
回帰分析の残差の求め方について解説!誤差との違いと残差プロットについてわかりやすく!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
今回は残差について解説していきます!残差とは「実測値と予測値の差分」と定義されています。重回帰分析などを使用した後、残差を確認しないと手法が適切であったのか確認できないため、忘れがちですが残差をよく見る必要があります!
この記事では、残差の定義と誤差との違い、残差プロットについて解説します!
・残差について解説!
・誤差との違いについて解説!
・残差プロットをPythonで実装!
残差について以下の動画でも解説していますのであわせてチェックしてみてください!
残差について解説!

残差とは「実測値と予測値の差分」と定義されています。
実測値とは実際に得られたデータそのもの、予測値はデータをモデルに適用した後の推定値ですね!
例えば回帰分析をした結果の残差を式で表すと以下になります。
\(e_{i} = y_{i} – (\hat{β}_{0} + \hat{β}_{1}x_{i})\)
重回帰分析の係数にハットがついている理由は、推定した統計量を示しているからです。
誤差と残差の違いについて解説!

統計学を学んでいると「誤差」と「残差」が出てくると思いますが、単語は似ているようで意味は全く異なるものなので注意する必要があります!
誤差とは「真の回帰式から出た値と実測値との差分」を意味しています。この真の回帰式とは母回帰式、つまり母集団のように集合全体から推測される回帰式と考えてください。しかし、実測値は母集団から抽出されたものなので、これを推定した回帰式とは全く別物と考えてください。
誤差は以下のような式で表すことができます!
\(u_{i}=y_{i} – (β_{0}+β_{1}x_{i})\)
先ほどの残差と異なる点として、回帰式の係数にハットがついていないことです。つまりこの回帰式は真の回帰式を示していることになります。
文字だけだと分かりづらいので、図で見てみましょう!
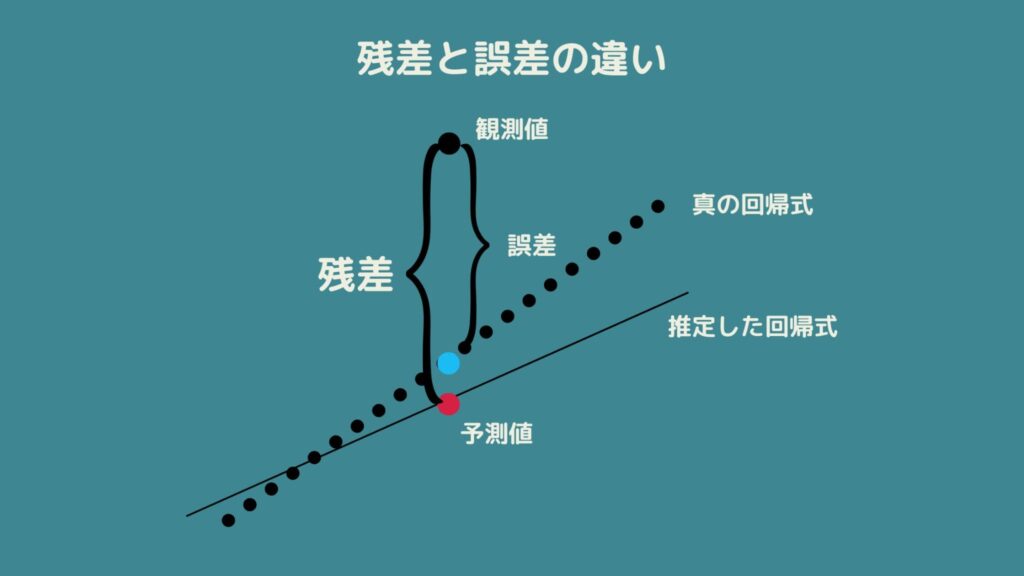
このように残差と誤差は異なるものであることが分かったと思います!
残差プロットをPythonで実装!

さて、残差について解説してきましたが、残差を見ることで何がわかるのでしょうか?
まず初めに残差の外れ値があるか確認できることです。外れ値があるということは予測値と実測値の差分が非常に大きいことを示しているため、モデルが妥当でない可能性があります。
次に残差に傾向があるか確認できることです。残差プロットが正に偏っていたり負に偏っていたりする場合、未知のデータに対する予測値が大幅に真の値とずれてしまう可能性があります。
このように残差を見ることでモデルに妥当性があるか判断することができます!
実際にBostonデータを用いて、残差プロットを見てみましょう!
Bostonの住宅価格データを扱っていくのですが、scikit-learn==1.2以降のバージョンではBostonの住宅価格データが使えなくなっております。そのためscikit-learnのバージョンを1.2より前にした上でBostonの住宅価格データをご利用ください。
Bostonデータとはボストンの住宅価格データです。今回は目的変数がMEDV(住宅価格の中央値)、説明変数をRM(平均部屋数)とした単回帰分析を実施してみましょう!
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
boston = load_boston()
df = pd.DataFrame(boston.data,columns=boston.feature_names)
df["MEDV"] = boston.target
x_train,x_test,y_train,y_test = train_test_split(df[["RM"]].values,df["MEDV"].values)
model = LinearRegression()
model.fit(x_train,y_train)
predict_y = model.predict(x_test)
plt.scatter(y_test,y_test-predict_y)
plt.hlines(y=0,xmin=0,xmax=60)
plt.show()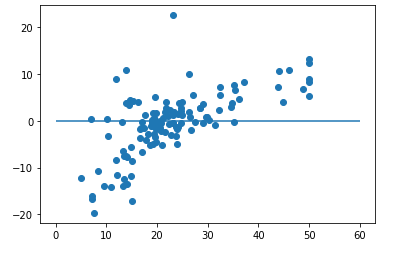
こちらの残差プロットを見るとやや正の傾向があるため、モデルとしての妥当性に疑問が残ります。実際にこのモデルのスコア(寄与率)は0.5492と精度が低いモデルだと分かります。
残差 まとめ

本記事では残差についてまとめました!
残差プロットは様々な手法で使われており、特に回帰分析、リッジ・ラッソ回帰に使うので、こちらの記事を見てみましょう!


このようなデータサイエンスの力を身に付けるためにはスタビジの記事やスクールを活用すると良いでしょう。
そして僕の経験を詰め込んだデータサイエンス特化のスクール「スタアカ(スタビジアカデミー)」を運営していますので,興味のある方はぜひチェックしてみてください!
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
当メディアが運営するスクールです。
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
データサイエンスに関する記事はこちら!


データサイエンスを勉強できるスクールやサイトは、ぜひこちらを参考にしてみてください!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















