
【衝撃】OpenAIの動画生成AI「Sora」の仕組みやできることについてわかりやすく解説!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
OpenAIがリリースしたtext to videoのモデル「Sora」がスゴすぎる!!
ChatGPT登場以来の大きな衝撃と言っても過言ではないでしょう。
ということでこの記事ではSoraについて現時点で分かっていることをわかりやすく解説していきます!
なお本記事執筆時点ではSoraに関する論文やモデル詳細は公開されておらず、Soraの情報は以下のOpenAIが公開したリリースページと詳細のリサーチページに頼ることになります。
目次
Soraのできること
まず最初にSoraのできることをまとめていきましょう!
以下の動画はSoraのリリースページで最初に目にする動画。
この動画を生成するのに使ったプロンプトは「A stylish woman walks down a Tokyo street filled with warm glowing neon and animated city signage. She wears a black leather jacket, a long red dress, and black boots, and carries a black purse. She wears sunglasses and red lipstick. She walks confidently and casually. The street is damp and reflective, creating a mirror effect of the colorful lights. Many pedestrians walk about.」
このプロンプトを入力するだけでこんなハイクオリティな動画が完成するなんて衝撃ですよね。
よく見ると背景の看板などの文字が潰れてしまっていたりするのですが、後ろを歩く人々の細かい描写には全く違和感がありません。
正直言われなければAIが生成したとは思いませんよね。
あと個人的には日本を題材にしてくれていて嬉しい笑
Soraのリサーチページには以下のように記載があります。
Much prior work has studied generative modeling of video data using a variety of methods, including recurrent networks, generative adversarial networks, autoregressive transformers, and diffusion models. These works often focus on a narrow category of visual data, on shorter videos, or on videos of a fixed size. Sora is a generalist model of visual data—it can generate videos and images spanning diverse durations, aspect ratios and resolutions, up to a full minute of high definition video.
今まで動画生成モデルとしてRNNやGANやTransformerや拡散モデルをベースにしたものがありましたが、それらはどれも特定のカテゴリで短尺かつ固定サイズによるものでした。
一方でSoraは1分もの長尺で様々なサイズの高品質な動画を生成できるのです!!
と言っています。
Soraのリリースページには他にもいくつか衝撃的な動画があるのですが、個人的には以下の動画が衝撃。
プロンプトは「Reflections in the window of a train traveling through the Tokyo suburbs.」のみ。
電車の外に存在する建物によって窓に映る姿がクリアになったり薄れたりしています。完全に物理法則を理解しているとしか思えない。
静止画を動画にすることが可能
また、Soraは静止画を動画にすることも可能なのです。以下の画像が

以下の動画になります。
静止画に対してここまで違和感のない動きを付けられるのは素晴らしい。
2つの動画をマージして違和感なく1つの動画にすることが可能
また2つの動画をマージして1つの動画で表現することが可能なのです。
カメレオンと孔雀の動画をマージして作られたのがこちらの動画。
違和感なく気付いたらカメレオンが孔雀に入れ替わっています。
対象物が一瞬消えても全く同じ対象物を出現させることができる
現実世界では当たり前ですが、意外と難しいのが全く同じ対象物を違う場面で登場させたり再度登場させること。
Soraでは以下の動画のように一旦犬が人に重なって消えてももう一度全く同じ見た目で出現させることができるのです。
ゲームの動画も生成できる
以下はMinecraftの動画。
リアル世界の動画だけではなく、こんな感じのデジタルワールドの動画も生成できちゃうんです!
Soraの仕組み
Soraのできることを色々見てきましたが、Soraの仕組みはどのようになっているのでしょうか?
大前提として現時点では、モデルの詳細は公表されておりません。
ただベースとなるアーキテクチャはリサーチページに記載がありますのでそこから拾って見ていきましょう!
動画は結局画像の連続ですので、画像生成のアーキテクチャとほぼ変わりません。
画像生成で最近主流なのは拡散モデルをベースにしたもので、ざっくり以下のようなイメージになります。
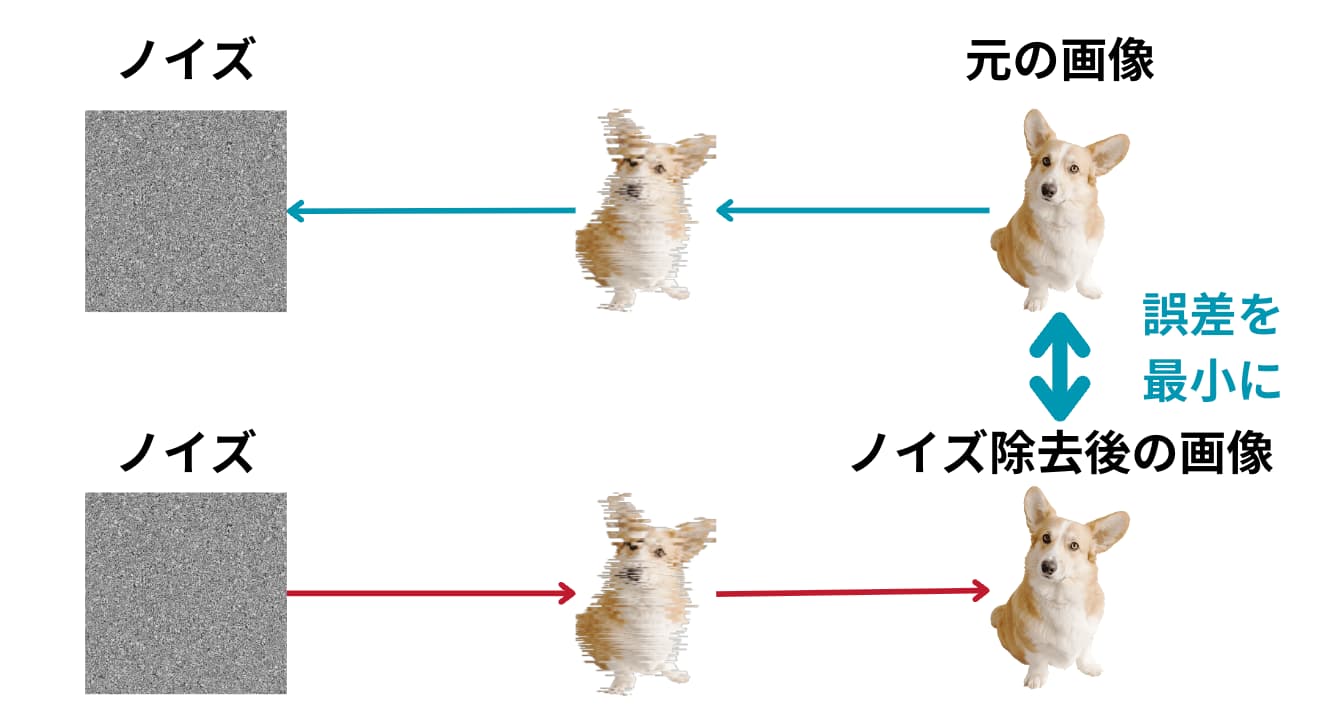
まず右上の元の犬の画像に対してノイズを乗せていきノイズになったら、今度は下の工程でノイズを取り除いていきます。
この時ノイズをのせて除去した画像と元の画像の誤差が小さくなるように学習していくとノイズから画像を生成できるようになるというようなアーキテクチャです。
詳しくは以下にまとめているのでチェックしてみてください。
そしてOpenAIの画像生成AIであるDALL・Eはこの拡散モデルにテキストを条件付けさせることでテキストから画像生成を可能にしています。
以下がDALL・Eのアーキテクチャです。
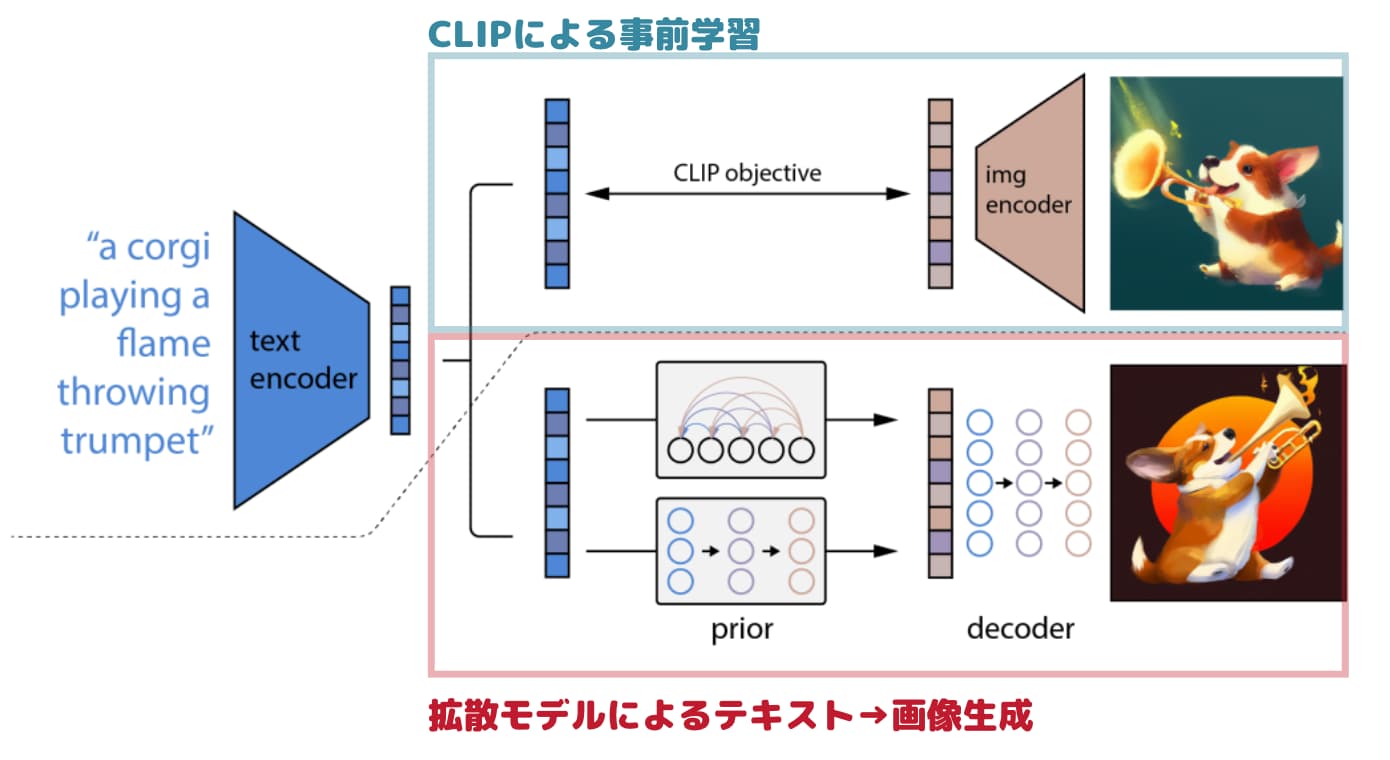 (参考:Learning Transferable Visual Models From Natural Language Supervision)
(参考:Learning Transferable Visual Models From Natural Language Supervision)
DALL・Eに関しては以下の記事でまとめています。

詳しいアーキテクチャは公開されていませんが、ザックリこれと同じことをSoraでもやっています。
以下はSoraのリサーチページからの引用です。
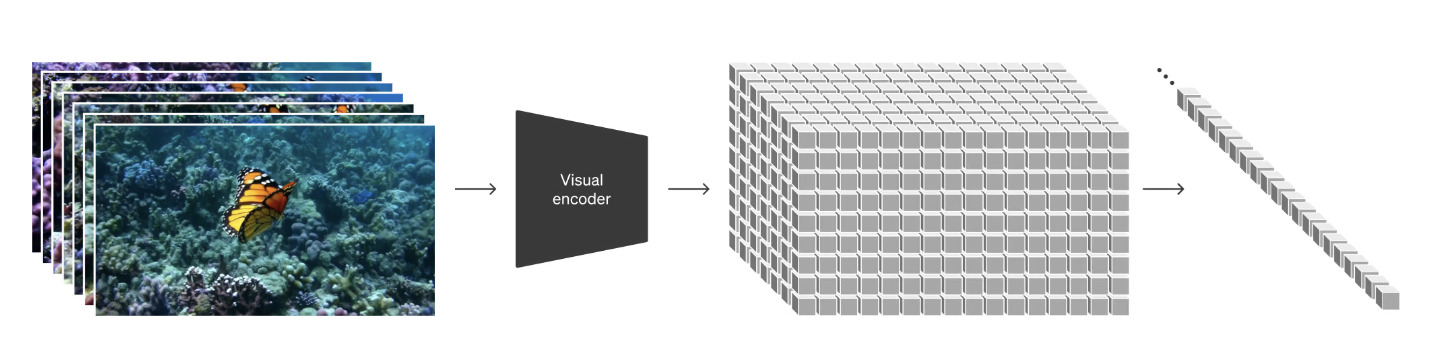
エンコーダー部分で動画を「低次元の潜在空間」に圧縮して学習してます。
これは、動画のデータをよりシンプルで扱いやすい形に変換する作業です。
潜在空間とは、元のデータ(この場合は動画)の重要な情報を保持しながら、より少ない情報量でそのデータを表現するための抽象的な空間のことを指します。
このプロセスにより、動画の本質的な特徴を捉えつつ、データ量を削減し、後続の処理を効率的に行えるようになるのです。
また、この潜在空間で表現された動画を「spacetime patches(時空間パッチ)」に分解すると表現されています。
このステップでは、動画を小さなパッチに変換することで、動画の局所的な特徴や時間的な変化をより詳細に捉えることができるようになっているようです。
最終的にデコーダでテキストの条件付け情報からDALL・Eと同じ要領で動画を生成することができるようになってます。

基本的にはDALL・Eと同じようなアーキテクチャを動画に適用させたものと思って問題なさそうです。
具体的なデータセットやマシンリソースについては公開されていませんが、相当な量のデータセットとマシンリソースを使ったことでしょう。
Soraの課題
ここまでSoraの凄さについて見てきましたが、まだまだ解決しなくてはいけない課題があるようです。
物理法則や因果関係への理解
OpenAIはまだまだSoraは現実世界の物理法則の理解が不十分だったり物事の因果が不正確だったり時間経過と共に起きる事象の表現が難しかったりするなどの弱点があると言っています。
その例として取り上げられているのが以下の動画。
ガラスが割れて中身がこぼれるという物理現象を正確に捕捉できていません。
このようにSoraはまだまだ完璧ではないようです。
危険性への配慮
Soraのモデルは本記事執筆時点で一般向けには公開されていません。
というのも一般向けにこれほどまでな高品質の動画を生み出せるモデルを公開してしまうと悪用される危険性があるからです。
Soraが公開されたらネット上はフェイク動画だらけになるでしょう。
そのため、OpenAIは悪用される危険性を危惧して専門家と共に悪意のあるコンテンツが生み出されないようなチューニングをかけているようです。
Sora まとめ
ということでSoraについて解説してきました!
Soraを誰でも使えるようになる日が待ち遠しいですね!
さらに詳しくAIやデータサイエンスの勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスの「08.ディープラーニング」コースや
「大規模言語モデル(LLM)・生成系AI」コースで体系的に学ぶことが可能ですので是非参考にしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















