【5分でわかる】CycleGANの仕組みをわかりやすく解説!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
この記事では、画像を変換する非常に画期的な技術であるCycleGANについてわかりやすく解説していきます!
非常に重要な手法ですのでしっかり理解しておきましょう!
以下のYoutube動画でも詳しく解説していますのでチェックしてみてください!
CycleGANとは?
CycleGANは2017年に発表された手法で論文は以下です。
以下の画像は論文内から引用したもの。


リアルな画像を有名な画家の絵のタッチに変換したり馬をシマウマに変換したりすることが可能なのです!
画像変換の画期的な手法として当時話題になりました。
CycleGANの仕組み
それでは、CycleGANとはどのようなアプローチなのでしょうか?
先ほどもお伝えした通り、CycleGANは特定の画像を別の画像に変換するアプローチ。
改めて論文は以下です。
それではそんなCycleGANの仕組みを見ていきましょう!・・・といきたいところですが、まずはCycleGANのベースとなっているGAN(Generative Adversarial Networks)という技術を確認しておきましょう!
ベースとなっているGAN
GAN(Generative Adversarial Networks)は2014年に発表された手法で、論文は以下です。
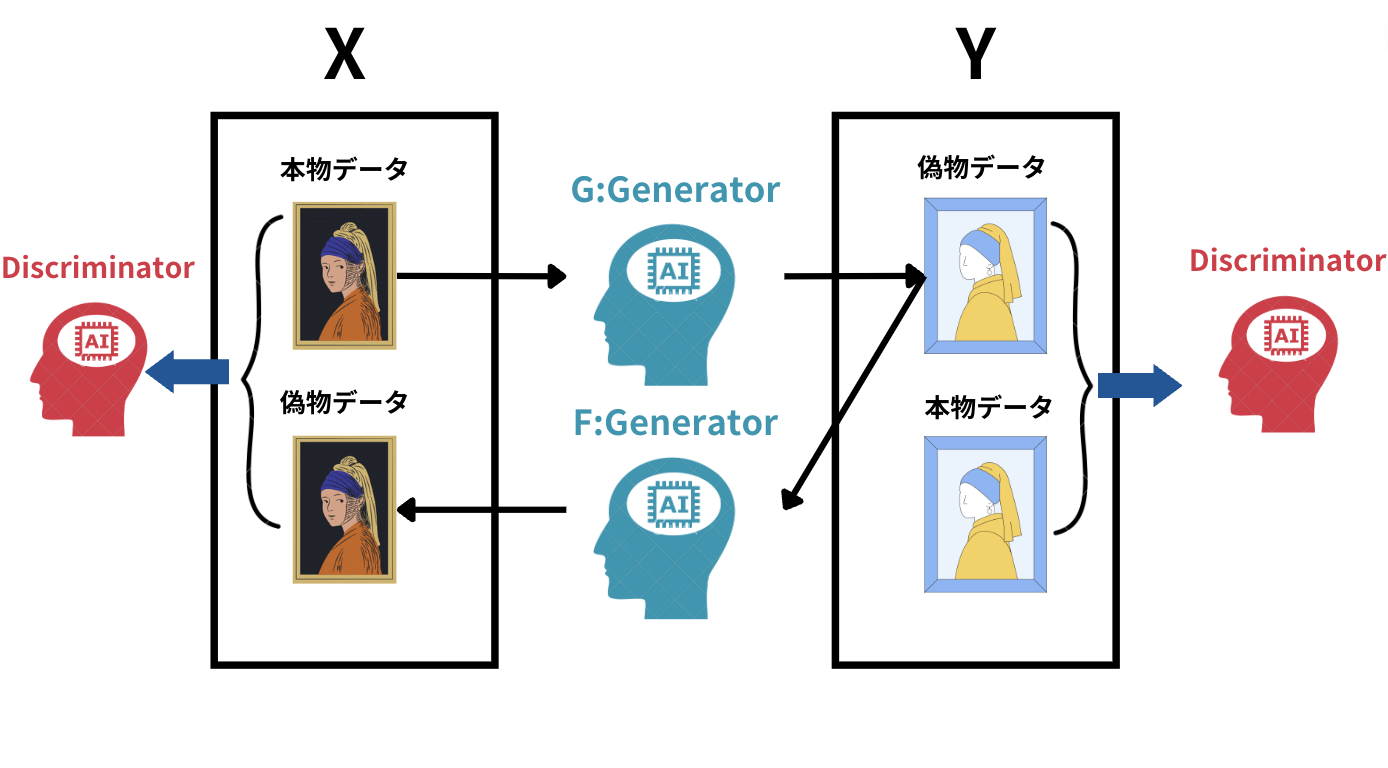
GANの仕組みは非常にシンプル。
- 2つのGeneratorとDiscriminatorと呼ぶニューラルネットワークを用意します。
- Generatorは偽物のデータを生成します
- DiscriminatorはGeneratorが生み出した偽物のデータと本物のデータを判別しま
- これらを競い合わせ2・3を繰り返すことで、Generatorが生み出すデータが本物に限りなく近いものになっていきます。
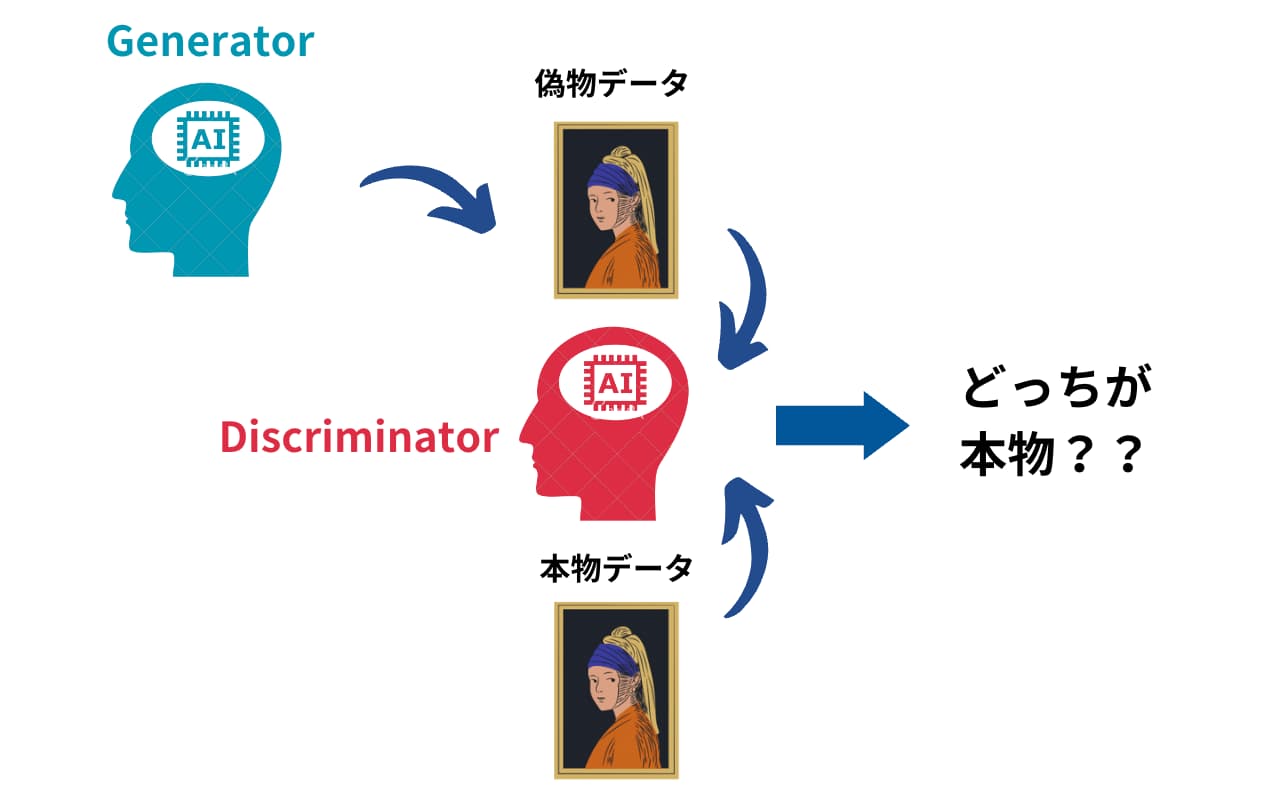
シンプルな仕組みですが、2つのニューラルネットワークを競い合わせることにより高精度の画像を生成できるモデルが構築できるのです。
両者を競い合わせることからこのアプローチはGAN(敵対的生成ネットワーク)と呼びます!
GANについてよりもっと詳しく知りたいという方は以下の記事をチェックしてみてください!

pix2pixと比較して分かる教師なし学習による画像変換
CycleGANの凄さを知るために比較対象として知っておいて欲しい手法にpix2pixというものがあります。
pix2pixのアーキテクチャは以下のようなイメージ。
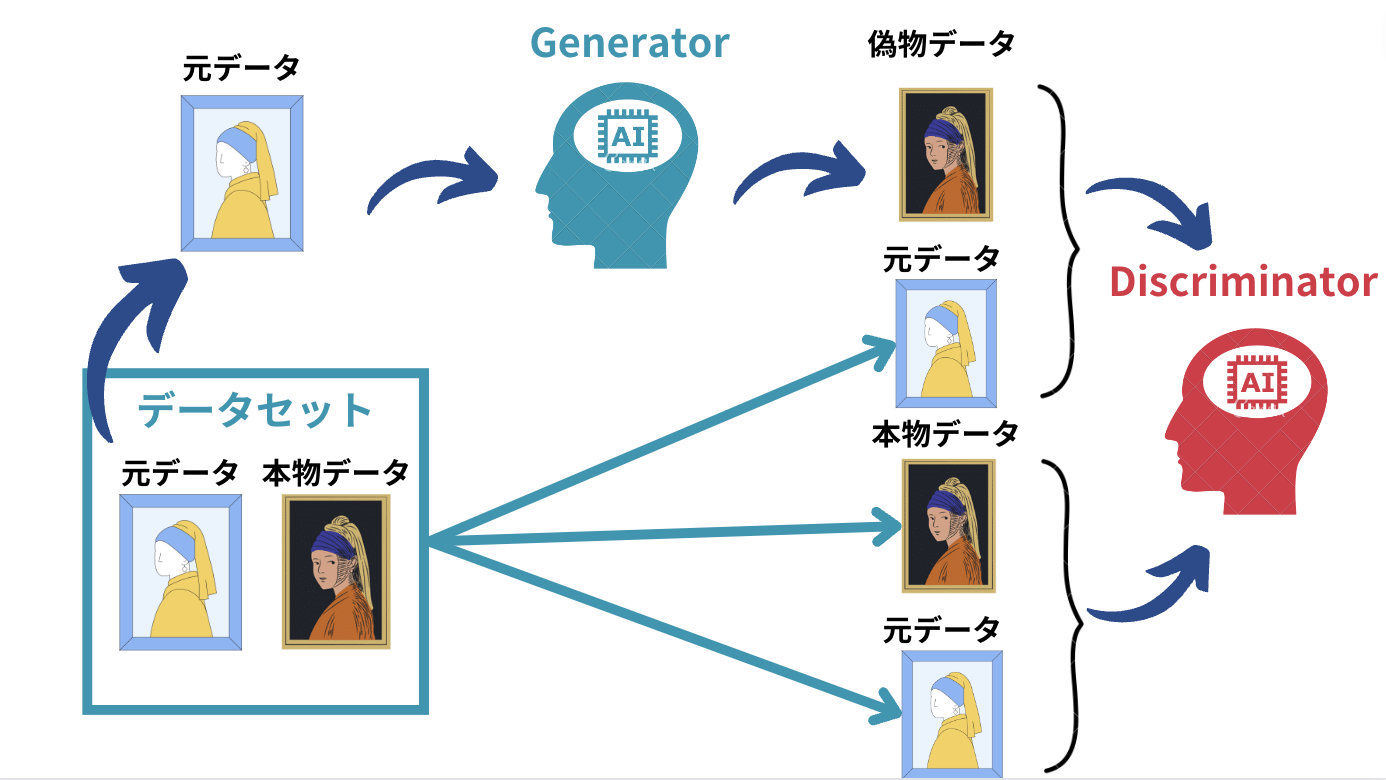
pix2pixは「変換前の元データ」と「変換後の本物データ」のペアの正解画像を用意しておき、それを元に変換前の元データ画像からGeneratorを通して「本物データに近い偽物データ」を生成します。
そしてDiscriminatorはそれらの組み合わせが偽物か本物か判断します。
GANと同じ要領で、「本物データ」と「偽物データ」の差分が小さくなるように学習します。
すなわち最初から元データと本物データのペアが存在する、教師あり学習なのです。
pix2pixの論文(Image-to-Image Translation with Conditional Adversarial Networks)に掲載されている画像変換の例は以下です!

左上の「Labels to Street Scene」というやつは、セマンティックセグメンテーションで自動車などの対象物を「セグメントした画像」と「元々の画像」のペアであり、他の画像も「変換前の画像」と「変換後の画像」のペアが存在するものになってます。
では一方で以下のCycleGANの変換前と変換後の画像はどうでしょう?
背景も同じで全く同じ動作をしている馬とシマウマの写真など手に入れることは可能でしょうか?
なかなか不可能に近いですよね?
そうなんです、馬とシマウマの変換や写真と画家の画像の変換など、本来なかなかペアの画像が存在し得ないものの変換に成功しているのです!
つまりCycleGANは明確な教師データが存在しない教師なし学習になるのです!!!

以下はCycleGANの論文から引用したものです。
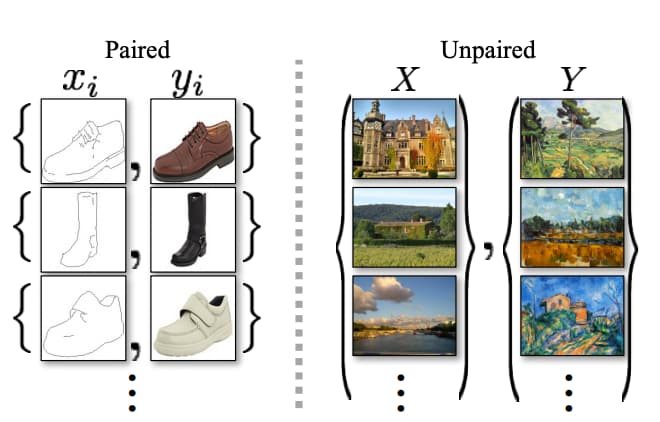
(出典:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks)
左はペア画像になっていて、右はペアになっていないことが分かります。
右のようにペアになっていない「風景写真のデータセット」・「風景絵画のデータセット」を投入していい感じに相互変換するモデルが作れるのがCycleGANなのです!
CycleGANのアーキテクチャ
それではお待ちかね、CycleGANのアーキテクチャを見ていきましょう!
以下は論文から引用したものです。
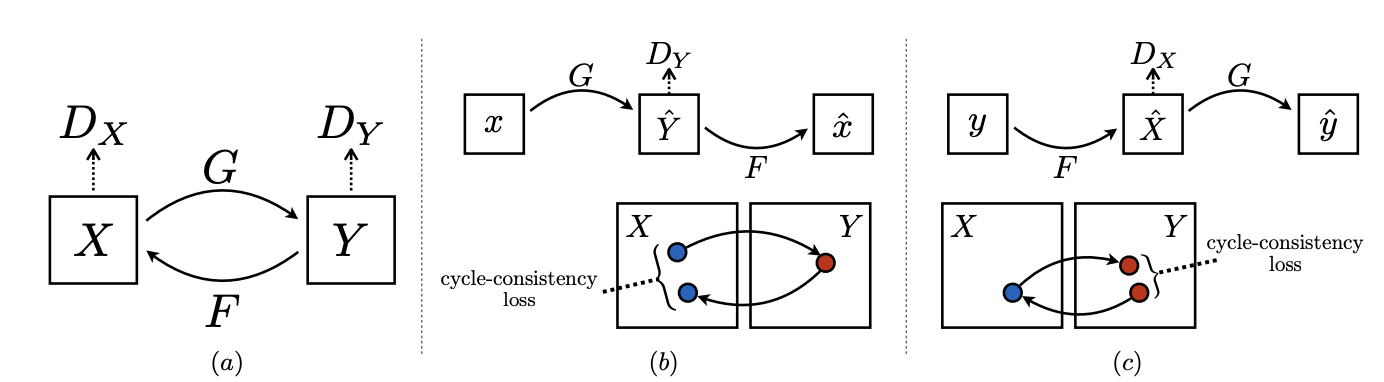 (出典:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks)
(出典:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks)
その名の通り、なにやらXとYというペアになっていないデータセットをサイクルしてます。
DxとDyがそれぞれGANのDiscriminatorのことで、GとFがそれぞれGeneratorになります。
これをもう少し分かりやすく描くと以下のようになります。
Xというデータセット(例:色付きの絵画)とYというデータセット(例:色なしの絵画)のそれぞれをGeneratorで相互変換しDiscriminatorで真贋を判別するアプローチ。
- Xを一旦Yに変換し、その状態でYの偽物データが本物かどうかをDiscriminatorが判断します。
- 変換後のYをXに再変換し、再変換後のXが元の画像なのか変換後の画像なのかを別のDiscriminatorが判断します。
すなわちここでは通常のGANで使われる敵対的損失(Adversarial Loss)に加えてサイクルで元に戻した時の損失であるサイクル一貫性の損失(Cycle Consistency Loss)という2つの損失を最小化するような学習が行われるのです!
これによりペア画像でない教師なし学習でも前述のような画像変換が可能になっているのです!
CycleGAN まとめ
ここまでご覧いただきありがとうございました!
本記事ではCycleGANについて解説してきました!
CycleGANのPythonでの実装は以下のGithubに詳しくまとめてあります。
PyTorchを使うパターンとTensorFlowを使うバージョンがあります。
興味のある方は実装してみましょう!
他にも多くのディープラーニングのモデルがあります。
ディープラーニングの様々なモデルを知りたい方は以下の記事を参考にしてみてください。
・RNN
・AlexNet
・ResNet
・Transformer
より詳しくディープラーニングや最近の大規模言語モデルについて知りたい方は当メディアが運営する教育サービス「スタアカ(スタビジアカデミー)」の講座をチェックしてみてください。
AIデータサイエンス特化スクール「スタアカ」

| 【価格】 | ライトプラン:1280円/月 プレミアムプラン:149,800円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【受講形式】 | オンライン形式 |
| 【学習範囲】 | データサイエンスを網羅的に学ぶ 実践的なビジネスフレームワークを学ぶ SQLとPythonを組み合わせて実データを使った様々なワークを行う マーケティングの実行プラン策定 マーケティングとデータ分析の掛け合わせで集客マネタイズ |
データサイエンティストとしての自分の経験をふまえてエッセンスを詰め込んだのがこちらのスタビジアカデミー、略して「スタアカ」!!
24時間以内の質問対応と現役データサイエンティストによる複数回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
他のスクールのカリキュラムはPythonでの機械学習実装だけに焦点が当たっているものが多く、実務に即した内容になっていないものが多いです。
そんな課題感に対して、実務で使うことの多いSQLや機械学習のビジネス導入プロセスの理解なども合わせて学べるボリューム満点のコースになっています!
Pythonが初めての人でも学べるようなカリキュラムにしておりますので是非チェックしてみてください!
ウォルマートのデータを使って商品の予測分析をしたり、実務で使うことの多いGoogleプロダクトのBigQueryを使って投球分析をしたり、データサイエンティストに必要なビジネス・マーケティングの基礎を学んでマーケティングプランを作ってもらったり・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践してもらったりする盛りだくさんの内容になってます!
・BigQuery上でSQL、Google Colab上でPythonを使い野球の投球分析
・世界最大手小売企業のウォルマートの実データを用いた需要予測
・ビジネス・マーケティングの基礎を学んで実際の企業を題材にしたマーケティングプランの策定
・Webサイト構築してデータ基盤構築してWebマーケ×データ分析実践して稼ぐ
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!