
第1種の過誤・第2種の過誤について解説!有意水準・検出力についても詳しく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回は第1種の過誤・第2種の過誤について解説していきます!第1種の過誤・第2種の過誤とは「仮説が正しいにも関わらず棄却される確率」「仮説が間違っているにも関わらず棄却されない確率」と定義されています。つまり本来正しい結果が歪んでしまい、間違った判断を行ってしまうことを意味しています。
この記事では、第1種の過誤・第2種の過誤、有意水準・検出力について解説します!
・第1種の過誤・第2種の過誤について解説!
・有意水準・検出力について解説!
以下のYoutube動画でも解説していますのであわせてチェックしてみてください!
第1種の過誤・第2種の過誤について解説!

早速、第1種の過誤・第2種の過誤について解説していきましょう!
第1種の過誤・第2種の過誤を表でまとめると以下の通りになります!
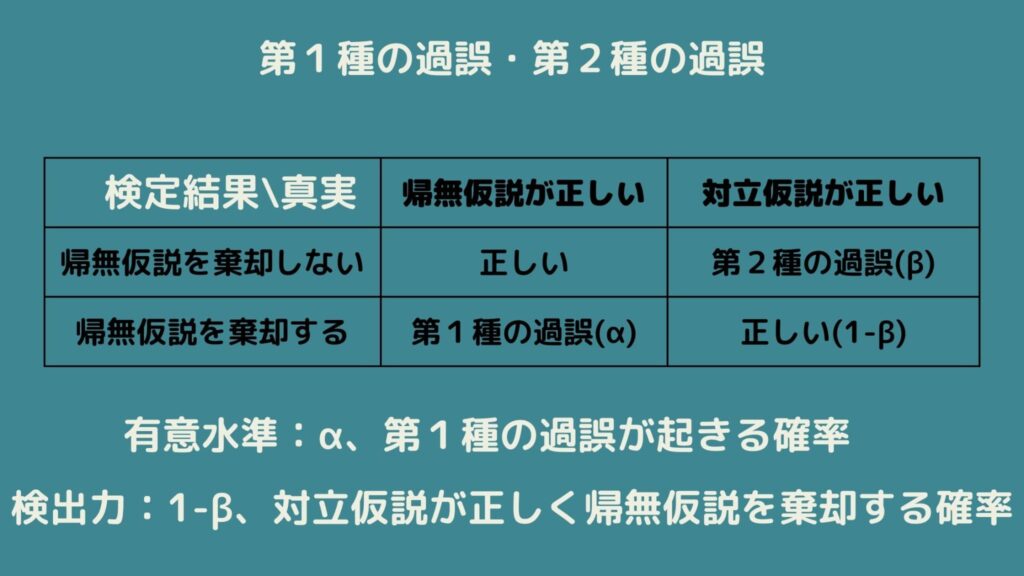
これだと分かりづらいと思うので、例を挙げてみましょう。
とある患者がガンを患っているか確認したいといったケースを考えます。
この時、統計的検定で本当にガンを患っているかを確認するとして、帰無仮説を「この患者はガンを患っていない」、対立仮説を「この患者はガンを患っている」と設定します。
通常、帰無仮説は「差がない」「効果がない」「関係がない」といった仮定をします。
第1種の過誤とは帰無仮説が正しいにも関わらず帰無仮説を棄却してしまう確率です。
すなわちこのケースでは、「患者がガンを患っていないにも関わらず、検査の結果、ガンを患っていると判断される」確率になります。
一方で、第2種の過誤とは帰無仮説が正しくないのにも関わらず帰無仮説を棄却しない選択をしてしまう確率です。
すなわちこのケースでは、「この患者がガンを患っているにも関わらず、検査の結果、ガンを患っていないと判断される」
この時、第1種の過誤・第2種の過誤が起きる確率がどちらも低ければ低いほど良いのですが、残念なことに、これらはトレードオフの関係にあることに注意しましょう!
したがって第1種の過誤・第2種の過誤のバランスをとることが重要です!
たとえば今回のケースでは、
「患者がガンを患っていないにも関わらず、検査の結果、ガンを患っていると判断される」ケースと、
「この患者がガンを患っているにも関わらず、検査の結果、ガンを患っていないと判断される」ケースでは、
どちらがなるべく起こってほしくないでしょうか?
仮に患者がガンを患っていないにも関わらず、検査の結果ガンを患っていると判断されたとしても、それほど重大な問題ではありません。
一方でこの患者がガンを患っているにも関わらず、検査の結果ガンを患っていないと判断されてしまうのは、大きな問題に発展する可能性があります。
すなわち今回のケースでは第2種の過誤を極力下げる努力が大事になります。
そうした結果ほとんどの人をガンと診断するようになっては元も子もないので結局はバランスなのですが、問題設定や領域によってこの第2種の過誤と第1種の過誤のバランスは変わってきますので注意しましょう!
有意水準・検出力について解説!

そして第1種の過誤・第2種の過誤と関連がある概念が有意水準・検出力となります。
有意水準\(α\)とは、帰無仮説が正しいにもかかわらずそれを棄却してしまう確率のことであり、有意水準\(α\)は第1種の過誤を犯す確率そのものを意味していることがわかります。
一方、検出力\(1-β\)とは「帰無仮説が正しくないとき、帰無仮説を棄却する確率」を意味しています。
この時、\(β\)は第2種の過誤を犯す確率を意味しています。
第1種の過誤・第2種の過誤 まとめ

本記事では第1種の過誤・第2種の過誤についてまとめました!
検定にはt検定・カイ二乗検定・F検定がありますので、こちらの記事も見てみると良いでしょう!



このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















