるアプローチです。

こちらも英語をフランス語に翻訳してと指示出しをしていますが、その後にsea otter => loutre de merという英語 => フランス語の例文を1つ入れてあげてます。
わかりにくいのですが、sea otterとはラッコのことです。これをフランス語に訳した例を1つインプットしてあげてます。
few shot
そしてfew shotは複数の例を与えてあげるアプローチです。

こちらは3つの例を記載して指示出しをしていることが分かります。
一般的には例を入れてあげた方がもちろん精度は上がりますが、GPT-3ではzero shotでもだいぶ良い精度を出力します。

以前やったのは、大量の小カテゴリを大カテゴリに分類する時にまず最初にある程度目検で人間が分類してそれらをインプットしてあげた上でfew shot learningで残りのカテゴリをGPTモデルに分類してあげるというものです。
zero shot, one shot , few shot learningとファインチューニングの違いとは?
さて、ここで疑問が生じるのがzero shot, one shot , few shot learningとファインチューニングとの違いです。
ファインチューニングでは新しいデータセットを用意してそれを元に再学習させることでモデルの重み自体も更新していくのです!
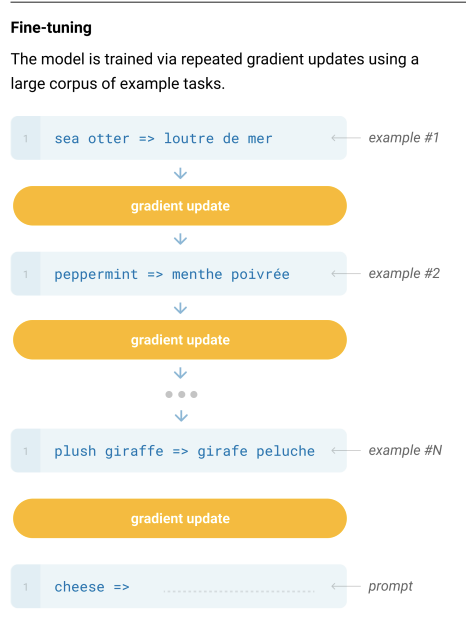
一方で、one shot , few shot learningは、モデルの重みは更新しません。
あくまでモデルへの指示出しの際にヒントとなる例を入れてあげるだけです。
ファインチューニングについては以下の記事で詳しく解説していますので是非チェックしてみてください!

ちなみにGPT-3より以前は色んなタスクに対して精度を高めるために各タスクに特化したファインチューニングが必要でした。
翻訳タスクでは通常、日本語と英語の文章の組み合わせを用意してそれらをもとに翻訳タスク用にファインチューニングしていく必要がありました。
しかしあまりにも大量のテキストデータから学習した事前学習モデルであれば、「英語に翻訳して」という文章の後に確率的に近づく言葉をつないでいったら翻訳タスク的なことができるようになったのです。
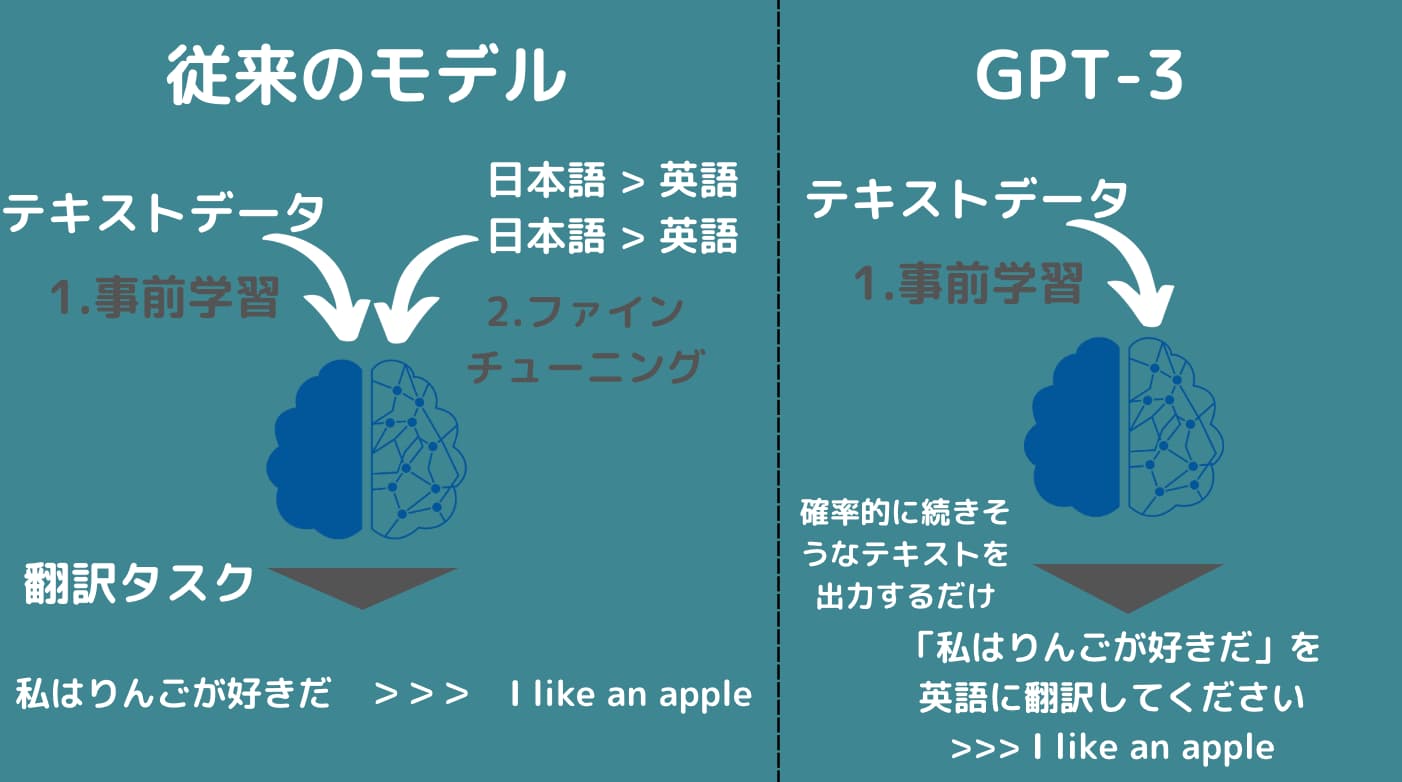
とはいえまだまだファインチューニングが必要な場面はありますし、モデルに適切なアウトプットを出してもらうためのone shot , few shot learningも有用です。
zero shot learning, one shot learning, few shot learning まとめ
ここまでで、AI分野において非常に重要な「zero shot learning, one shot learning, few shot learning」についてまとめてきました!
最近話題のAIについてより詳しくは当メディアが運営するスタアカの以下のコースを是非チェックしてみてください!
GPTモデルをはじめとした大規模言語モデルの理論やPythonでの扱い方などを幅広く学んでいきます!
スタアカは業界最安級のAIデータサイエンススクールです。

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組みあわせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
AIデータサイエンスを学んで市場価値の高い人材になりましょう!
データサイエンスやAIの勉強方法は以下の記事でまとめています。


 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!