RNN(リカレントニューラルネットワーク)の概要とPython実装方法をわかりやすく解説!


こんにちは!データサイエンティストのウマたん(@statistics1012)です!
自然なコミュニケーションができるようになることは、真の人工知能を実現するために非常に重要。
ディープラーニングの日進月歩の進化により、数年前と比較して飛躍的に言語処理能力が上がっています。

そんな自然言語処理の世界で現在使われている最先端技術の基となっているのがRNN(Recurrent neural network)。
この記事では、そんなRNNについて徹底的に見ていきます!
ディープラーニング系、その他のAI用語を一挙にまとめた以下の記事も合わせて要チェックです!

目次
RNNとは
まずはRNNについて簡単に見ていきましょう!
以下のYoutube動画でも詳しく解説していますよ!
RNNとはディープラーニングの一種で、Recurrent neural networkの頭文字を取った手法です。
日本語では回帰的ニューラルネットワークとか再帰的ニューラルネットワークとも呼ばれます。
まずは、RNNの概要、そして仕組みについて見ていきましょう!
RNNの概要
通常のディープラーニングでは、時系列要素のあるデータを上手く扱えないという欠点があります。
時系列要素はなくシンプルにいくつかの同列要素のインプットに対して重みパラメータを変化させて出力を調整します。
よくある図ですが、イメージはこんな感じ。
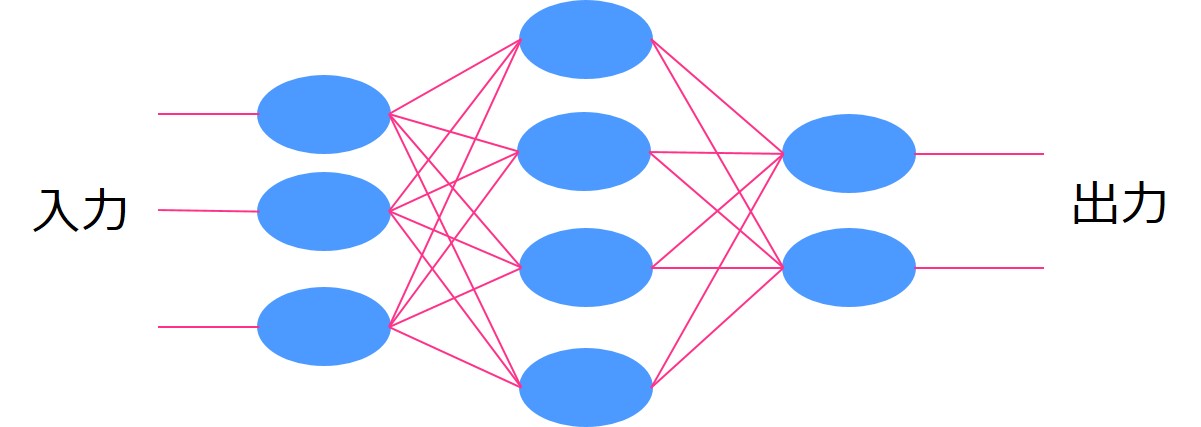
通常のディープラーニングの説明は割愛しますので、知りたい方は以下の記事を見てみてください!

そんなディープラーニングの構造に対して、時系列要素を加えて順番を考慮しようよというのがRNNの考え方。
時系列処理はテキストの文脈を読み取る上で非常に重要です。
例えば英語で、he said “I’m () ” という文章があった時、()の中身を当てるのは相当難しい。
ロボたんの戯言は置いておいて、正直可能性は無限大にあって分かりません。
しかし、その後ろにこんな文脈があったらどうでしょう?
Tom came home, and he said “I’m () “.
()の中にどのような文章が入るかほとんどの人が分かると思います。
おそらくTom came home, and he said “I’m home “でしょう。
このようにテキストの文脈からワードを推論するのは周りの文脈が非常に重要なんです。
それを実現できるのがRNNだと考えてください。
詳しく知りたい場合、「RNN」の論文を読んでみるとよいでしょう!
Time underlies many interesting human behavior. Thus, the question of how to represent time in connectoinist models is very important. In this approach, hidden unit patterns are fed back to themselves; the internal representations which deveolp thus reflect task demands in the context of prior internal states.
RNNの仕組み
RNNの概念が分かったところでRNNの仕組みについて見ていきましょう!
文脈を読み取るモデルが作りたい!しかし通常のディープラーニングでは難しそうです。
例えば、ディープラーニングによってワードの分散表現を獲得する手法であるword2vecと呼ばれる手法があります。
RNNよりもだいぶ後に提案された手法で分散表現(ベクトル化)に特化しています。
簡単にどんな手法か見ていきましょう!
word2vecでは前後関係からのみワードを推論します。
つまりTom () home, and he said “I’m home”とあった場合、Tomとhomeの間に入るワードがcameであるという教師データを与えて学習するというもの。
大量のセンテンスを学習させることでモデルの精度を上げていきます。
この時、ワードをベクトル変換するためword2vecと呼ばれています。
こんなイメージです↓↓
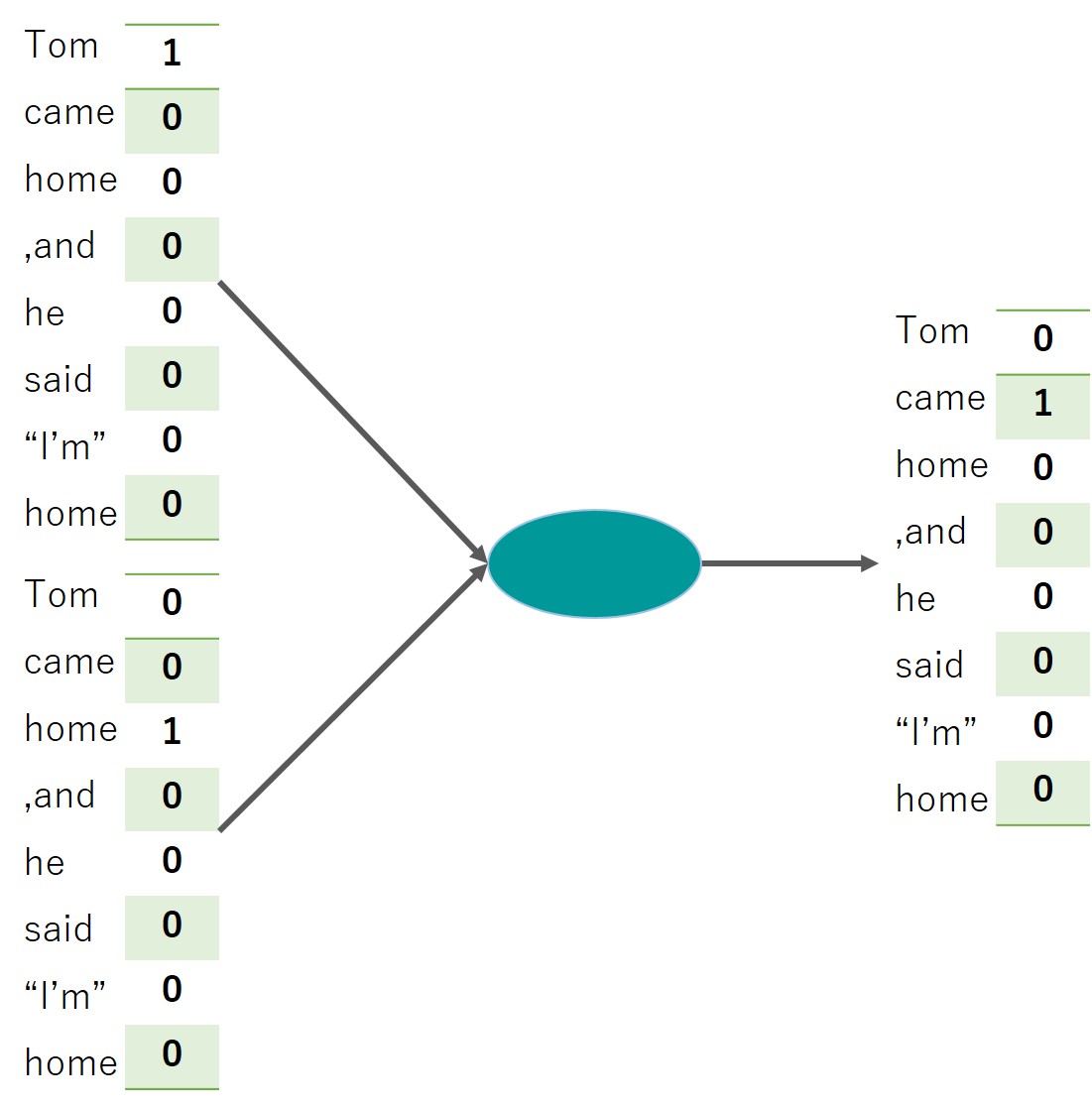
1つのワードから前後を予測するタイプもあり、それぞれCBOWモデルとskip-gramと呼ばれます。
さてさて、しかしこのword2vecでは単語をベクトル化することに特化しているため文意全体を読み解くのは非常に難しいです。
そこで登場するのがRNNの考え方。
今までのディープラーニングでは、それぞれのインプットがそれぞれの中間層に与えられていましたが、RNNでは同一の中間層を用いて再帰的にインプットが行われます。
再帰的という部分がReccurentと言われるゆえんです。
こんなイメージ
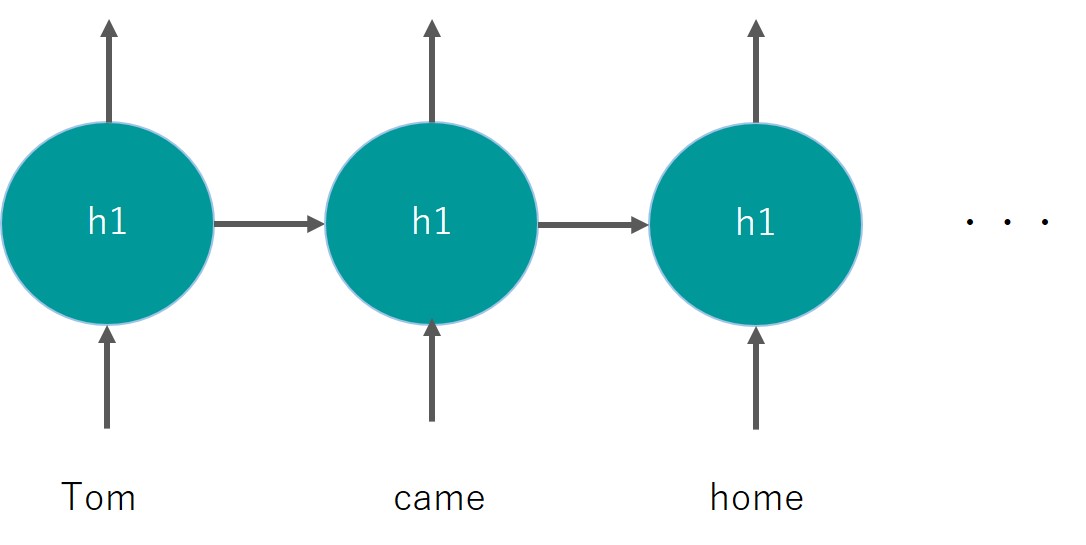
同じレイヤーh1を用いているのがミソです。
これにより前のワードの情報をレイヤに記憶させ後続へとつなぐことができます。
RNNの改善手法と応用場面

RNNは同じレイヤに情報を再帰させることで時系列要素をレイヤに記憶させることに成功していました。
しかしRNNも万能ではありません。
ここでは、RNNの欠点と改善手法・応用ケースについて見ていきましょう!
RNNの欠点と改善手法

そんなRNNですが、実はいくつかの欠点があるんです。
それは時系列要素を繋いでいくことで勾配が爆発もしくは消失してしまうこと。
ディープラーニングでは重みパラメータを勾配法で計算するため勾配の値が非常に重要です。
通常のディープラーニングでも初期値を正しく与えないと勾配消失や勾配爆発が起きますが、RNNでも起きやすい。
そこを改善しなくてはいけません。
勾配爆発に関しては、勾配クリッピングという方法が一般的です。
勾配クリッピングでは、勾配がある閾値を超えた場合勾配をルールに従って修正する方法。
そして勾配消失に関しては、LSTMと呼ばれる手法が一般的に用いられます。
LSTMはLong short term memoryの略で、長い記憶も短い記憶も継続させます。
シンプルに言うとLSTMでは通常の勾配とは別に記憶用の記憶セルを作り伝播させていきます。
以下の記事で詳しく解説しています!


また、詳しくは以下の書籍を参考にしてみてください。

ここでおさえておきたいのは、RNNを改善した最新の手法はあるが基本的な考え方は同じということ。
そして便利なことにPythonを使えば、最新の手法でもフレームワークで実装できるということ。
RNNの応用場面
さて、そんなRNNは現実世界のどのような場面に応用されているのでしょうか?
どのようなことができるのでしょうか?
Google翻訳
RNNの考え方の延長線上に時系列データを別の時系列データに変換する「seq2seq」があります。
それにより、Google翻訳のような日本語の文意を読み取り英語に変換するというアプリケーションが開発されています。
自動応答
流行りのチャットボットや音声AIなども同じくseq2seqをベースにしています。
ある質問に対して自然な回答をすることは完璧なAIを作り出す上で日々研究されている分野です。
画像→テキスト変換
現在の技術では、非常に高い精度で画像データをテキストデータに変換することができます。
 (引用元:Google-“Show and Tell: A Neural Image Caption Generator“)
(引用元:Google-“Show and Tell: A Neural Image Caption Generator“)
これを見るとかなりの高精度で画像データを読み取りテキスト変換することが出来ていることが分かります。
RNNを実際にPythonで実装してみよう

さて、RNNの概況について理解できたところで実際にPythonを使って実装していきましょう!!
使うデータセットはKaggleのホームページが落とせる航空会社の乗客数データ!
1949年から1960年までの月別乗客数がデータとして入っています。
149行2列のシンプルなデータセット。
モデル構築は以下のサイトを参考にしています。
1変数の時系列データを基に過去のデータから未来の値を予測します。
この時、tflearnというライブラリを使ってRNN(正確にはLSTM)を実装していきます。tflearnはkerasと似たようなライブラリでディープラーニングの実装が感覚的に容易にできます。
実際にモデルを構築していきましょう!
最終的な評価はRMSE(Root Mean Square Error)で算出しています。
細かい実装ポイントについて見ていきましょう!
def create_dataset(dataset, steps_of_history, steps_in_future):
X, Y = [], []
for i in range(0, len(dataset)-steps_of_history, steps_in_future):
X.append(dataset[i:i+steps_of_history])
Y.append(dataset[i + steps_of_history])
X = np.reshape(np.array(X), [-1, steps_of_history, 1])
Y = np.reshape(np.array(Y), [-1, 1])
return X, Y
def split_data(x, y, test_size=0.1):
pos = round(len(x) * (1 - test_size))
trainX, trainY = x[:pos], y[:pos]
testX, testY = x[pos:], y[pos:]
return trainX, trainY, testX, testYここでは、データセットを時系列モデルに適した形に変形する関数と、学習データ予測データに分ける関数を作っています。
net = tflearn.input_data(shape=[None, steps_of_history, 1])
net = tflearn.lstm(net, n_units=6)
net = tflearn.fully_connected(net, 1, activation='linear')
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='mean_square')
model = tflearn.DNN(net, tensorboard_verbose=0)
model.fit(trainX, trainY, validation_set=0.1, batch_size=1, n_epoch=150)ここが実際にRNN(LSTM)モデルを構築している部分。
ちなみに初回モデル構築は問題ないですが、再度パラメータを変えて処理を回そうとするとJupyter notebookではエラーをはいてしまうので、7行目に初期化するような記述を入れています。
tensorflow.reset_default_graph() #モデルを初期化これだけでRNNが実装できちゃうんです!簡単!
この時、RMSEは0.10079201となりました。それなりに良い予測ができてる!
ちなみに層を増やしてみると・・・
net = tflearn.input_data(shape=[None, steps_of_history, 1])
net = tflearn.lstm(net, n_units=6, activation='relu',return_seq=True )
net = tflearn.lstm(net, n_units=6, activation='relu')
net = tflearn.fully_connected(net, 1, activation='linear')
net = tflearn.regression(net, optimizer='adam', learning_rate=0.001,
loss='mean_square')RMSEは0.16051404に悪化してしまいました・・・
簡易的なデータセットに複雑なモデルで当ててもあまり意味がなさそう。
ちなみに過学習を防ぐためにDropoutなどのパラメータで調節することも可能です!
RNNについて勉強する方法

さて、ここまでRNNについて徹底的に見てきました。
正直、書籍ベースで非常に深い部分まで突っ込んで学ぶことが可能です。
先ほども紹介しましたが、RNNまわりを勉強するなら以下の書籍が圧倒的にオススメです!
有名どころですが、もしディープラーニングの基本から勉強したいのであれば以下の書籍を読むとよいでしょう!
こちらは画像認識の話がメインです。

(2026/07/10 12:07:03時点 Amazon調べ-詳細)
ただ、書籍だけでメンターサポートがないとなかなか進めるのが難しいと思うのでその場合はプログラミングスクールを活用するとよいでしょう!
僕の場合はテックアカデミーで書籍も使いながらメンターサポートいただいて学習を進めました!
テックアカデミー本体のカリキュラムは微妙なので期待しない方がいいですが、メンターサポートは充実しているので自分でメンターの人に要望を出しながらガツガツ進められる人にはオススメ!
以下で僕の体験談を記事にしています。
他のプログラミングスクールもあわせてオススメを以下の記事で紹介しています!

RNN まとめ
RNNはこれからも進化を続ける分野であり、まさに音声AIの領域は世界のIT企業GAFAが凌ぎを削っている部分。
人間と同等レベルの思考・会話が出来る日も遠くはないでしょう。
それが実現した未来はどんな世界になるのでしょうか。
当サイトでもシンギュラリティ(AIが人間を超えるタイミング)について言及している記事がありますのでよければ目を通してみてください!

ディープラーニングを使って、世界を変えていきましょう!
ディープラーニング、機械学習、データサイエンス、Pythonの勉強法については以下の記事でまとめていますのであわせてチェックしてみてください!




 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!