
アップリフトモデリング(Uplift modeling)について分かりやすく解説!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!


そんなマーケティングコミュニケーションの悩みを解決してくれるのが
「アップリフトモデリング(Uplift modeling)」

この記事では、そんなアップリフトモデリングについて簡単に解説していきたいと思います!
本当に意味のある施策を行うためにぜひアップリフトモデリングをマスターしましょう!
以下のYoutube動画でも分かりやすく解説しています!
アップリフトモデリングとは

まずはじめに、そもそもアップリフトモデリングとは何なのか見ていきましょう!
アップリフトモデリングとは、マーケティング施策を効率化するためにターゲティング精度を高める手法です。
例えば、ECサイトで顧客の購買促進のためにクーポンを配るとしましょう!
出来るだけ効率よく効果を最大化してクーポンを配りたい。
しかし、クーポンを配布しなくても購入してくれるお客様には配布したくないですよね?
また、クーポンの場合はなかなかないとは思いますがクーポンを配布したら逆に購入しなくなってしまうお客様にはもちろんクーポンを配りたくないですよね?
クーポン配布の有無での購買有無は4つのセグメントで以下のように分けることが出来ます。
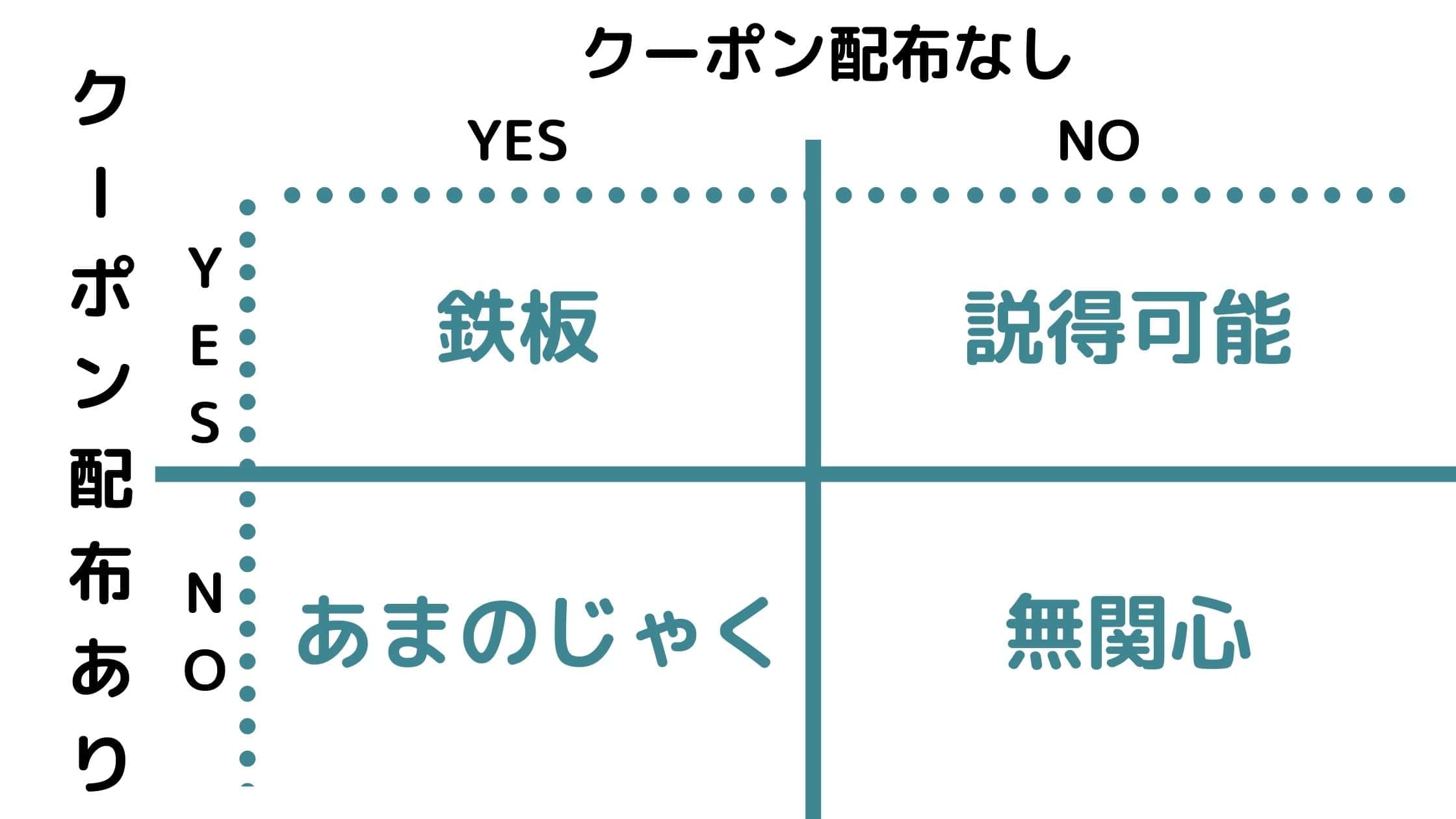
鉄板・・・クーポンを配布してもしなくても購入してくれるユーザー群
説得可能・・・クーポンを配布しないと購入しないが、クーポンを配布すると購入してくれるユーザー群
あまのじゃく・・・クーポンを配布しなければ購入してくれるのに、クーポンを配布することで購入しなくなるユーザー群
無関心・・・クーポンを配布してもしなくても購入してくれないユーザー群
出来るだけ、説得可能のユーザー群に絞ってクーポンを配布したいところです。
あまのじゃくのユーザー群には絶対にクーポンを配布してはいけません。
※ここでは、クーポンとしていますが、クーポンの部分は他の施策に置き換えても問題ありません。
統計的因果推論の世界では介入効果という言葉を使いますが、ここで言うクーポンがいわゆる介入になります。

アップリフトモデリングの仕組み

さて、アップリフトモデリングはどのようなステップでおこなっていくのでしょうか?
以下の論文やサイト、書籍を参考にしています。

より詳しく知りたい方は、是非参考文献を見てみてください!
アップリフトモデリングは、ABテストと非常に似ていますが厳密にはABテストとは違います。
ABテストは実験群と統制群にランダムにグループを分けて、実験群にはある施策を介入させ統制群には施策を介入させません。

これにより介入効果について調べます。
基本的にアップリフトモデリングでも同様のステップを踏むのですが、アップリフトモデリングでは実験群と介入群それぞれの特徴量にも注目します。
どんな特徴量を持つサンプルが介入に対して反応したのかを測ることで、反応しやすい特徴量を持っているグループを特定することができるのです。
書籍「仕事ではじめる機械学習」で言及されている例を取り上げてみましょう!
ある広告バナーのクリック率が
クリエイティブAでは5.0%
クリエイティブBでは4.0%
であり有意差ありと判定されたとしましょう。
これだけ見るとクリエイティブAを採用すべきだとということになりますが、男女別にこのクリック率を分類してみると・・・
男性では、
クリエイティブAが8.0%
クリエイティブBが2.0%
女性では、
クリエイティブAが2.0%
クリエイティブBが6.0%
であることが判明しました。
性別で層別分析をしてみると大きな違いが発見できました。
この結果をふまえると、男性にはクリエイティブAで女性にはクリエイティブBを出すべきであるということが分かります。
このように特徴量によって介入効果の違いを測ることは単純な手作業でも出来ますが、特徴量が多くなると介入効果と特徴量の関係を紐解くのが非常に困難になります。
そこで登場するのがアップリフトモデリングなのです!
アップリフトモデリングでは以下のステップで実装していきます。
- 実験したい介入行為を設計し、実験群と統制群で何を行うかを決める
- 顧客の一部に対して、ランダム化比較実験(RCT)を実施する
- RCTの結果を学習データとテストデータに分ける
- 学習データからアップリフトモデリングの予測器を作成する
- アップリフトモデリングのスコアのグラフから、スコアがいくつ以上の顧客に対して、介入効果を実施するのかを決める
(引用元:「仕事ではじめる機械学習」※一部省略)
学習データからアップリフトモデリングの予測器を作成する部分では、実験群と統制群それぞれで別のモデルを作ります。
その上で、実験群で作られたモデルによるスコアと統制群で作られたモデルによるスコアの差もしくは比によって最終的なアップリフトモデリングのスコアが決まります。
統制群モデルではスコアが低いけど実験群モデルではスコアが高いようなユーザーに対して介入していくためです。
アップリフトモデリングを実際に使う場面

さて、続いてアップリフトモデリングを実際にどのような場面で利用するのか見ていきたいと思います。
アップリフトモデリングは、顧客に態度変容を起こさせるような施策の効果を最大化し、さらにその上でコストを最小限におさえることを目的に利用されます。
コストという観点からすると、アクションを打つのにコストが大きくかかるような施策にはアップリフトモデリングは非常に有用です。
例えば、E-メールに関しては送付にかかるコストがそれほどかからないため、先程のユーザー群の無関心層や鉄板層を無理に除外する必然性はあまりありません。
しかし、これが紙のDMになると1通送るのに大きなコストがかかるため鉄板層や無関心層をターゲットから除外するのには大きな意味があります。
何でもかんでもアップリフトモデリングを使えばよいというわけではないので注意が必要です。
アップリフトモデリングはWebマーケティングの領域で非常に利用されます。
Webマーケティングなどマーケティング周りについては以下の記事を参考にしてみてください!


アップリフトモデリングのPythonでの実装方法
それでは、最後にアップリフトモデリングをPythonで実装していきましょう!
コードは「仕事ではじめる機械学習」から実装に必要な部分だけピックアップしています。
まずは、アップリフトモデリングに適したシミュレーションデータを生成していきます。
import random
def generate_sample_data(num, seed=1):
is_cv_list = []
is_treat_list = []
feature_vector_list = []
random_instance = random.Random(seed)
feature_num = 8
base_weight = [0.02, 0.03, 0.05, -0.04, 0.00, 0.00, 0.00, 0.00]
lift_weight = [0.00, 0.00, 0.00, 0.05, -0.05, 0.00, 0.00, 0.00]
for i in range(num):
is_treat = random_instance.choice((True, False))
feature_vector = [random_instance.random() for n in range(feature_num)]
cv_rate = sum([feature_vector[n] * base_weight[n] for n in range(feature_num)])
if is_treat:
cv_rate += sum([feature_vector[n] * lift_weight[n] for n in range(feature_num)])
is_cv = cv_rate > random_instance.random()
is_cv_list.append(is_cv)
is_treat_list.append(is_treat)
feature_vector_list.append(feature_vector)
return is_cv_list, is_treat_list, feature_vector_list
ここでは、CVしたかどうかのデータ(is_cv_list)と実験群かどうかのデータ(is_treat_list)と8つの特徴量(feature_vector_list)を生成しています。
lift_weightで介入があった場合にCVスコアに影響を及ぼす特徴量を作っています。
続いて生成したデータを用いてロジステック回帰でモデルを構築していきます。
from sklearn.linear_model import LogisticRegression
# trainデータの生成
sample_num = 100000
train_is_cv_list, train_is_treat_list, train_feature_vector_list = generate_sample_data(sample_num, seed=1)
# 学習器の生成
treat_model = LogisticRegression(C=0.01)
control_model = LogisticRegression(C=0.01)
# データをtreatmentとcontrolに分離
treat_is_cv_list = []
treat_feature_vector_list = []
control_is_cv_list = []
control_feature_vector_list = []
for i in range(sample_num):
if train_is_treat_list[i]:
treat_is_cv_list.append(train_is_cv_list[i])
treat_feature_vector_list.append(train_feature_vector_list[i])
else:
control_is_cv_list.append(train_is_cv_list[i])
control_feature_vector_list.append(train_feature_vector_list[i])
# 学習器の構築
treat_model.fit(treat_feature_vector_list, treat_is_cv_list)
control_model.fit(control_feature_vector_list, control_is_cv_list)
ロジスティック回帰でなくても、分類タスクに使える機械学習手法であればアップリフトモデリングに適用させることが可能です。
そしてテストデータを同様に発生させて、先程の学習モデルによってスコアを予測していきます。
# seedを変えて、テストデータを生成
test_is_cv_list, test_is_treat_list, test_feature_vector_list = generate_sample_data(sample_num, seed=42)
# それぞれの学習器でCVRを予測
treat_score = treat_model.predict_proba(test_feature_vector_list)
control_score = control_model.predict_proba(test_feature_vector_list)
# スコアの算出、スコアは実験群の予測CVR / 統制群の予測CVR
# predict_probaはクラス所属確率のリストを返すため1番目を参照する
# model.classes_ を参照すると、どのクラスが何番目かを知ることができる
score_list = treat_score[:,1] / control_score[:,1]実験群を基に作った学習モデルで予測したCVスコアと統制群を基に作った学習モデルで予測したCVスコアの比率からアップリフトモデリングのスコアを算出します。
ここからはどのくらいのアップリフトモデリングのスコアを閾値として施策を打つかを判断していくことになります。
アップリフトモデリング まとめ
アップリフトモデリングについて解説してきました!
・アップリフトモデリングは施策の介入効果を測るマーケティングに活用できる手法である
・4つのユーザー層「説得可能」「鉄板」「あまのじゃく」「無関心」に切り分ける
・実験群と統制群に分けてそれぞれでモデル構築しスコア比もしくはスコア差をアップリフトモデリングのスコアとする
アップリフトモデリングを使いこなせるようになれば、ビジネスに大きな価値を生み出せること間違いなし!
是非アップリフトモデリングの強力さを知って自分のビジネスへ活かしてみましょう!
機械学習、データサイエンス、Pythonについては以下の記事で詳しく解説していますのであわせてチェックしてみてください!



 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















