【実践】Pythonで株価取得~分析・予測まで実践してみよう!


こんにちは!スタビジ編集部です!
この記事ではデータサイエンスの実践として”株価データ“を使った分析を解説していきます!

データコンペに出るのは一つだけど、人によっては「ハードルが高い!」ってなりそうだから今回は身近な株価データを使った分析をしてみよう!
実際に手を動かしつつ「株価データの取得」~「データの分析」までの一連の流れをマスターしましょう!
株式投資について興味がある方は以下の記事で勉強法をまとめているので、チェックしてみてください。

また、株式投資×データ分析の力で株価予測をマスターしたいのであれば当メディア運営サービスの「スタアカ」の「14.株価予測コース」で詳しく取り上げています!こちらもご参照ください!

株価データの取得
まず株価データの取得について学んでいきましょう!
以下のYoutube動画の中でも簡単に解説していますのであわせてチェックしてみてください!
ターゲットの指定
今回はデータの取得に”yfinance“というライブラリを使います
これは”Yahoo!Finance’sAPI”から作られたライブラリで、Yahooファイナンスから株価データを取得することが出来ます!
ただ、Yahoo! finance APIは、Yahooの公式のサービスではなくYahooの一般公開されているAPIを使用したオープンソースのツールで個人的な使用のみを目的としてます
なので、あくまで勉強のために使うように使い方には注意しましょう!
pip install yfinanceライブラリはpipコマンドで簡単にインストール出来ます!
では”Yahoo Finance API”を使って株価データを取得していきましょう
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import datetime
import yfinance as yf
#ターゲットを指定
ticker = "AMZN"
#データを収集
data = yf.download(ticker , period='7d', interval = "1d")“ticker”の変数にターゲットとなる株の銘柄コードを指定します!
今回はターゲットをAmazon(銘柄コード”AMZN“)を指定しました
変数には複数の株を指定することも出来ます
#ターゲットを指定
tickers = "AMZN AAPL"このように設定すると、AmazonとAppleの情報を一度に取得できます
日本株を指定するときは銘柄コードに東京証券を表す「.T」を追加します
#ターゲットを指定
ticker = "4755.T"上記は楽天グループ(銘柄コード:4755)を選択した例となります
取得するデータの期間、頻度の選択
ターゲットを指定した後は取得する期間、頻度を決めてデータを取得していきます!
#データを収集
data = yf.download(ticker , period= "7d", interval = "1d")“download関数“で取得したい株価データを指定します
引数はいろいろありますが、download(ターゲット, 期間, 頻度)をまずは指定しましょう!
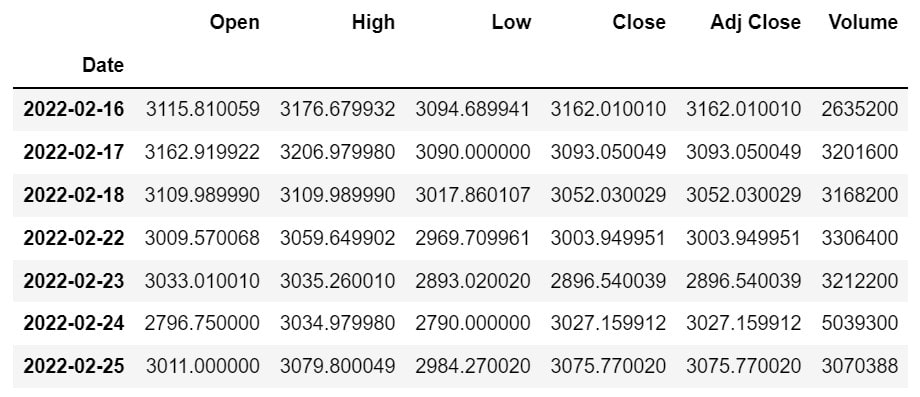
取得したデータがこちらです!
「期間」は日単位、月単位、年単位の他、”ytd”(当会計年度)や”max”(全期間)を選択できます
今回は「period= “7d”」と7日間を指定しました
またこの期間に「start/end」を使って、特定の日にちを指定することも出来ます
#データを収集
data = yf.download(ticker, start= "2022-01-01",end="2022-01-15", interval = "1d")2022年1月1日から2022年1月15日のデータを取得しています
「頻度」は分単位、時間単位、日単位、週単位、月単位を選択出来ます
今回は「interval = “1d”」と各日のデータを取得しました
また、取得できる頻度のバリエーションは決まっています
[1m,2m,5m,15m,30m,60m,90m,1h,1d,5d,1wk,1mo,3mo]m⇒分、h⇒時間、d⇒日、wk⇒週、mo⇒月となっています
なので、4h置き(interval = “4h”)みたいな指定をするとエラーになってしまうので注意してください!
また、株価の情報でだけではなくて財務情報も取得できるみたいなので、余裕があったら試してみよう!
株価データの可視化
取得したデータの中身を詳しく見ていきましょう!
#データを収集
data = yf.download(ticker , period= "7d", interval = "1d")
datayfinanceではデータをpandasのDataFrameの形で返してくれます!
株の情報が取得出来ていますね!Date列がIndexになっています
- Date:取得日時
- Open:始値
- High:高値
- Low:安値
- Close:終値
- Adj Close:調整後終値
- Volume:出来高
このデータを使えば株価の変動を見たり、株価の予測とか出来そうです!
ではこのデータを可視化してみましょう!
単位が違う「Volume」はいったん削除して折れ線グラフで見てみます!
df = data
df = df.drop("Volume", axis=1)
#可視化する
df.plot()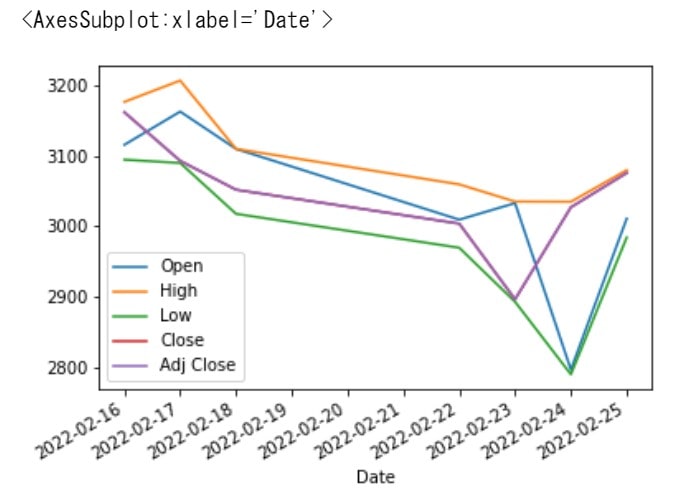
価格の推移が可視化されました、こう見ると週前半からやや右肩下がりでしたが、最後は回復しそうに見えますね
取得するデータの期間や頻度を変更して、どのように価格が変動しているか見てみましょう!
次に、株のチャートでよく見るローソク足のグラフを表示します
ローソク足のグラフは”mplfinance“というライブラリを使って出力します
import mplfinance as mpf
#ローソク足グラフの表示
mpf.plot(df, type="candle")ライブラリがインストールされていない場合はpipコマンドでインストールしましょう!
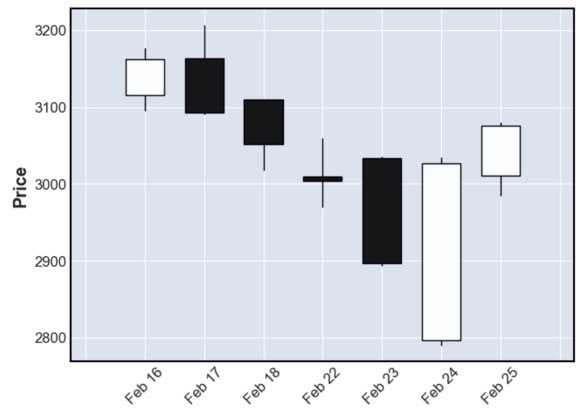
ローソク足のグラフを表示させることが出来ました
また、出来高(株売買の取引量)も併せて出力出来ます
全体の流れを見るため、取得するデータの期間を6ヶ月にして可視化します
#データを収集
df = yf.download(ticker, period = "6mo", interval = "1d")
#ローソク足グラフの表示
mpf.plot(df, type="candle",volume=True,figratio=(10,5))先ほどの関数で「volume=True」を指定します(※Volume列を削除してしまった場合はもう一度データを取り直しましょう!)
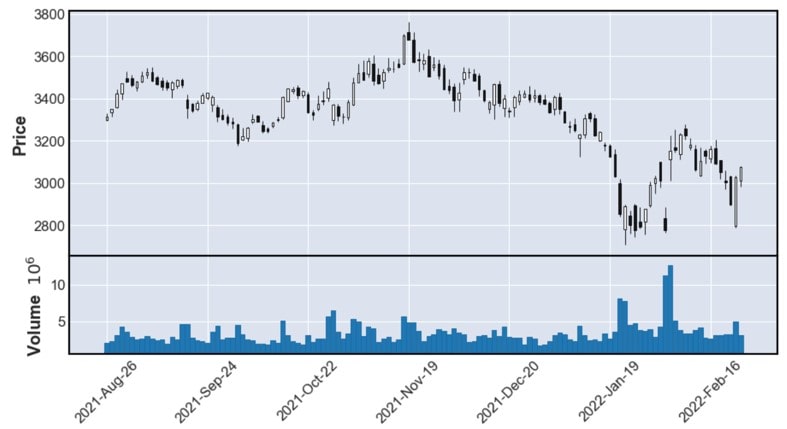
価格の変動と出来高の増減を一度に見ることが出来ました!
ここで可視化して分かった情報(変化が大きい場所等)を深堀りして、今後の分析に活かしていこう!
株価データの加工
株価の分析をするため、取得したデータを使って新しい指標”移動平均“を加えてみましょう!
全体の流れをみるため、期間を6ヶ月にしたデータで分析します
#データを収集
data = yf.download(ticker, period = "6mo", interval = "1d")
#移動平均を指標に加える
price = df["Close"]
span = 5
df["sma05"] = price.rolling(window=span).mean()移動平均にはpandasの”rolling関数“を使用します
rolling関数は窓関数と呼ばれるものを指定した要素の数の幅だけ適用する関数となっています
今回は幅を「5」と設定し、平均値メソッド(mean)を指定しているため、5日間の終値の平均を5日目に記録しています!
df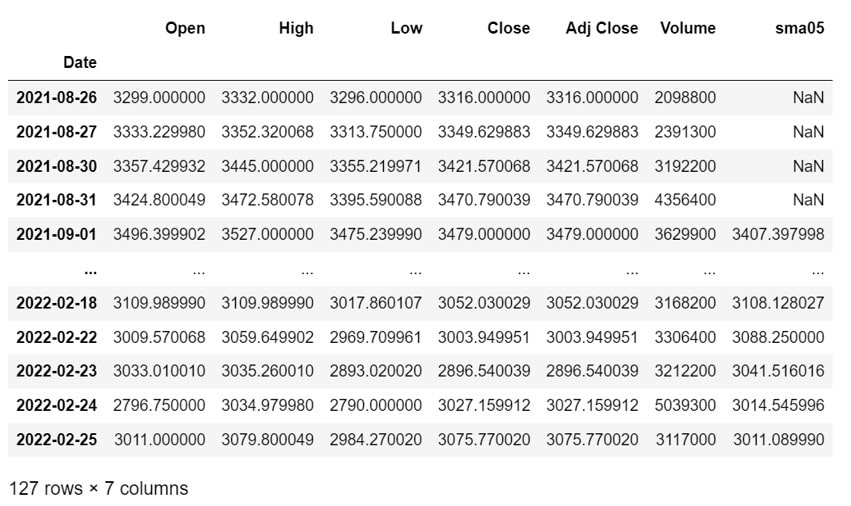
移動平均(sma05)が追加されています!ただ、最初の4日間は5日間分のデータがなくNaNとなっています、、、
そこで、最初の4日間は取得できる日数の平均を取る(min_periods=1)ように設定します
df["sma05"] = price.rolling(window=span, min_periods=1).mean()
df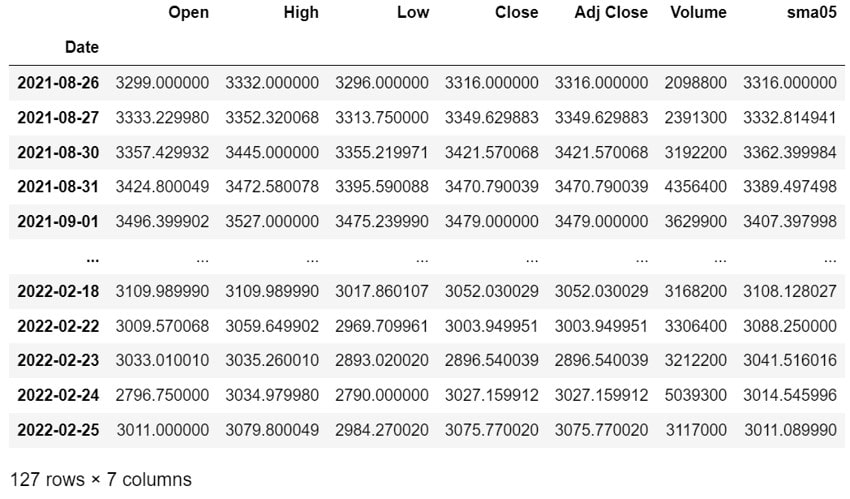
グラフにするとこのようになります
plt.plot(df.index, df["Close"], label="Close")
plt.plot(df.index, df["sma05"], label="sma05")
plt.legend()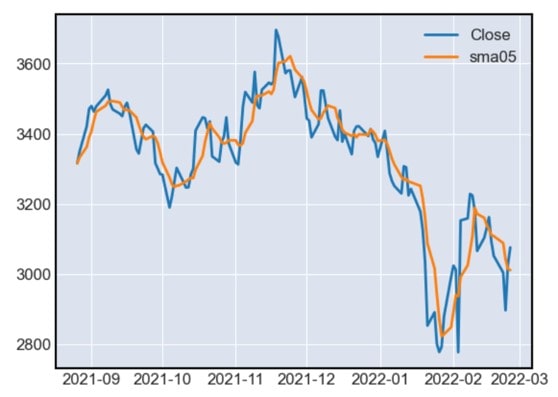
rolling関数では、平均値の他にも中央値や最大値を取得したり幅の中の要素に重みづけを付けることが出来ます
株価データの分析
取得した株価データを使って統計的な分析を行っていきましょう!
今回は6ヶ月間の株価データに対して”ARIMAモデル“を使った時系列データ分析を行います
“ARIMAモデル”は時系列データの差分をとって差分のデータに落とし込むことで定常にし、ARMAモデルを適用するモデルで株価などの非定常性データに用いられます!
時系列データ分析について詳しく知りたい方は下記の記事をチェックしてみてください!

まずは取得したデータを学習データ(70%)とテストデータ(30%)に分けます
#ARIMAモデル データ準備
train_data, test_data = df[0:int(len(df)*0.7)], df[int(len(df)*0.7):]
train_data = train_data['Close'].values
test_data = test_data['Close'].values今回はランダムではなく日時で7:3に分割して使用します
続いてARIMAモデルを実装していきます
ARIMAモデルはstatsmodelsライブラリから呼び出して使用します
from statsmodels.tsa.arima.model import ARIMAstatsmodelsライブラリが入っていない場合はインストール(pip install statsmodels等)しましょう!
ARIMAモデルはARモデルとMAモデルを組み合わせで、下記の3つのパラメータ(p,d,q)を入力します
- p:ARモデルのパラメータで、遅延観測値の数
- d:観測値の段差
- q:MAモデルのパラメータで、移動平均ウィンドウのサイズ
# ARIMAモデル実装
model = ARIMA(train_data, order=(6,1,0))
model_fit = model.fit()
print(model_fit.summary())今回はパラメータ(p,d,q)にp=6、d=1、q=0と選択しました
実際にはパラメータをチューニングして最適な値を見つけてモデル構築しましょう!
では実際にARIMAモデルを用いて予測をしてみます
#ARIMAモデル 予測
history = [x for x in train_data]
model_predictions = []
for time_point in range(len(test_data)):
#ARIMAモデル 実装
model = ARIMA(history, order=(6,1,0))
model_fit = model.fit()
#予測データの出力
output = model_fit.forecast()
yhat = output[0]
model_predictions.append(yhat)
#トレーニングデータの取り込み
true_test_value = test_data[time_point]
history.append(true_test_value)ARIMAモデルでは差分のデータを使うため、観測したテストデータを毎回取り込み、モデルを再構築しながら進めていきます!
実際に取得した予測データとテストデータを比較してみましょう
#可視化
plt.plot(test_data, color='Red', label='実績値')
plt.plot(model_predictions, color='Blue', label='予測値')
plt.title('Amazon 株価予測値', fontname="MS Gothic")
plt.xlabel('日', fontname="MS Gothic")
plt.ylabel('Amazon 株価', fontname="MS Gothic")
plt.legend(prop={"family":"MS Gothic"})
plt.show()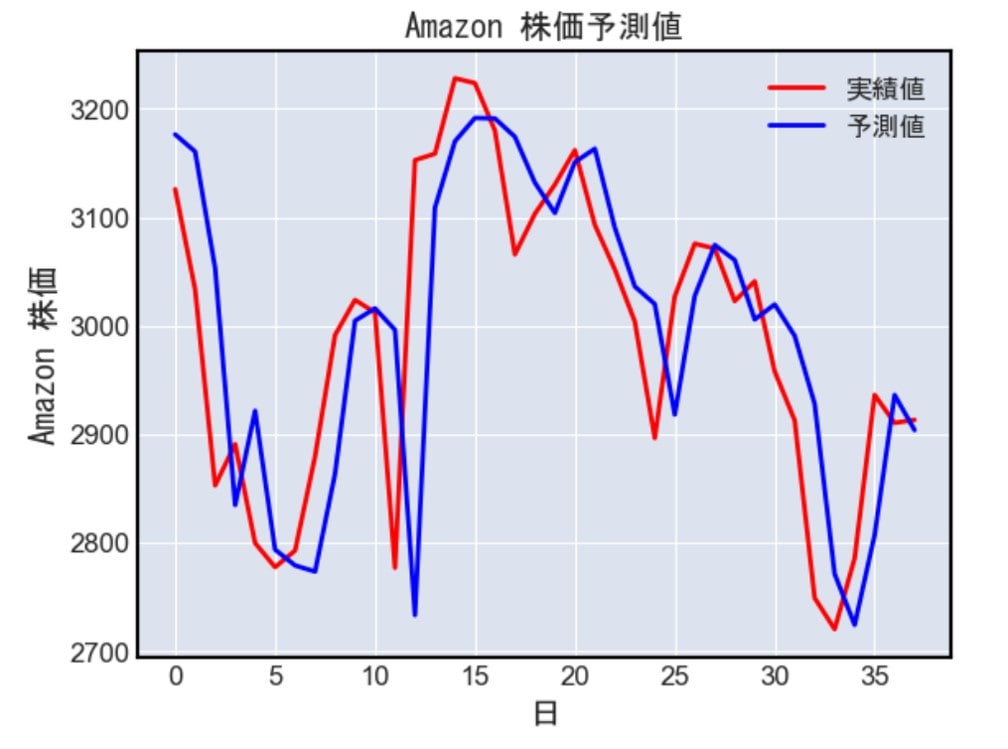
日数のずれがありますが、おおむね増減の傾向が近しいモデルを構築出来た感じですね!
Pythonで株価データの分析まとめ

ここまでご覧いただきありがとうございました!
今回は”yfinance“というライブラリを使ってpythonで株情報の扱い方を学んでいきました。
「データの取得」~「データの分析」について実際に手を動かしながら、実データを分析するための準備が出来たと思います!
仮想通貨のPython分析やドル円のPython分析については以下の記事でまとめていますのでこちらもあわせてチェックしてみてください!


また、ARIMAモデルを含む3種のAIモデルについて需要予測をテーマに説明した以下の記事では、Python実装も含め解説しています!

ここからは、ご自身で統計手法や機関学習を用いて株価の予測などに挑戦してみましょう!
株式投資×データ分析の力で株価予測をマスターしたいのであれば当メディア運営サービスの「スタアカ」の「14.株価予測コース」がオススメ!
当メディアが運営するAIデータサイエンス特化スクールの「スタアカ(スタビジアカデミー)」を受講することで株式投資×分析と共に分析の土台となる様々なスキルが身につきます!
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【Pythonの学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ 実際に実データを使った様々なワークを行う |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解などもあわせて学べるボリューム満点のコースになっています!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
また、データサイエンティストになるための独学ロードマップについて知りたい方はぜひ以下の記事をチェックしてみてください

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!