
【具体例あり】AIプロジェクトの失敗する原因3つと失敗しないで進める方法!


こんにちは!
日経大手、外資、スタートアップでデータサイエンティスト・デジタルマーケターとして働いた経験があり現在は株式会社ダブダブの代表取締役兼データサイエンティストのウマたん(@statistics1012)です!
私自身、既存産業でAIや機械学習を使った業務改革や新規サービスの立ち上げをやってきましたが、結局何も生み出せないという悔しい失敗も経験してきました。
多くの企業でAI・機械学習という言葉が1人歩きしており、魔法を起こしてくれる特別なものというイメージを持たれがちですが、AI・機械学習は魔法でもなんでもありません。
残念ながらAI・機械学習を標榜したプロジェクトを確実に成功させる夢のようなノウハウはありません。
ただ、確実に失敗する原因はいくつかあります。

そこで、この記事ではAI・機械学習を標榜したプロジェクトが失敗する原因について3つ紹介しておきたいと思います。
もしあなたがAIや機械学習を使って何か新しい改革を起こしたいと考えているのであれば是非参考にしてみてください!
以下のYoutube動画でも分かりやすく解説しています!
目次
AIとは

まずはじめに簡単にAIについておさえておきましょう!
そもそも人工知能(AI)とは何でしょうか?
少し前からAIという言葉が色んなところで聞かれるようになり、今では聞かない日はないまでになりました。
これほどまでに様々な場で使われているAIという言葉ですが、実際にどのような定義で使われているのかご存知でしょうか?
人工知能(AI)と聞くとディープラーニングを思い浮かべる人も多いのではないでしょうか?
しかしディープラーニングが登場したのは2006年であり、人工知能という言葉はそれよりもずっと前からある言葉。
必ずしも人工知能(AI)=ディープラーニングとは言えないのです。
よく言われるのが、人工知能(AI)の中に機械学習がありその中にディープラーニングがあるという構造。
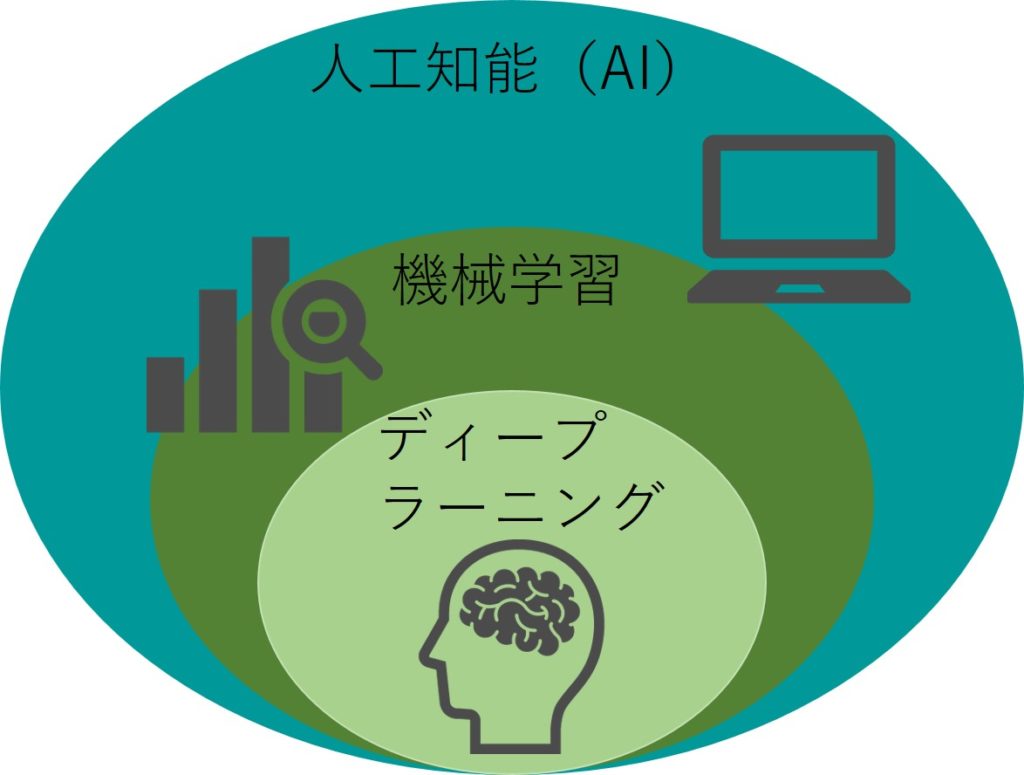
だからこそ人工知能(AI)という言葉は軽々しく使ってはいけないのです。
人工知能(AI)は定義の範囲が広く、簡単なルールベースのアルゴリズムでもAIだし機械学習もAIだしもちろんディープラーニングもAIだし。
どの文脈で人工知能(AI)という言葉が使われているかは注意しなくてはいけません。
AIについてより詳しく知りたい方は以下の記事でまとめていますのでチェックしてみてください!

AIプロジェクトが失敗する原因3つ

それでは、そんなAIを標榜したプロジェクトが失敗してしまう原因について簡単に見ていきましょう!
目標がない

まずはじめに目標がない!
いやそんなの当たり前だろ!というツッコミはあると思いますが、最も多いのがこのパターンだと思います。
目標はさすがにあるよ!と思っていてもその目標は本当に明確でしょうか?
〇〇の業務を効率化したいという目的を明確な目標に落とし込めていますか?
目標が大事というのは全てのプロジェクト・仕事において言えることなのですが、特にAI・機械学習案件は、AIを導入すること自体が目標になってしまうケースが多いです。
〇〇の業務を改善したい!という目的でプロジェクトがスタートしたとしてもそれを明確な目標に落とし込まないとプロジェクトは失敗します。
有名なフレームワークにSMARTという指標がありますが、
目標が
Specific、具体的で
Measurable、計測することができて
Achievable、達成可能で
Related、全社的な目標と関連していて
Time-bound、時間制約を設けている
であるかどうかは必ず確認しましょう!
例えば・・・
人が目視で確認している不良チェックを画像認識技術で自動化したいとしましょう!
Specific:それは具体的にどのくらいの精度で自動化すれば導入要件を満たすのでしょうか?
目検チェックよりも良い精度を求めるのでしょうか?それとも目検チェックより精度が多少悪くても自動化すればよいのでしょうか?
Measurable:実装時の精度についてちゃんとトラッキングできるようになっているのでしょうか?
Achievable:またその精度は現状のデータから本当に達成可能でしょうか?
Related:全社的な方向性と乖離していないでしょうか?もしその事業自体を縮小する方向なのであればいまさら体力を使って業務改善をする必要はないかもしれません
Time-bound:いつまでに行うかタイムスケジュールはしっかりひかれているでしょうか?
全て精緻に行うのは難しい点もあると思いますが、プロジェクトを立ち上げる時点でこれら5つのファクターに関してはしっかりおさえておきましょう!
現場を巻き込まない

続いて現場を巻き込まない。
目標が明確でもその目標を最終的に実現するには現場の協力が必要です。
現場を巻き込まないと達成可能性は大きく下がります。
現場の声を吸い上げて、なんとか業務を自動化できないかということを話し合って推進することが出来れば問題ありませんが、データホルダーや経営層起点でAI・機械学習プロジェクトを走らせてしまうと、現場の抵抗に合う可能性が高いです。
特に既存の業務を改革するためには、現場の抵抗に合うことが多いです。
データホルダーや経営者起点で立ち上げたとしても必ず初期段階で現場にヒアリングを行い現場と話し合い、納得しもらった上で進めるのが吉です。
ここでも先ほどの明確な目標が大事になります。
ステークホルダー間でなんとなくプロジェクトの目的は共有していても、目標が明確になっていないと、いざ導入となった時にそんな予定ではなかったとちゃぶ台返しをくらう可能性もあります。
目標を明確にして現場に納得してもらい業務フローに乗せる最終ゴールイメージを共有してこそプロジェクト達成に近づきます
必ずステークホルダー間でSMARTに沿った目標を定めた上で推進しましょう!
データがない

最後にデータがない。
目標が明確で業務フローに乗せる現実感を伴うプロジェクトがスタートしても、いざデータがなくては何も始まりません。
これも当たり前だと思われるかもしれませんが、意外と潜んでいる落とし穴です。
先ほどの目標を立てるAchievableの段階で検証しなくてはいけない部分ではありますが、明確に目標をステークホルダーと握ったあとにあれデータがない・データが大きく欠損していると気付く可能性もあります。
例えば・・・
あるサービスを顧客が解約してしまうのを防ぐために、顧客の解約予測を行うモデルを作成するとしましょう。
しかし、いざ分析をしようとしてみると解約した顧客のデータは解約後に全て削除されてしまっていることが分かりました。
この状況では、どう頑張っても解約顧客を予測するモデルは作れませんね。
DMPを構築する時にどのようなデータが将来必要になるか考えて設計しましょう!
複雑な手法を使いこなせることよりも、重要なデータを取得しそれを基に重要な特徴量を作り出すことが大事なのです。
AIプロジェクトの失敗事例
私自身、様々なAIプロジェクトに関わってきた中で失敗してしまった事例には枚挙に暇がありません。
その中でも1つ具体的な事例を取り上げてみたいと思います。
そのプロジェクトはメールマーケティングを最適化するプロジェクトで、もともとどの顧客にどのメールを送るかは担当者が経験をもとにセグメントを切って決めていました。
セグメントの切り方としては、
「特定のブランドのLPに1ヶ月以内に訪問した人」
「特定のブランドの商品を1ヶ月以内に購入した人」
などです。
しかし、これは勘と経験に頼っているところがあり最適なセグメントは言い難いです。
そこで、顧客のログデータや購買データなどをもとにどの顧客にどのメールを送るべきかスコアリングし、スコアに応じて自動的に対象ターゲットを振り分ける試みをしました。
強力な手法である勾配ブースティング木を用いて機械学習モデルを構築し、結果的に机上検証では高い精度を出力することができました。
しかしスムーズに導入することができなかったのです。
これは、まさに先ほど取り上げた「現場を巻き込まない」罠です。
もちろんプロジェクトの共有などはある程度されていたものの、基本プロジェクト自体はデータサイドだけで推進してしまったため現場をちゃんと巻き込めておりませんでした。
その結果、この機械学習モデルを採用すると


などの疑問が生じました。
さらに力の弱いブランドの対象セグメントはどうしても狭まってしまう懸念がありました。
機械学習を使うと対象メールに対して目的である売上を全体として最大化することはできるのですが、長期的に見た時に懸念がたくさんあふれたのです。
これは、たしかにそのとおりで機械学習でとりあえず対象の精度だけ上げればよいわけではないということを身にしみて感じた経験でした。
現場導入の壁にぶつかった我々は、機械学習で突破するのではなくマーケティングのあり方や座組を見直ことで突破しました。
機械学習を適用するメールは売上最大化を取りに行くメールと定義し、適用範囲を絞ったのです。
機械学習を適用しないメールに関しては、売上を過度に取り行くわけではないので新ブランドも新ユーザーも広く浅くリーチすることが可能です。
そこから興味を持ったユーザーが機械学習ロジックの元となるデータに貯まっていき売上最大化メールのリストにも入ってくるという良い流れを構築することができました。
これはほんの一部の事例ですが、近視眼的に機械学習の力に頼ってはいけないのです。
AIプロジェクトを失敗しないで進める方法

AIプロジェクトが確実に失敗してしまう原因をおさえたところで、どのようにAIプロジェクトを進めていけばよいのかについてもあわせて見ていきましょう!
先ほどの3つの原因はプロジェクトを立ち上げて推進する上で確実につぶしておくべきベーシックな部分です。
その上でどのようにAIプロジェクトを進めていけばよいのでしょうか?
CRISP-DMというフレームワークに沿ってプロジェクトを回そう
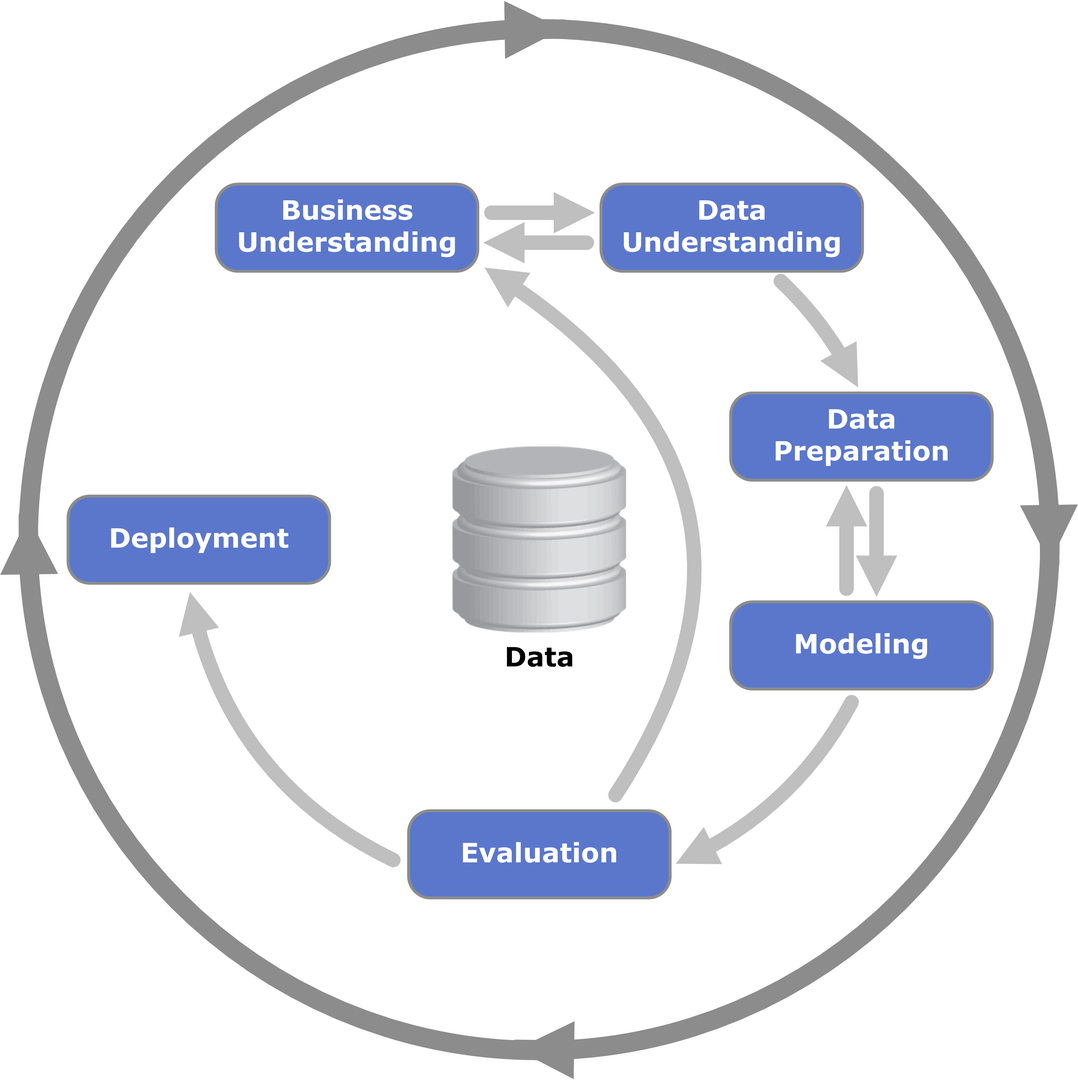
(出典:Wikipedia-‘Cross-industry standard process for data mining’)
CRISP-DMとは、「Cross-industry standard process for data mining」の略であり、データマイニング・データサイエンス・AI開発などにおいて業界横断で標準的に使えるデータ分析プロセスになります。
このCRISP-DMには全部で6つのプロセスがあります。
Business Understanding
Data Understanding
Data Preparation
Modeling
Evaluation
Deployment
例えば先程の顧客の解約率を予測してそれを防ぐ場合・・・
これをCRISP-DMに当てはめると、非常に簡略化していますが以下のようなイメージです。
・Business Understanding
売上が落ちているのは何が原因なのか→既存顧客の解約率が下がっている→既存顧客の流出を防ぐことが急務である→既存顧客の解約率を予測する
・Data Understanding
どのようなデータがあるか調査、どのようなデータが顧客解約予測に利きそうか基礎分析
・Data Preparation
データの結合、前処理、加工、特徴量生成
・Modeling
機械学習手法でモデル構築
・Evaluation
顧客解約予測における実解約と予測解約の再現率・適合率で評価
・Deployment
解約予測された顧客に対するアプローチ(クーポン付与、メールセグメント、DM、直接アプローチ)
ちなみにデータ分析のプロセスを簡単に分かりやすくまとめているのが以下の書籍になります。
拙著「俺たちひよっこデータサイエンティストが世界を変える」

この小説はCRISP-DMにおけるDeploymentまで出来ていないのですがデータ分析のプロセスがなんとなーく分かるかなと思います。
CRIP-DMについて詳しくは以下の記事でまとめていますのでチェックしてみてください!

精度向上にこだわり過ぎないようにしよう

CRISP-DMに沿ってプロジェクトを進めていくことになるわけですが、その上で精度向上にこだわり過ぎないようにしましょう!
先ほど決めたSMARTの目標における実装に耐えうる精度がアウトプットされているのであれば実装に移りましょう!
過度な精度追求は時間の無駄になりかねませんし、精度向上をもとめた挙げ句モデルが複雑になって保守が効かなくなってしまったり、毎回予測にものすごい時間をかけて実用的でないモデルが出来上がってしまうかもしれません。
Kaggleなどのデータ分析コンペでは精度を競うことになるので、どんな手段を使ってでも精度を上げることを目指しますが、実務では最後の数%の精度改善は必要でないことが多いです。
また、Kaggleでは複数の手法をアンサンブルして最終アウトプットを決めるというアプローチが取られることがありますが、それも実務ではなかなか取られないアプローチです。
実務ではどんなデータを取得して、それをどのように特徴量としてインプットするかが大事です(もちろんこの部分はKaggleでも大事です)。
特徴量エンジニアリングについては以下の記事で詳しくまとめていますのでチェックしてみてください!

AIプロジェクトの失敗原因と進め方 まとめ
本記事では、AIプロジェクトの失敗原因と進め方について見てきました!
改めてまとめておきましょう!
・SMARTに沿って目標を明確にしよう!AIを導入すること自体が目標になってしまいがちなので注意しよう!
・ステークホルダー間でしっかりプロジェクトのゴール・目標を共有しあってから推進しよう!
・目的・目標を達成しうるデータはあるか確認しよう!
当たり前な内容でもありますが、これらの当たり前が愚直にできているかどうかがプロジェクトの成否を左右します。
お互い、AI・機械学習プロジェクトを成功に導くために頑張りましょう!
弊社ではAI・機械学習・DXの文脈で案件のご相談をお受けしております。以下からお問い合わせください。
AIや機械学習、データサイエンスの勉強方法については以下の記事でまとめていますので、こちらもあわせてチェックしてみてください!



またDXやデータサイエンスに興味のある方は当メディア運営のサービス「スタアカ」で学べますので是非チェックしてみてください!
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!


















