
アソシエーション分析を事例と共に解説!Pythonで実装してみよう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
あるコンビニにコーヒーを買いに行っただけなのに、近くに置いてあったスイーツもついつい手に取ってしまった、、、
そんな経験ありませんか?

もしかしたらそのコンビニでは、アソシエーション分析により商品陳列が最適化され、「ついで買い」が増やされているかもしれません!
この記事では、そんなアソシエーション分析の特徴とPythonでの実装を見ていきたいと思います。
以下のYoutube動画でアソシエーション分析について分かりやすく解説しているのでこちらも合わせてチェックしてみてください!
目次
アソシエーション分析とは

それでは、まずアソシエーション分析とは何なのか見ていきましょう!
アソシエーション分析のアソシエーションとは、英語で「つながり・関連」などの意味。
すなわちアソシエーション分析とは関連性を見つけ出す分析手法。
もう少し細かく説明すると、大量のデータから「〇〇ならば△△」という関係をアソシエーション・ルールとして抽出して、ビジネスへ応用するデータマイニング手法です。
アソシエーション分析により「もし〇〇ならば△△である」という規則性を定量的に把握できるため、セールスにおける戦略を効率良く考えることができます。

アソシエーション分析の活用例

アソシエーション分析は対象事象が行動記録である全ての事象に対して適用することができます。
ここでは3つの活用例を紹介していきます。
1. 商品販売
アソシエーション分析の代表例として有名なのが「おむつとビール」の事例。
アメリカのドラッグストアにおいて、25店舗・120万個の顧客の買い物かごの中身を分析し、顧客に共通する傾向を導き出す試みが行われました。
その結果、「金曜日の17~19時に30~40代の男性が来店し、おむつとビールをよく併せ買いする」という傾向が明らかになったのです!
そこから、「仕事終わりにおむつを買って帰るよう頼まれた父親が、ついでにビールを購入しているのではないか」という仮説が立てられました。
そして仮説に基づきおむつの隣にビールを配置したところ、実際に売上が増加する効果が現れたそうです。
2. 検索履歴
ECサイトにおける検索履歴データに対してアソシエーション分析を行うことで、特定の商品・サービスを検索する際に一緒に検索されやすい単語を明らかにすることができます。
それにより、サイト上での商品訴求をより効率的に行うことができるようになるのです。
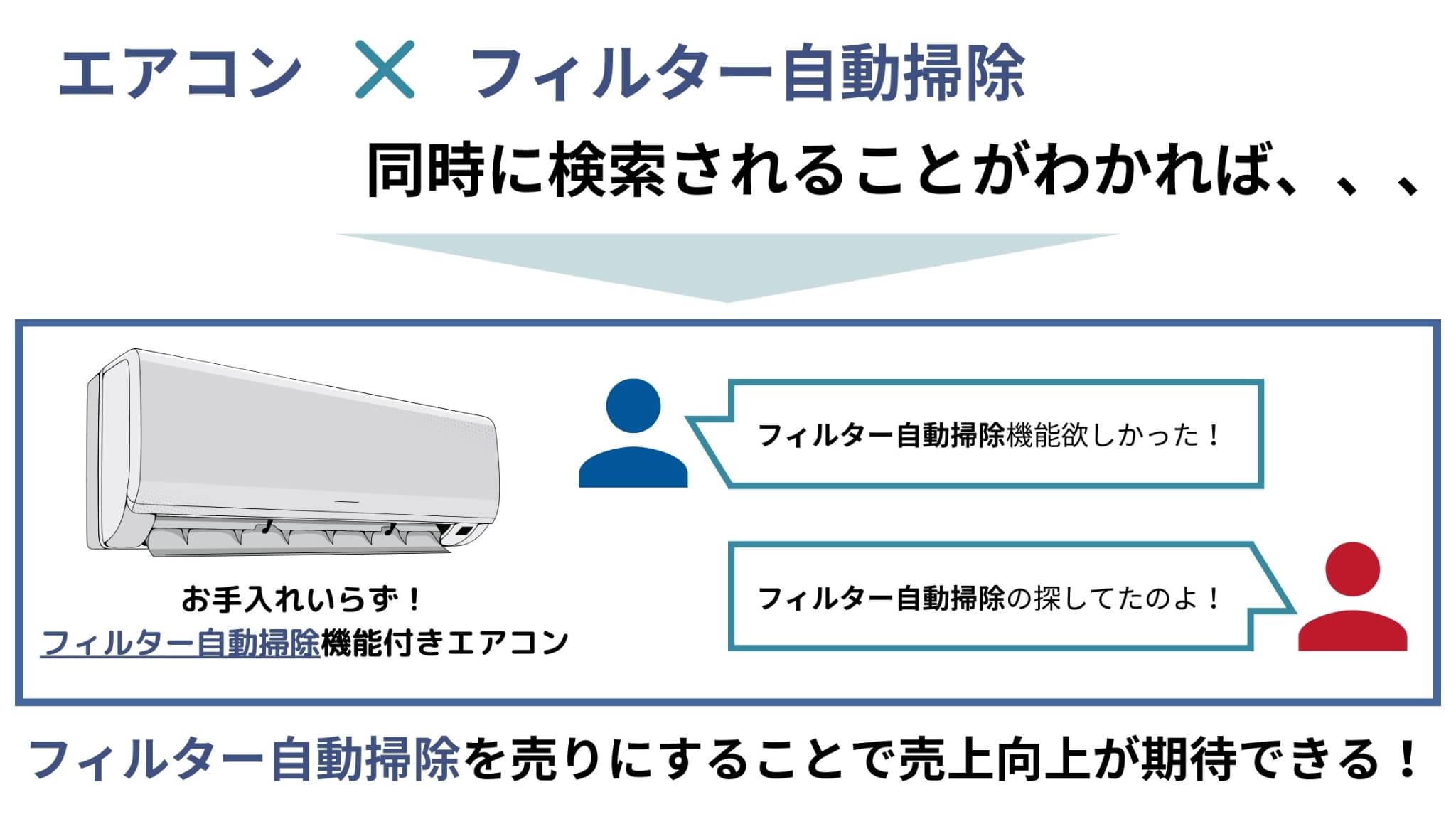
例えば、「エアコン」と「フィルター自動掃除」が同時に検索されることが多いとわかれば、エアコンの商品訴求時にフィルター自動掃除機能を売りにした内容にすることで売上向上が期待できるでしょう。
3. 位置情報
位置情報データに対してアソシエーション分析を行うことにより、ある人が特定の場所を訪問した際に一緒に訪問しやすい場所を明らかにすることができます。
それにより、行動のパターンを効率よく把握することができるようになるのです。
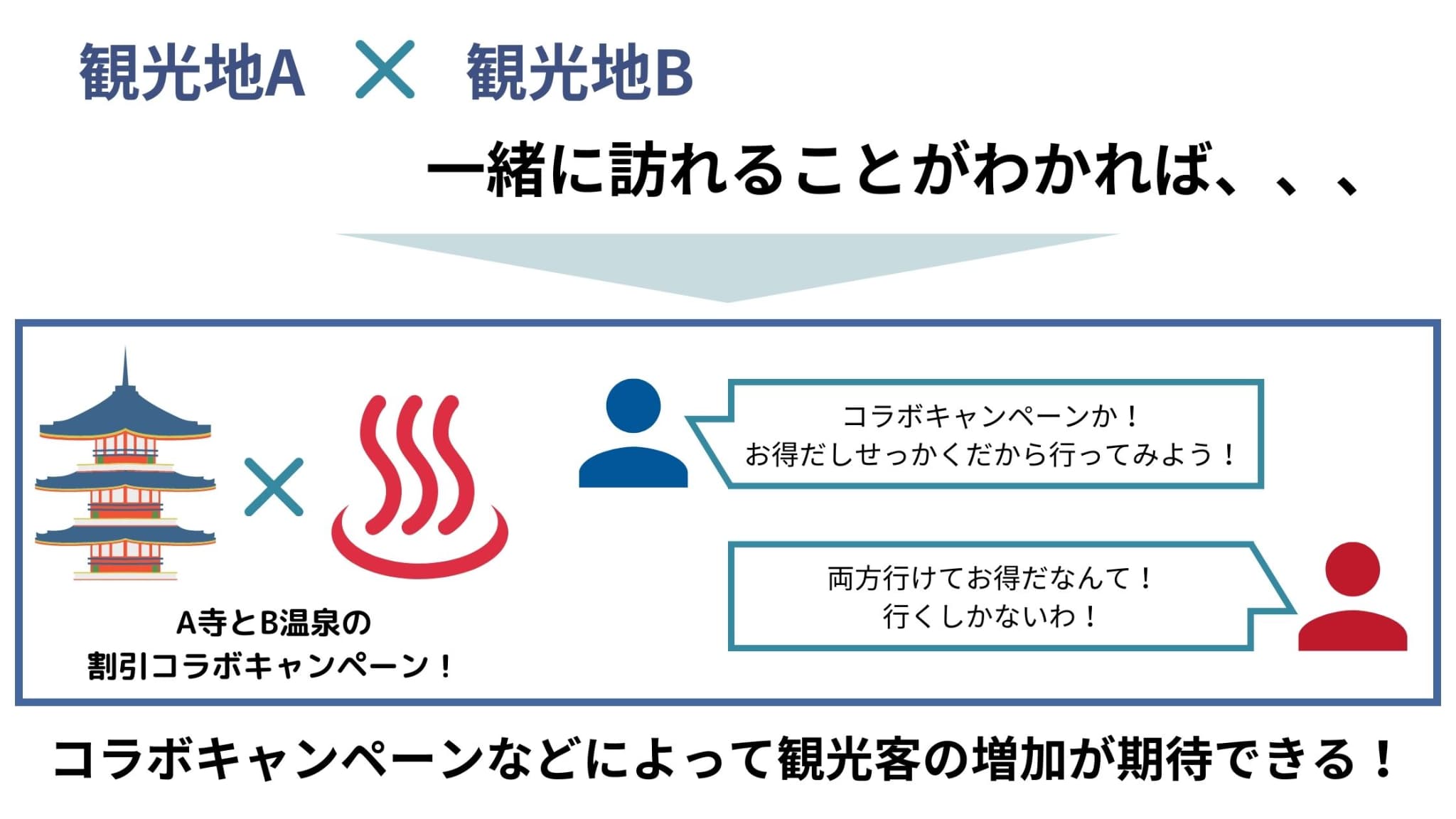
例えば、「観光地Aを訪れる観光客は観光地Bを訪れる割合が高い」ということがわかれば、「観光地Aと観光地Bのコラボキャンペーン」を行うことで観光客の増加が期待できるでしょう。
アソシエーション分析で用いる3つの指標

上で説明したように、アソシエーション分析の目的はアソシエーション・ルールをデータから抽出することです。
そのために必要な指標が3つあるので、それぞれ見ていきましょう!
1. 支持度 (Support)
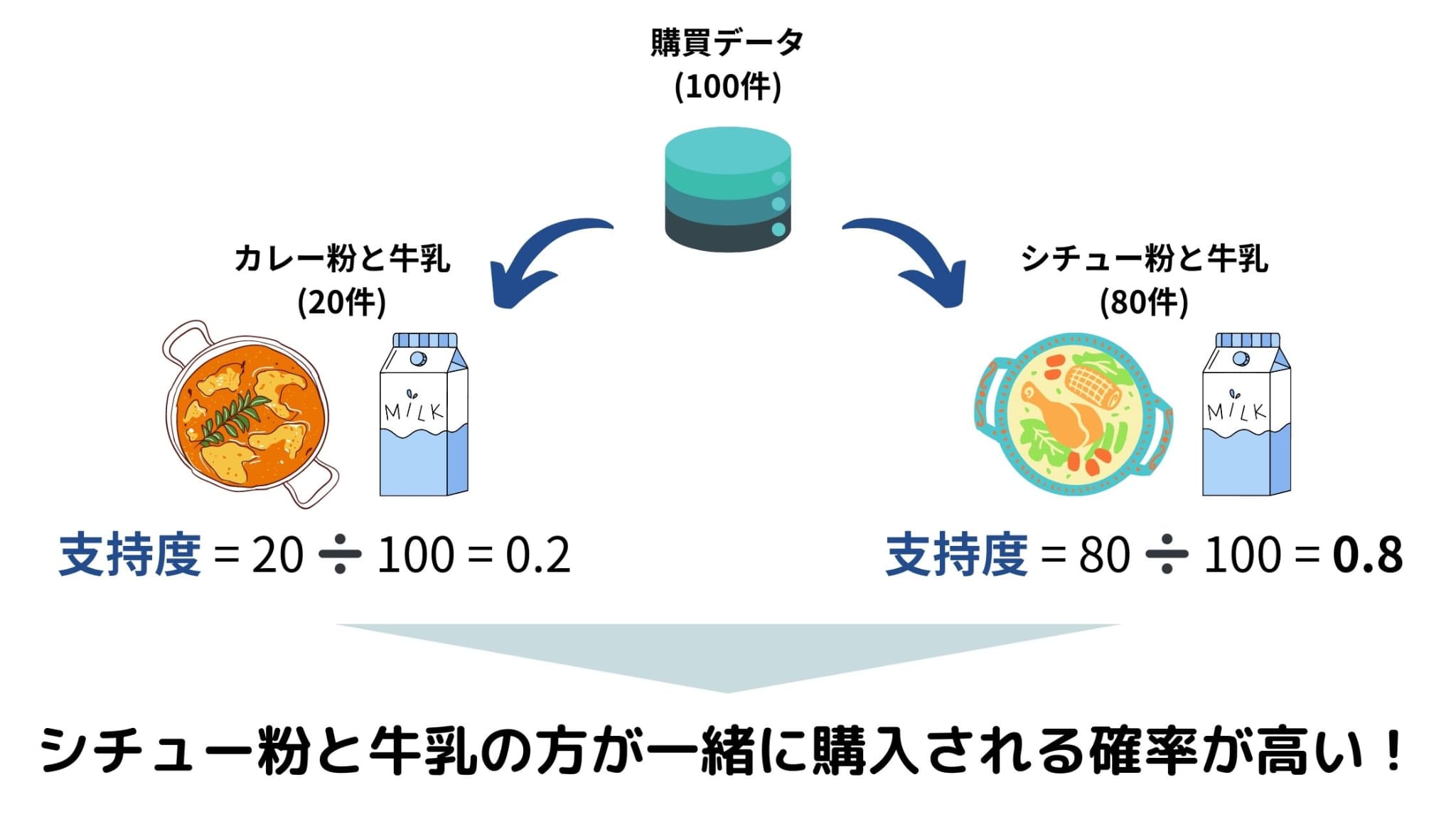
支持度(Support)は、全データの中で、「ある商品Aとある商品Bが一緒に購入される割合」を表す指標です。
つまり、支持度が高ければそれだけ商品Aと商品Bが同時に購入される傾向にあるということです。
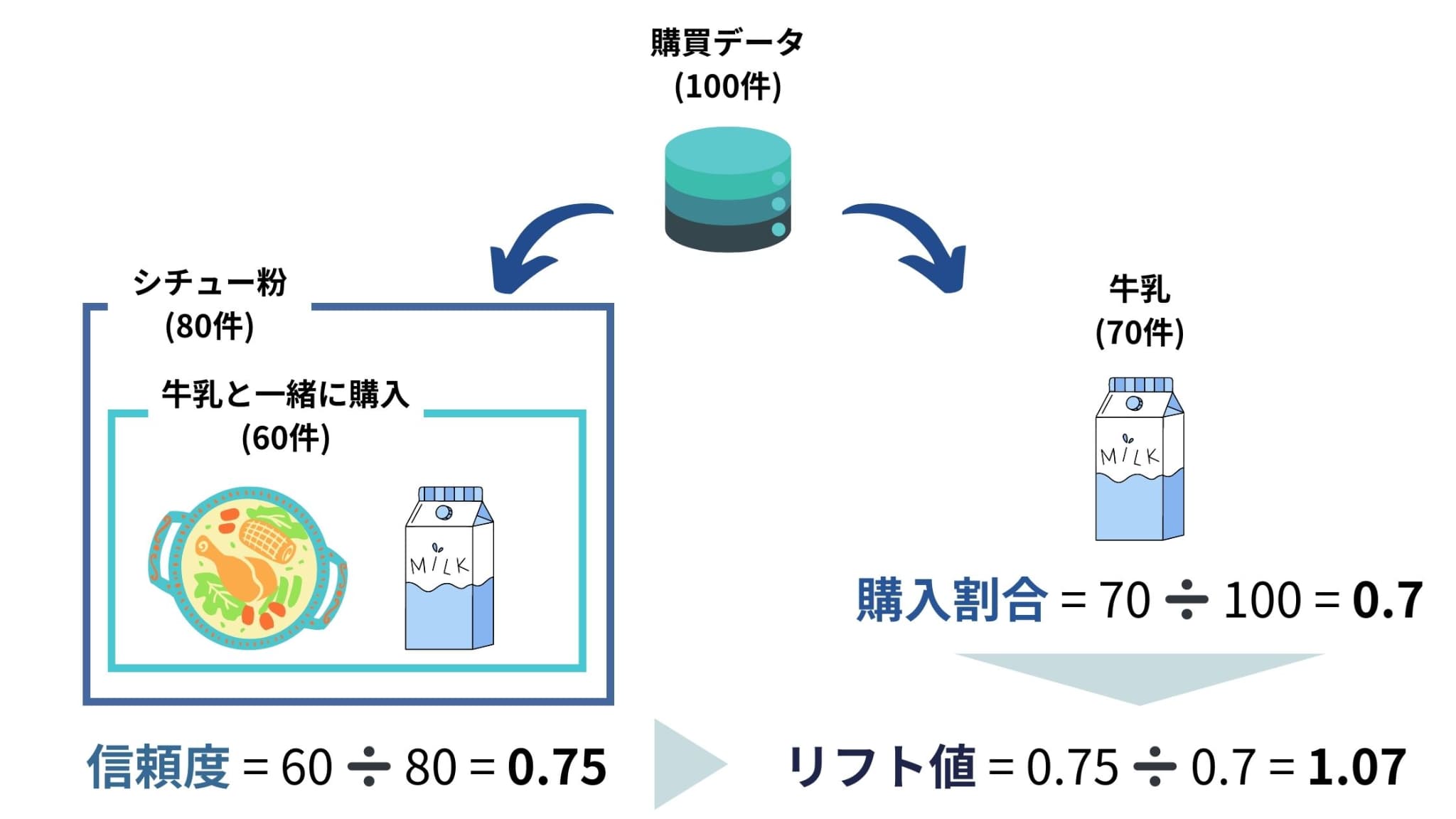
例えば、ある小売店で100件の購買データを得られたとしましょう。そのうち、20件のデータで「カレー粉と牛乳が一緒に購入されていた」場合、支持度は0.2となります。一方、80件のデータで「シチュー粉と牛乳が一緒に購入されていた」場合、支持度は0.8となります。
よって、「シチュー粉と牛乳」の組み合わせの方がより一緒に購入される傾向にあるということがわかり、小売店側は「シチュー粉売り場の近くに牛乳を置こう」といった決断を下しやすくなるのです。
2. 信頼度(Confidence)
信頼度(Confidence)は、「ある商品Aが購入された中で、ある商品Bも購入された割合」を表す指標です。
つまり、信頼度が高ければそれだけ商品Aと商品Bが同時に購入される傾向にあるということです。
例えば、「カレー粉」の購入データが20件あり、そのうち「牛乳」も一緒に購入されているものが10件であった場合、信頼度は0.5となります。
そうなんです。
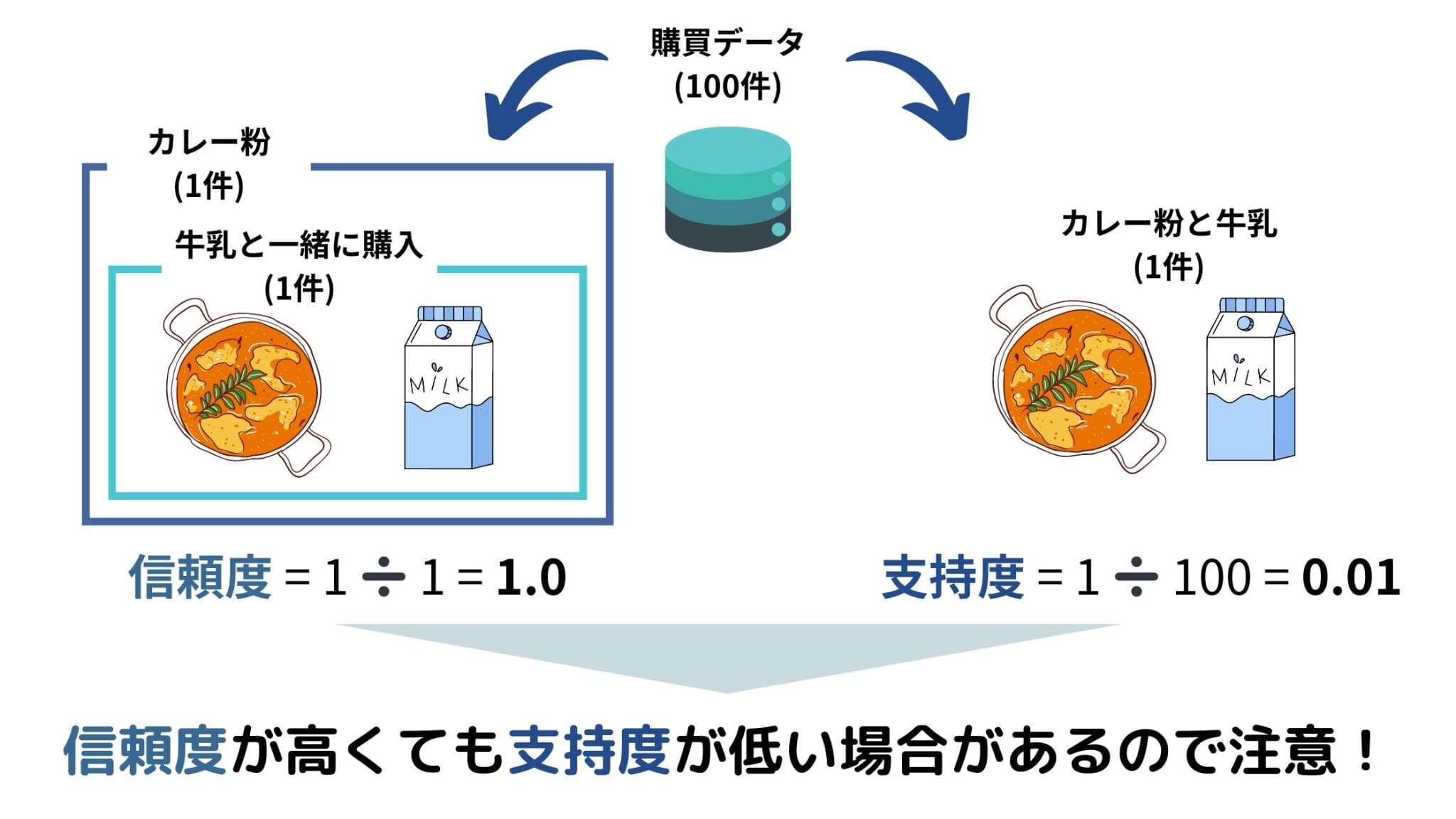
そのため、例えば購買データ100件を得られたとき、「カレー粉と牛乳が一緒に購入されたデータ」が1件だけであった場合でも、信頼度は「カレー粉が購入された中で牛乳も購入された割合」となり、1.0と算出されてしまいます。
しかし、「全体」を分母とする支持度を算出すると0.01となり、カレー粉と牛乳が一緒に購入される割合は高くないということがわかります。
つまり、信頼度だけで判断せず、支持度と合わせて判断する必要があります。
3. リフト値(Lift)
リフト値(Lift)は、全データの中で、「ある商品Aが購入された中で、ある商品Bも購入された割合」が、「ある商品Bだけを購入した割合」に比べてどれくらい多いかを表す指標です。
つまり、リフト値が高ければそれだけ商品Aの影響で商品Bが同時に購入される傾向にあるということです。
例えば、ある小売店で100件の購買データを得られたとしましょう。
「シチュー粉」の購入データが80件あり、そのうち「牛乳」も一緒に購入されているものが60件であった場合、信頼度は0.75となります。一方、全データ中、「牛乳」を購入したデータが70件あった場合、「牛乳」を購入した割合は0.70となります。このときリフト値は0.75÷0.70=1.07となります。
一般的に、リフト値が1を超える場合は、AとBに強い関係性があるといえます。
Pythonでアソシエーション分析をやってみよう

ここからは、Pythonで実際にアソシエーション分析をやっていきます。
分析の目的は、アソシエーション・ルールを抽出すること!
以下の流れで分析を進めていきます。
1. ライブラリのインストール
2. データの準備
3. データの加工
4. 支持度(Support)の算出
5. アソシエーション・ルール抽出のための評価指標の算出
6. アソシエーション・ルールの抽出
1. ライブラリのインストール
今回はmlxtendと呼ばれるライブラリを使用します。
また、分析で使用するモジュール等もここで全てimportしておきます。
pip install mlxtendimport mlxtend
from mlxtend.preprocessing import TransactionEncoder
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
import pandas as pd2. データの準備
データは以下のように作成したものを用います。
dataset = [
['玉ねぎ', 'にんじん','じゃがいも', '牛乳', 'カレー粉'],
['玉ねぎ', 'じゃがいも', 'シチュー粉', '牛乳'],
['牛乳', 'シチュー粉', 'にんじん', 'カレー粉'],
['牛乳','にんじん','玉ねぎ', 'シチュー粉'],
['玉ねぎ', 'にんじん', '牛乳', 'シチュー粉', 'じゃがいも'],
['玉ねぎ', 'カレー粉' ,'じゃがいも', '牛乳'],
['にんじん', 'シチュー粉', '玉ねぎ', 'じゃがいも'],
['シチュー粉', '牛乳', '玉ねぎ', 'カレー粉'],
['シチュー粉', '牛乳', 'にんじん'],
]3. データの加工
続いて、データセットをテーブル形式に加工します。
# データをテーブル形式に加工
table = TransactionEncoder()
table_array = table.fit(dataset).transform(dataset)
df = pd.DataFrame(table_array, columns=table.columns_)
df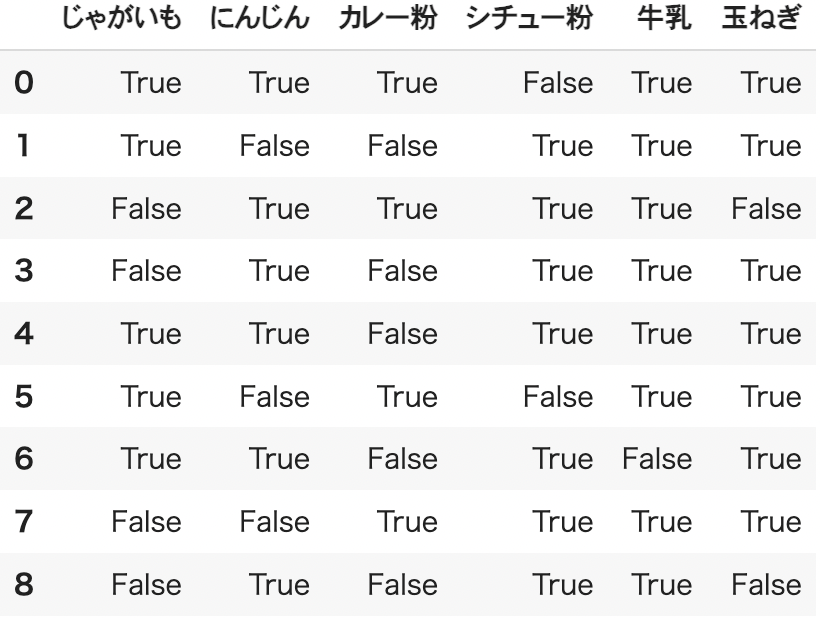
購入された商品であれば「True」、購入されていなければ「False」がそれぞれ格納されています。
4. 支持度(Support)の算出
続いて、商品の組み合わせごとに支持度を算出していきます。
# 支持度の算出
freq_items = apriori(df, # データフレーム
min_support = 0.01, # 支持度(support)の最小値
use_colnames = True, # 出力値のカラムに購入商品名を表示
max_len = None, # 生成されるitemsetsの個数
#verbose = 0, # low_memory=Trueの場合のイテレーション数
#low_memory = False, # メモリ制限あり&大規模なデータセット利用時に有効
)
# 結果出力
freq_items = freq_items.sort_values("support", ascending = False).reset_index(drop=True)
freq_items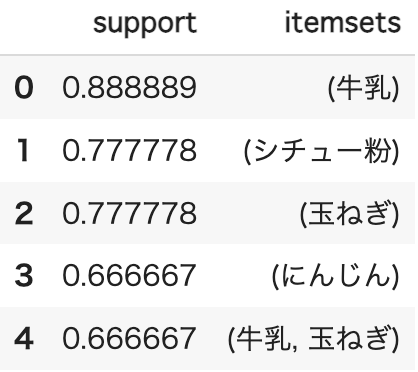
支持度の大きい順に並んでいることがわかります。
今回は上位5件だけを表示していますが、実際は全ての商品の組み合わせで支持度が算出されています。
この時、組み合わせではなくて単一の商品が上位に並んでいますが、例えば1位の牛乳は全データのうち牛乳が買われた割合を表しています。9人のうち8人が牛乳を購入しているので8/9で0.888889となるわけです。
5. アソシエーション・ルール抽出のための評価指標の算出
次に、信頼度やリフト値などの各評価指標を算出していきます。
下記のコードでアソシエーション・ルールの抽出まで一気にできるのですが、今回は例を示すために2段階に分けて説明します。
# アソシエーション・ルール抽出のための評価指標の算出
df_rules = association_rules(
freq_items, # supportとitemsetsを持つデータフレーム
metric = "confidence", # アソシエーション・ルールの評価指標
min_threshold = 0.0, # metricsの閾値
)
df_rules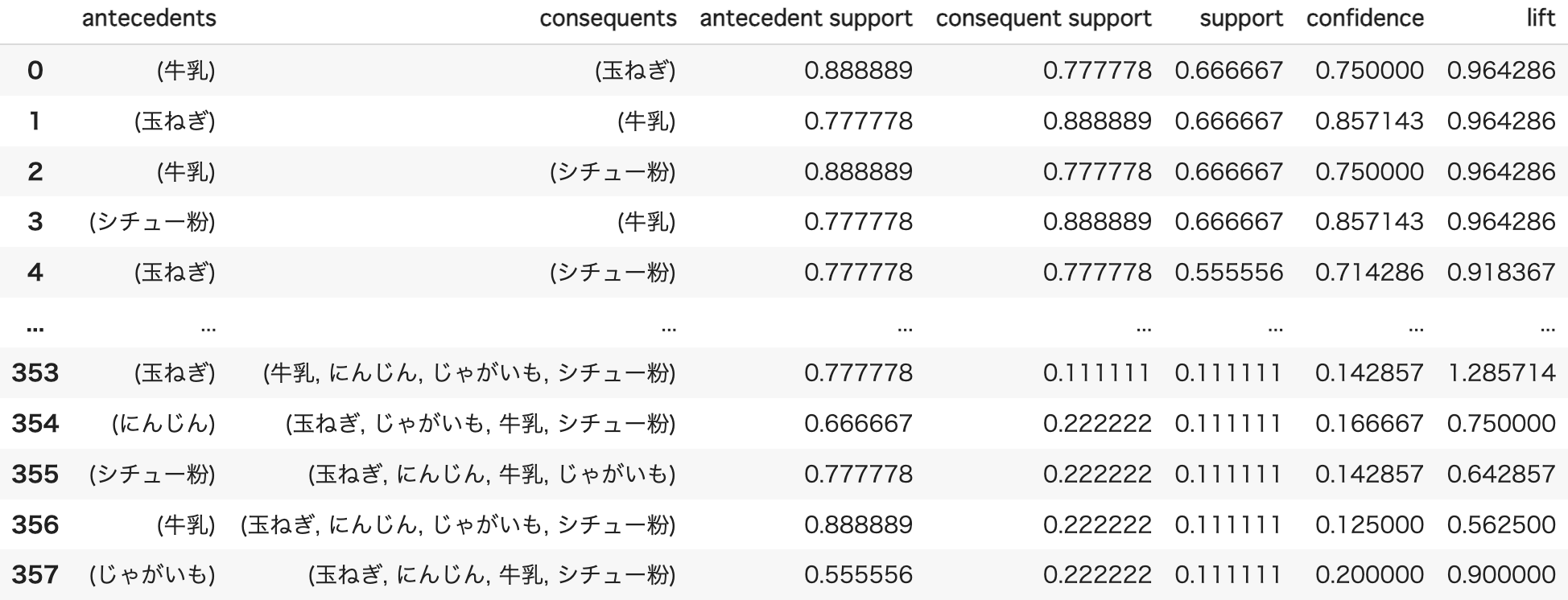
全ての商品の組み合わせにおける支持度、信頼度、リフト値が算出されています。
antecedents(前半)が1つ目の商品、consequents(後半)が2つ目の商品を表しています。
すなわち、antecedents_supportが1つ目の商品単体での支持度、consequents_supportが2つ目の商品単体での支持度を表し、supportが組み合わせとしての支持度、confidenceが信頼度、liftがリフト値を表します。
6. アソシエーション・ルールの抽出
5.で述べたように、コードの中の引数「metric = 」と「min_threshold = 」の部分でアソシエーション・ルールを抽出することができますが、ここで改めてルールを抽出していきます。
#結果を絞る
df_rules2 = df_rules[(df_rules["support"]>=0.4)&(df_rules["confidence"]>=0.8)&(df_rules["lift"]>1.0)]
df_rules2
出力結果より、支持度が0.4以上かつ、信頼度が0.8以上かつ、リフト値が1.0より大きい商品組み合わせが抽出できていることがわかります(自分で作成したデータなので現実だとあまりなさそうな「カレー粉」と「牛乳」の組み合わせもルールとして抽出されてしまいました、、、)。
全ての指標を並べた後にこのように各指標の条件で抽出するほうがおすすめです。
実際には膨大な量のデータに対して分析を行うので、より各指標の値が高い組み合わせを抽出できると思います!
アソシエーション分析 まとめ

ここまでご覧いただきありがとうございました!
本記事ではアソシエーション分析の概要からPythonでの実装方法まで解説していきました。
アソシエーション分析は、ビジネスの現場においてよく用いられる手法です。
上の「ビールとおむつ」の事例のように、今まで見えていなかった改善ポイントが明らかになる場合もあるので、蓄積したデータがあれば積極的にアソシエーション分析を行なっていきましょう!
また、今回分析に用いたPythonについて勉強したい方は以下の記事を参考にしてみてください!

さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















