【5分で分かる】クラスター分析のPythonとRでの実装方法を見ていこう!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
大量のデータセットをいくつかのグループ・セグメントに分けたい!
そんな時は「クラスター分析」!
クラスター分析は、非常に便利で様々な場面でよく使われますので覚えておきましょう!
この記事では、そんなクラスター分析についてまとめていきます。
以下の動画でも分かりやすく解説しているので是非チェックしてみてください!
目次
クラスター分析は教師あり学習or教師なし学習?
解析手法には教師あり学習と教師なし学習があるのですが、クラスター分析はどちらでしょうか?
教師あり学習というのは、どのグループに属するかという”ラベル”がついている既知データが手元にあり、それを用いてモデルを作って、”ラベル”がついていないデータの分類に用いるという手法。
ただ、教師あり学習は、「これはここに入るんだよ~」と丁寧に教えてくれる教師がいる状態じゃないと解析できないんですね!
教師なし学習は、ラベル付きデータがない状態であるデータを分類するような手法。
「これはここに入るんだよ~」と丁寧に教えてくれる教師がいなくても解析できる!優秀な手法です!
さて、もう一度!
クラスター分析は教師あり学習手法でしょうか、教師なし学習でしょうか?
クラスター分析は・・・
「教師なし学習!」
教師あり学習にはランダムフォレスト・SVMなど強力な手法が強いですが、既知の学習データがないような状況では解析できないので注意が必要ですね!
クラスター分析を始めとする教師なし学習は既知の学習データがなくても使えるので最終アウトプットへの橋渡しとして多く用いられています。
それでは早速クラスター分析について見ていきましょう!

クラスター分析の種類
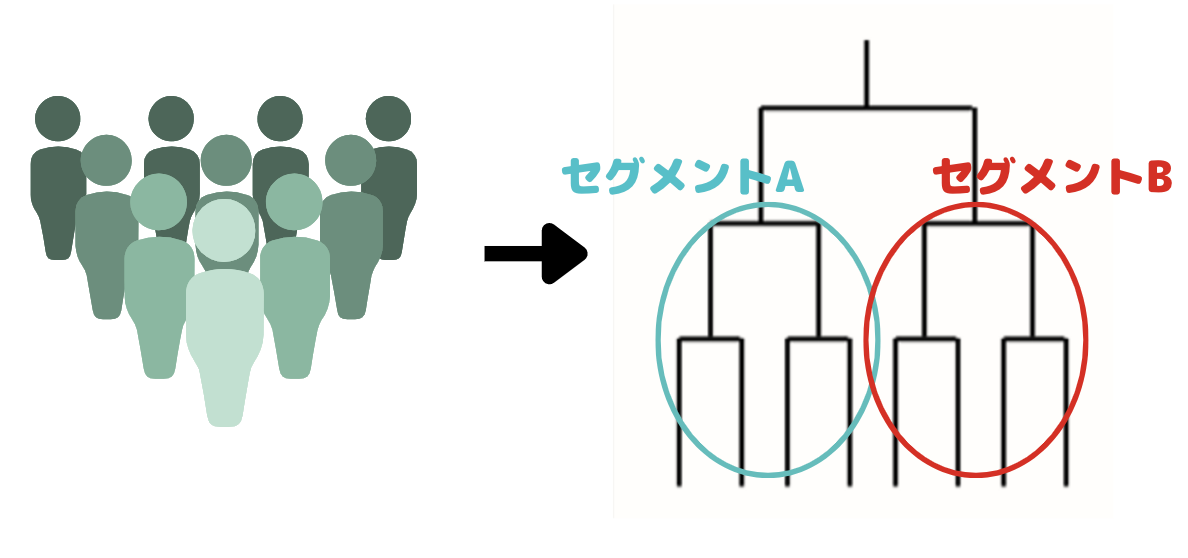
クラスター分析と一口に言っても階層的クラスター分析と非階層的クラスター分析があります。
一般的に最初に勉強するのは階層的クラスター分析。
階層的クラスター分析のことを単純にクラスター分析と呼んでいる例もあります。
それぞれの特徴について見ていきましょう!
階層的クラスター分析
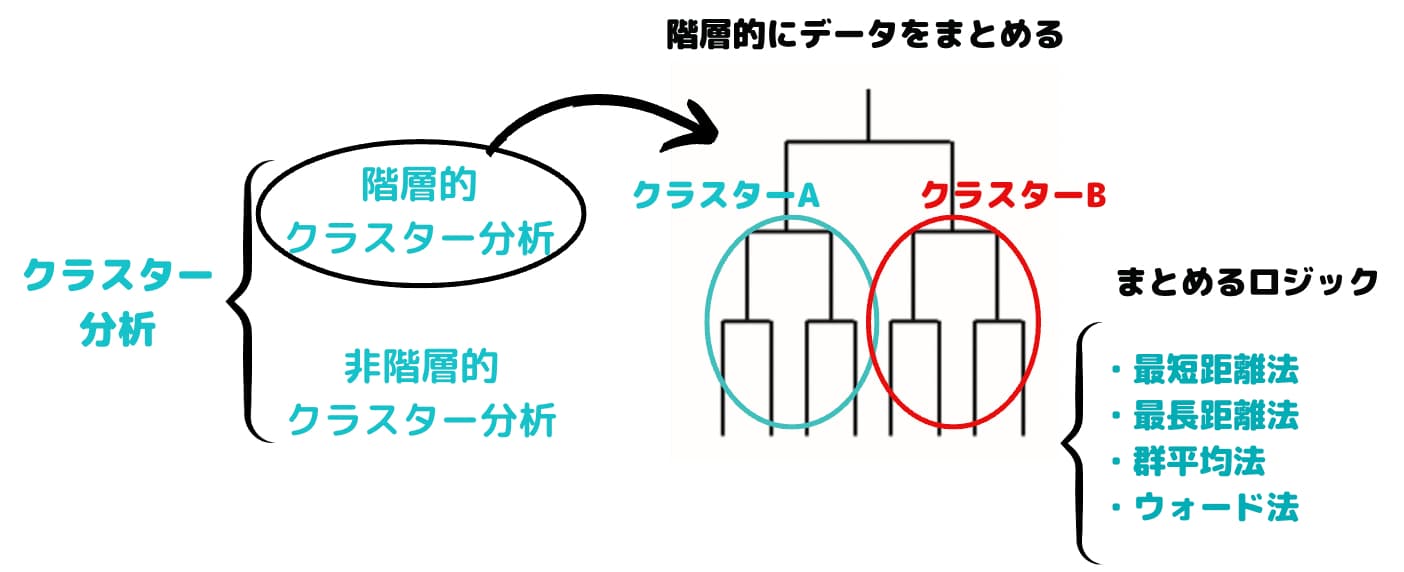
階層クラスター分析では木構造のような図を作ってクラスター分けを行います。
ある類似度を表す指標をもとにサンプルを融合していき、最終的に一つのクラスターを作る手法です。
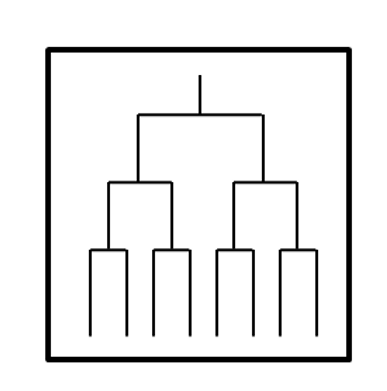
簡易的な図ですが、こんな感じの木を描いて分類していきます。
この時、どこで切るかによってクラスターの数が変わるのがお分かりでしょうか?
このように階層的クラスター分析では木構造を作った後にどこで切るかを考えクラスターの数を決めます。
以下の豊田先生の書籍を参考に具体的なクラスター分析のアルゴリズムを見ていきます!

手順1:変数を用いて個々の対象間の距離をすべて計算し、その中で距離が最も短い対象同士を併合して最初のクラスターを作成する。
手順2:新しく併合されたクラスターと他の対象間の距離を再度計算し、手順1で計算された対象間の距離を含めて最も近いものを併合する。その際、新しく併合されたクラスターと対象間、および、クラスター間の距離の定義にはさまざまな方法が提案されているが、それは後ほど紹介する。
手順3:手順2をくり返し、すべてのクラスターが統合されるまで計算を行う。
手順4:計算結果を用いて、クラスターの併合される過程を表すデンドログラム(さっきの木構造みたいなやつ)を描く。
この手法は、N 個の対象からなるデータが与えられたとき、1個の対象だけを含む N 個のクラスターがある初期状態をまず作る。
この状態から始めて、対象 x1とx2の間の距離 d(x 1 ,x 2 ) からクラスター間の距離 d(C 1 ,C 2 ) を計算し、最もこの距離の近い二つのクラスターを逐次的に併合する。
そして、この併合を全ての対象が一つのクラスターに併合されるまで繰り返すことで階層構造を獲得する。
クラスターC1とC2の距離関数 d(C 1 ,C 2 )の違いにより以下のような手法がある。
・最短距離法
\begin{eqnarray*}
d(C_1,C_2)=\min{d(x_1,x_2)}
\end{eqnarray*}
・最長距離法
\begin{eqnarray*}
d(C_1,C_2)=\max{d(x_1,x_2)}
\end{eqnarray*}
・群平均法
\begin{eqnarray*}
d(C_1,C_2)=\frac{1}{|C_1||C_2|}\Sigma\Sigma{d(x_1,x_2)}
\end{eqnarray*}
・ウォード法
\begin{eqnarray*}
d(C_1,C_2)&=&E(C_1\lor{C_2})-E(C_1)-E(C_2)\\
E(C_1)&=&\Sigma(d(x,b_i))^2\\
b_i&=&\Sigma{\frac{x}{|C_i|}}\\
\end{eqnarray*}
クラスター間の距離を測る方法にはいくつか種類がありますが、一般的にはウォード法を用いることが多いです!

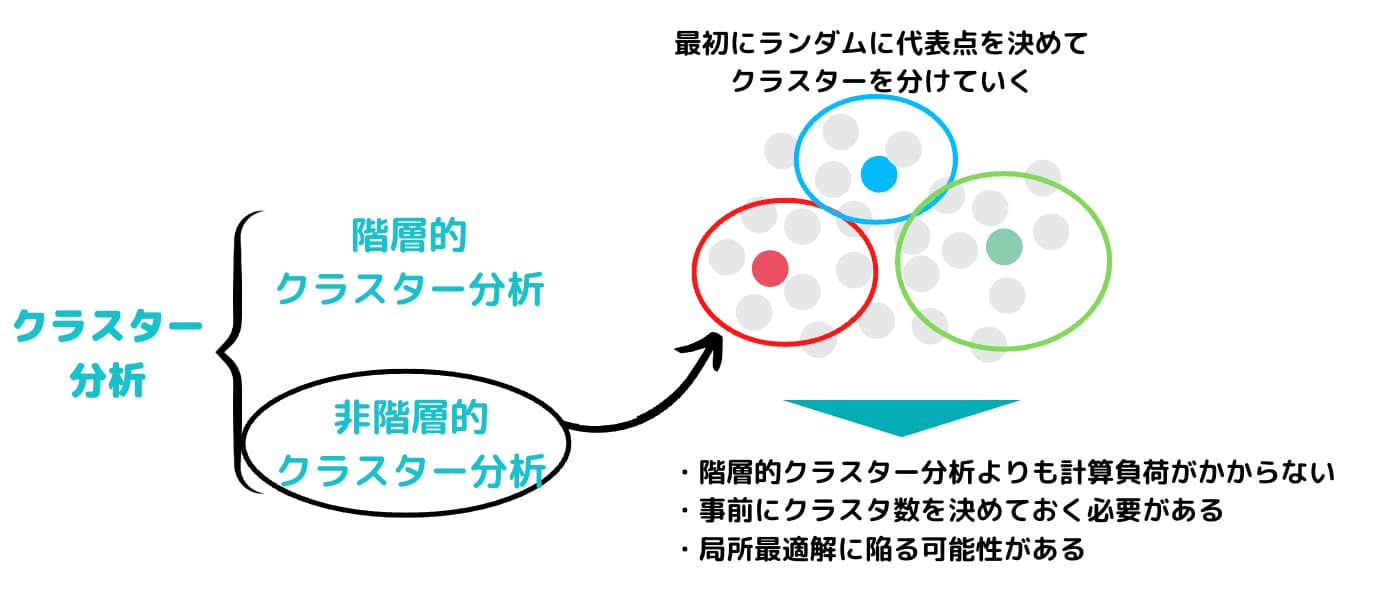
非階層的クラスター分析
続いて、非階層的クラスター分析を見ていきましょう!
非階層的クラスター分析は、その名の通り階層構造を作りません。
階層的クラスタリングと異なり、階層的な構造を持たず、あらかじめいくつのクラスターに分けるかを決め、決めた数の塊にサンプルを分割する方法です。
非階層的クラスター分析では、分割の良さの評価関数を定め、その評価関数を最適にする分割を探索します。
可能な分割の総数は指数的に増えていくので、実際は準最適解を求めることになります。
その中でも代表的なものがk-means法です。
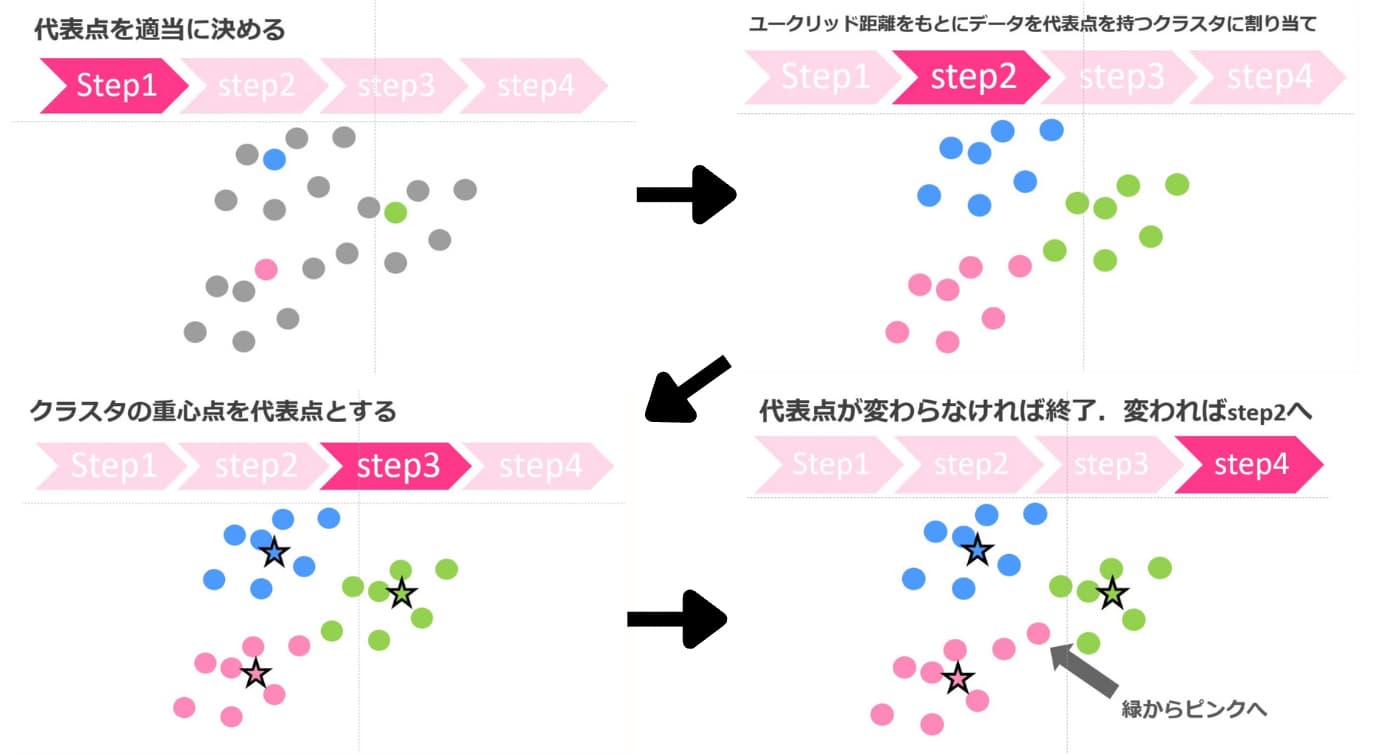
簡単なアルゴリズムは以下の通りです。
1.代表点を適当に決める
2.ユークリッド距離をもとにデータを代表点を持つクラスタに割り当て
3.クラスタの重心点を代表点とする
4.代表点が変わらなければ終了。変われば2へ
非階層的クラスター分析は、あらかじめクラスタ数を与える必要がありますが、計算スピードが速いです。
k-means法に関して詳しくはこちらにまとめています!
階層的クラスター分析と非階層的クラスター分析の違い

階層的クラスター分析の方が、視覚的に分かりやすく、なぜそのクラスタ数に分けたのかが説明しやすいです。
しかし、データ数が膨大になると非常に計算負荷がかかってしまうのでビックデータを扱う上ではあまりオススメしません。
結局クラスター分析は、何かしらの特徴を基にデータをグループに分けてくれるだけです。それらのグループに意味を与えるのはマーケターの仕事です。

非階層的クラスター分析を行う場合は、当たりを付けてクラスタ数を動かしながら最適なグループ分けを見つけると良いでしょう。
ちなみに最適なクラスタ数を与えてくれる非階層的クラスター分析「x-means法」という手法も存在しますが、高度なのでここでは省略します。
ベイズ情報量基準(BIC)を基に最適なクラスタ数を算出してくれます。
使った感想としては、必ずしも最適なクラスタを算出してくれるとは限らないイメージです。
k-means法を使いながらクラスタ数をチューニングしていった方が手間はかかりますが、最適なクラスタが見つかります。
興味のある方は調べてみると良いでしょう!
クラスター分析をRで実装してみよう!

最後にクラスター分析でRを実装していきましょう!
本当に簡単に実装できちゃうんです!
irisというめちゃんこ有名なデータセット(150サンプル5変数で花びらの特徴を表したデータセット)を使います。
以下がコードです。
3つの花のタイプに分かれているので、そのラベルがk-means法で上手く分類できるかどうか見ていきます。
実際に行ってみた結果がこちら
| 1 | 2 | 3 | |
| setosa | 0 | 50 | 0 |
| versicolor | 48 | 0 | 2 |
| virginica | 14 | 0 | 36 |
Verginicaは少し外してますが、それ以外は比較的当たってますね!
正答率は89%です。
こんな感じで非常に簡単にクラスター分析を実装することが可能なので是非やってみてください!
クラスター分析をPythonで実装してみよう!

Rでもできますし、もちろんPythonでも実装できちゃいます!
同じくirisデータを分類してみましょう!
やっていることはRと変わりません。
正答率は88%になりました!
RもPythonもクラスター分析を行う分にはそれほど変わりませんが、Pythonの方ができることの幅が広いのでPythonに慣れておくことをオススメします!

Pythonの勉強方法については以下にまとめていますので参考にしてみてください!

クラスター分析をビジネスで活かす場面

さて、クラスター分析の種類や仕組み・そしてRでの実装について分かったところでどのようにビジネスに活かしていけばよいのか見ていきましょう!
ここでは2つの観点でクラスター分析の使いどころを見ていきます。
・セグメントの可視化
・教師あり学習の特徴量生成
セグメントの可視化
もう既にお分かりの通り、クラスター分析を使えばお客さんの行動データや属性データを基にいくつかのセグメントに分けることができます。
あるセグメントは、年配の女性で購入金額が高い層、
もう一方のセグメントは、若い男性で購入金額が低い層、などが考えれます。
この2つのセグメントに対して行うコミュニケーションは変えるべきだということが分かりますね。
このように、セグメントの可視化を行いセグメントのユーザー像を明確にすることで、マーケティング活動を効率化することが可能になります。
このセグメントの可視化においてユーザー像を想像するのはマーケターの腕の見せ所で、クラスター数を変化させてどのようなセグメント定義であれば最適なコミュニケーション設計ができるのか考えていくことになります。
教師あり学習の特徴量生成

先ほども紹介しましたが、教師あり学習というのは正解が紐づいているデータを学習する手法のことを指しましたね。
教師あり学習を使うと、過去の顧客の購買という正解データから未来の購買を予測することが可能です。
そんな、顧客の購買を予測するときにクラスター分析で得られたクラスターを特徴量として新たに追加して使うことがあります。
これによりインプットされるデータがリッチになって、他の特徴量で表現できなかったことが表現できるようになる可能性があります。
つまりクラスター分析によって生成された特徴量を使って顧客の購買予測精度の向上が見込めるんです。
特徴量に関するテクニックは以下の記事で詳しくまとめています!

効果が本当に見込めるかどうかはデータによりますが、精度を向上させる手段として覚えておくとよいでしょう!
1つ目の可視化に関しては現状を把握することに重きが置かれていましたが、2つ目では予測の精度を高めるための1つの情報として使われました。
どちらもやっていることはさほど変わらないのですが、クラスター分析には色々な使い方があるということは理解しておきましょう。
クラスター分析 まとめ
クラスター分析は多くの場面で使用できる汎用性の高い手法なんです。
最後にクラスター分析についてまとめておきましょう!
・クラスター分析はデータをグループ分けする手法
・クラスター分析には階層的クラスター分析と非階層的クラスター分析がある
・データ量が多いときは非階層的クラスター分析の方がオススメだけど、あらかじめクラスタ数を決めておく必要がある
是非クラスター分析を使ってみてください!
何の変哲もないデータにクラスター分析をかけることで洞察を得ることができるかもしれませんよー!
以下の書籍でクラスター分析について学べるので興味のある方は目を通してみるとよいでしょう!

機械学習やPythonやデータサイエンスについて学びたい方はぜひ以下の記事をチェックしてみてくださいね!


データサイエンティストになるための勉強がしたい!という方は当サイト「スタビジ」が提供するスタビジアカデミーというサービスで体系的に学ぶことが可能ですので是非参考にしてみてください!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!