【初心者向け】データ分析の手法を分かりやすく解説!Pythonで実装してみよう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です!
元々大学院で数理統計学を専攻しており、現在も領域は広いですが根底にあるのはデータを使ってどのようにビジネスに価値を生み出すかということを生業として仕事をしています。
この記事では、
・データ分析をする上での考え方
・データ分析における手法
・データ分析におけるPython実装
・データ分析の勉強方法
について解説していきたいと思います。
目次
初心者に知って欲しいデータ分析の考え方

データ分析の手法を見る前に、まずデータ分析の考え方について3つまとめておきます。
もちろんここに取り上げていることだけではありませんが、ぜひおさえておいて欲しいことを解説していきますよ!
データ分析は分けて比べること

まず確認しておきたいのがデータ分析とは何か。
釈迦に説法かもしれませんが、あえてツッコミたいと思います。

確かに、データ分析とはその名の通り「データを分析すること」
それでは分析とは何か。
意外と分析とは何かと言われると難しいんですよね。
分析とは「分けて比べること」。そしてその結果何かしらの示唆を導き出すこと。
すなわちExcelでクロス集計を行ったとしてもそれはデータ分析なのです。

データ分析というと、崇高な手法を使ってゴリゴリ機械学習使うなどといったイメージをお持ちの方も多いかもしれませんが、基本的にはデータを分けて比べてそれで示唆出しが出来れば、データ分析と言えるのです。
大量のログデータをSQLで集計・加工しても、それだけではデータ分析とは言えません。
データ集計とデータ分析は明確に切り分けないといけません。
手法にこだわりすぎではいけない

個人的には新しい手法やアルゴリズムには興味があり手法にこだわってしまう部分があるのですが、正直手法はそれほど大事でない場合が多いです。
手法なんかよりも、まずはどのようなデータを収集し加工し特徴量を作るかが一番大事です。
特徴量を作り出す大事なプロセスである特徴量エンジニアリングについては以下の記事でまとめていますのでぜひチェックしてみてください!

まあ、でもある程度手法の知識がないと解釈の仕方を間違ってしまうので全く手法にこだわらなくて良いというわけではありませんよ!
あくまでこだわりすぎないということが大事です。
仮説を立て目的を明確にすることが大事である

大学時代に企業でインターンシップを行っていた時、大量のデータを渡されてここから何か面白いコト見えてこないかなーというお題をいただいたことがあります。
正直、当時は自分が未熟だったこともあるのですが、業界の知識もなかった僕は仮説を立てることもなく普段使い慣れている手法をとりあえず試して・・・しかし結局は当たり前の結果しか得られなくって・・・みたいな経験をしたことがあります。
やはりデータ分析の時間・労力をムダにしないためにも、分析前に仮説を立てて分析の目的を明確化させるべきです。
仮説はデータ集計の段階での違和感から得られることが多いです。
例えばなんですけど、
データ集計結果から自社サイトへの自然検索からの流入が減っているという現象があるとします。
そうするとSEOが弱まって検索順位が落ちているのではないかという仮説が成り立ちますよね?
しかしSEO順位は変わっていない。そうすると次はSEMを強めたせいで自然検索流入が広告流入に流れてしまっているのでは?という仮説が立ちます。
期間を分けて比べてみる(分析)と実際にSEOの量とSEMの量には負の相関関係があり、ちょうど自然検索流入が落ちた時期にSEMを強めていることが分かりました。
ここまではただのExcelレベルですよね。
ここから最適なコストで最適な効果を得ることのできるSEMの出稿量というのを自動で算出するモデルを作りたいとなるでしょう。
そこでやっと機械学習の出番が出てくるわけですね。
なんでもかんでも手法を適用させて分析しようとするのではなく、簡単な集計から仮説を立てて目的を明確にしてから高度なデータ分析を行うようにしましょう!
データ分析のプロセスに関しては有名なCRISP-DMというフレームワークがあるので是非一度チェックしておいてください!

データ分析の手法

手法にこだわりすぎないことはもちろん大事なのですが、手法について知っておくことはデータ分析において重要です。
データ分析における手法には大きく分けて教師あり学習と教師なし学習があります。
強化学習という手法もありますが、基本的に教師あり学習と教師なし学習さえ知っておけば問題ないです。
教師あり学習

教師データとは正解ラベルが付いたデータ。
正解データに対してモデルを構築し、未知データの予測に活かしたりします。
線形回帰分析

教師あり学習の定番は、線形回帰分析。
回帰分析では、ある目的変数と説明変数の関係を見ていくことになります。
元々正解の分かっているデータから回帰モデルを作って、それを新たなデータに当てはめます。
アイスクリームの需要予測などが良い例。アイスクリームの売れた個数(これがいわゆる教師ラベル)をその日の温度や湿度などから予測するモデルを作ります。
正解が分かっている教師データが与えられているので教師あり学習になります。
まずは、線形回帰分析から入門していくのがよいでしょう!
線形回帰分析についてはこちらの記事にまとめていますので良ければご覧ください!

判別分析
回帰分析が、量的変数を目的変数として扱うのに対して判別分析は質的変数を目的変数として扱います。
統計学における多変量解析手法では一般的に回帰分析・判別分析を分けておりますが、機械学習手法は、回帰も判別も目的に応じて使い分けることが可能です。
決定木
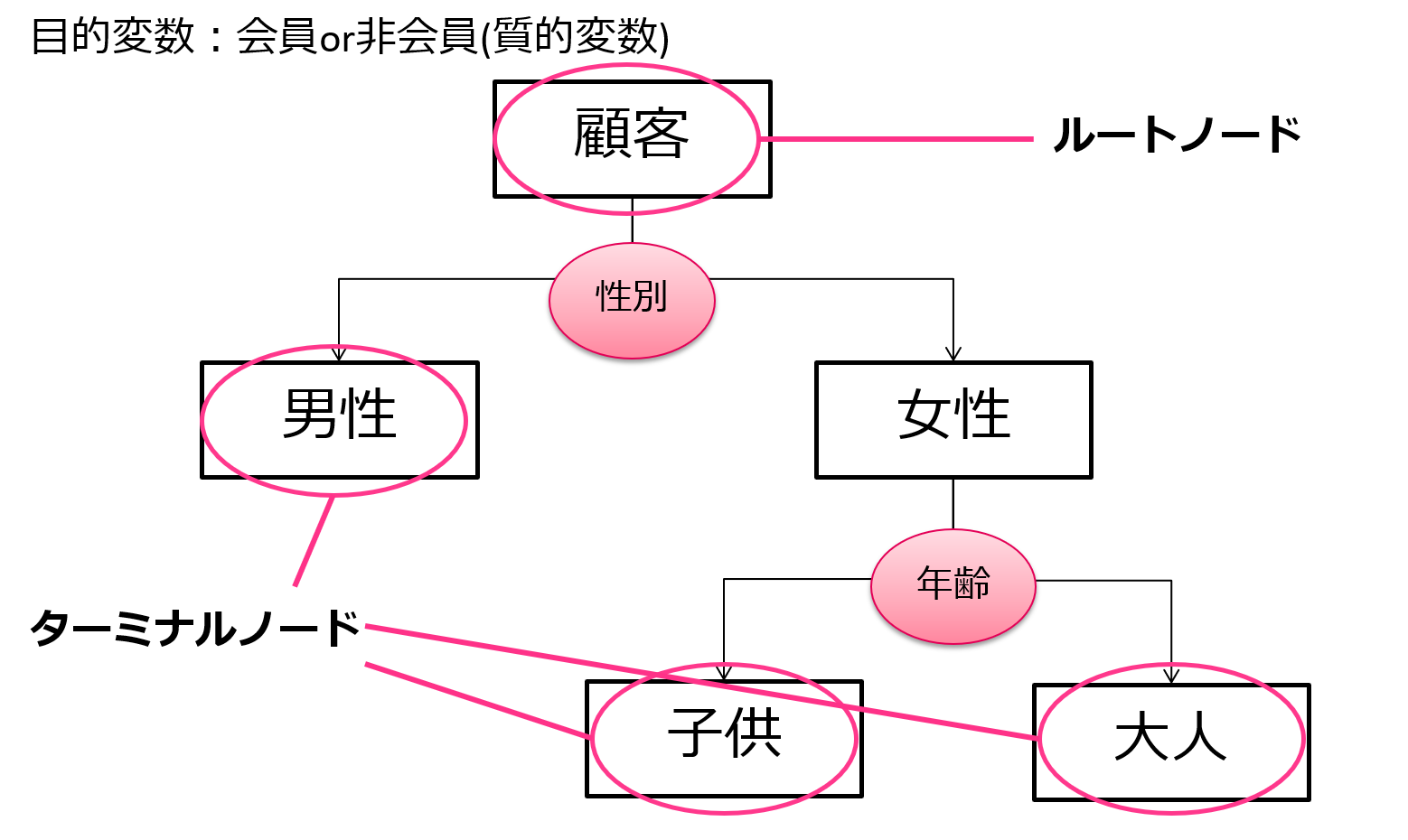
決定木はタイタニック乗船データに対しても例として用いられている一般的な手法です。
非常に分かりやすくルールも可視化しやすいためビジネスの場面で用いられることが多いです。
そういう意味でいうと、データの解釈のために使われることが多く、単純な予測精度を出したいなら他の手法を用いたほうが無難です。
決定木に関しては以下の記事にまとめています!

k近傍法
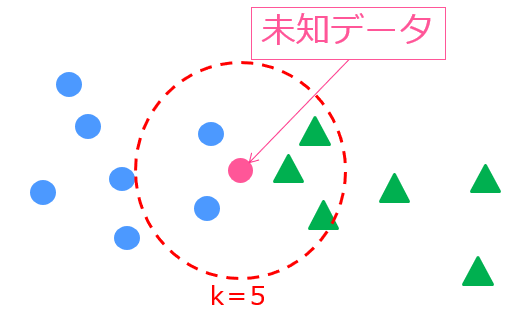
k近傍法は、未知データの周りに存在する学習データの数から未知データのラベルを判断する機械学習モデルです。
アルゴリズムはシンプルですが、ある程度精度の見込める手法です。
詳しくは以下の記事にまとめています!

ランダムフォレスト
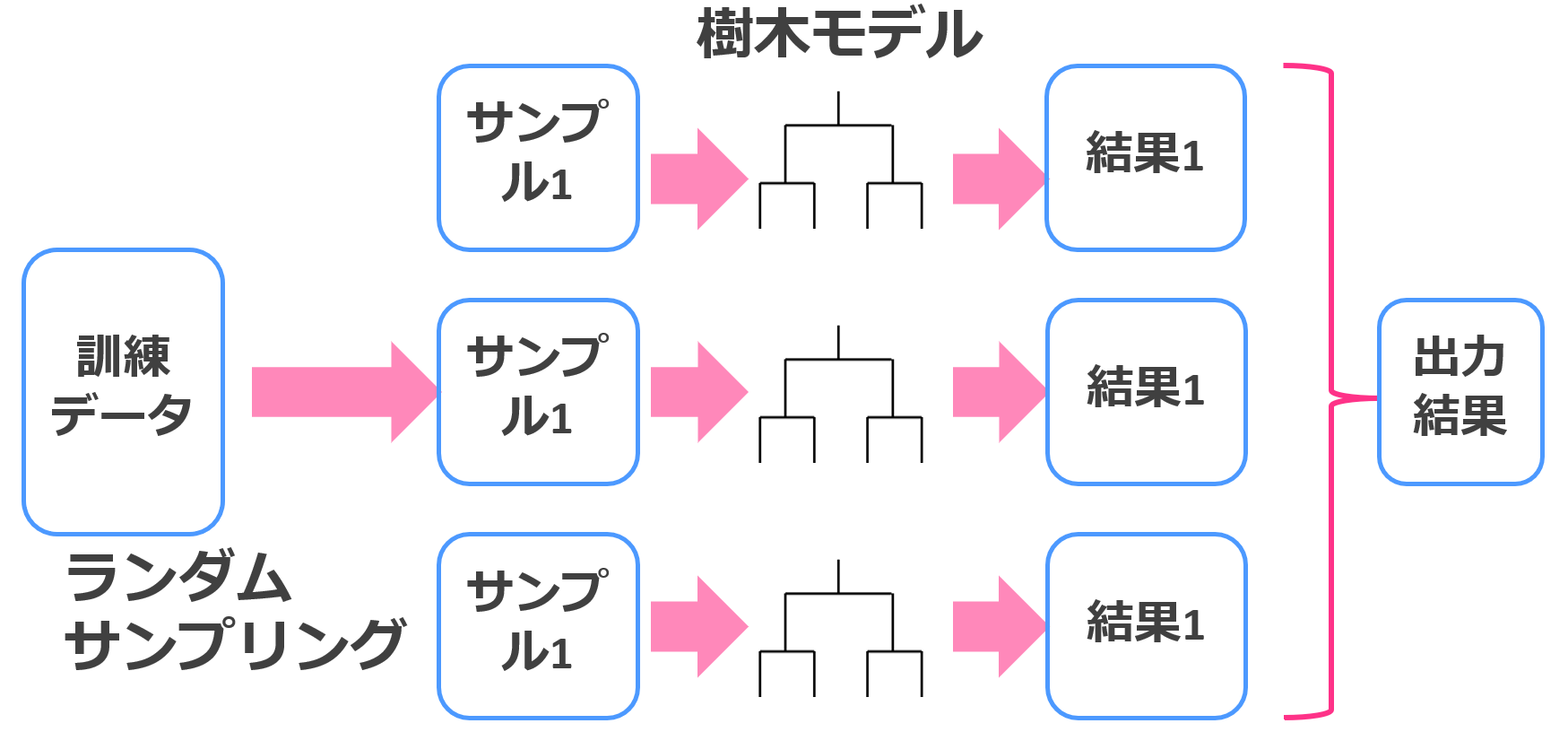
ランダムフォレストは、決定木とバギングを組み合わせた手法でそれなりの精度を簡単にたたき出してくれます。
それほど計算負荷もかからないので、ちょっとしたデータを解析するのにはもってこいです。
ランダムフォレストに関してはこちらの記事を参考にしてみてください。

SVM(サポートベクターマシン)
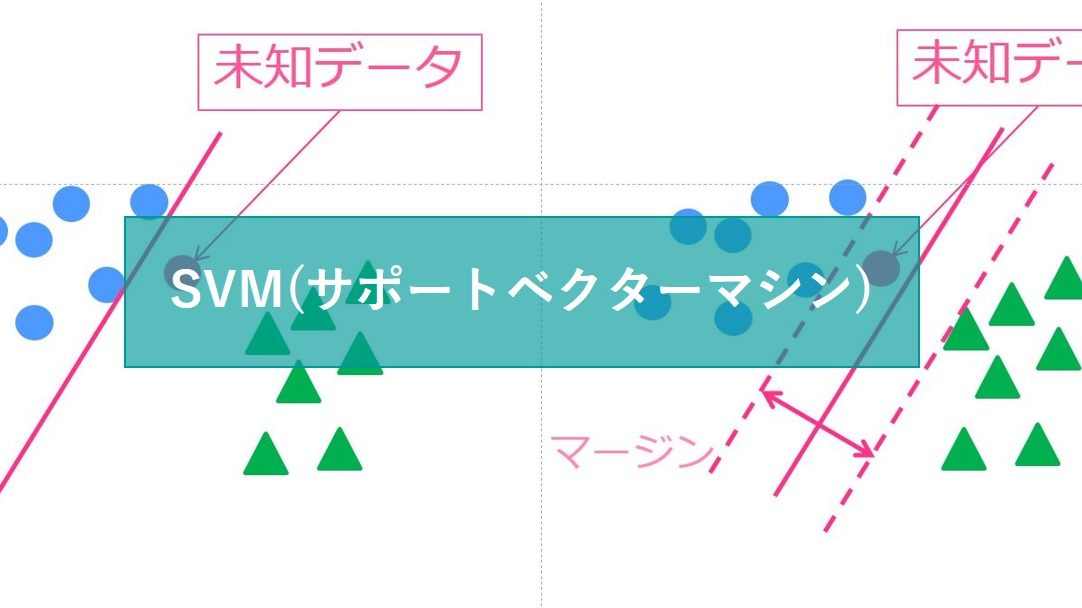
SVMもランダムフォレスト同様の精度が期待できる優秀な手法です。
応用の幅が広く様々な分野で使われています。計算負荷は高めです。
SVMについて詳しくはこちら!

ニューラルネットワーク
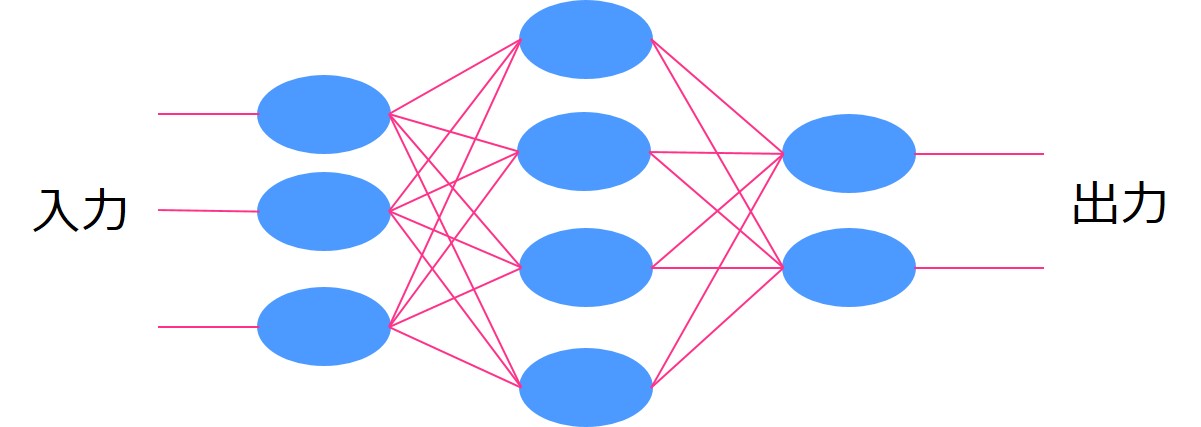
ニューラルネットワークはディープラーニングの基となった手法です。
ニューラルネットワーク単体ではそれほど高い精度は見込めませんが、中間層を増やせば増やすほど学習が進み(ディープラーニングに近づき)精度が高くなります。その分、計算負荷も上昇します。
ニューラルネットワークに関して詳しくはこちら!

XGboost
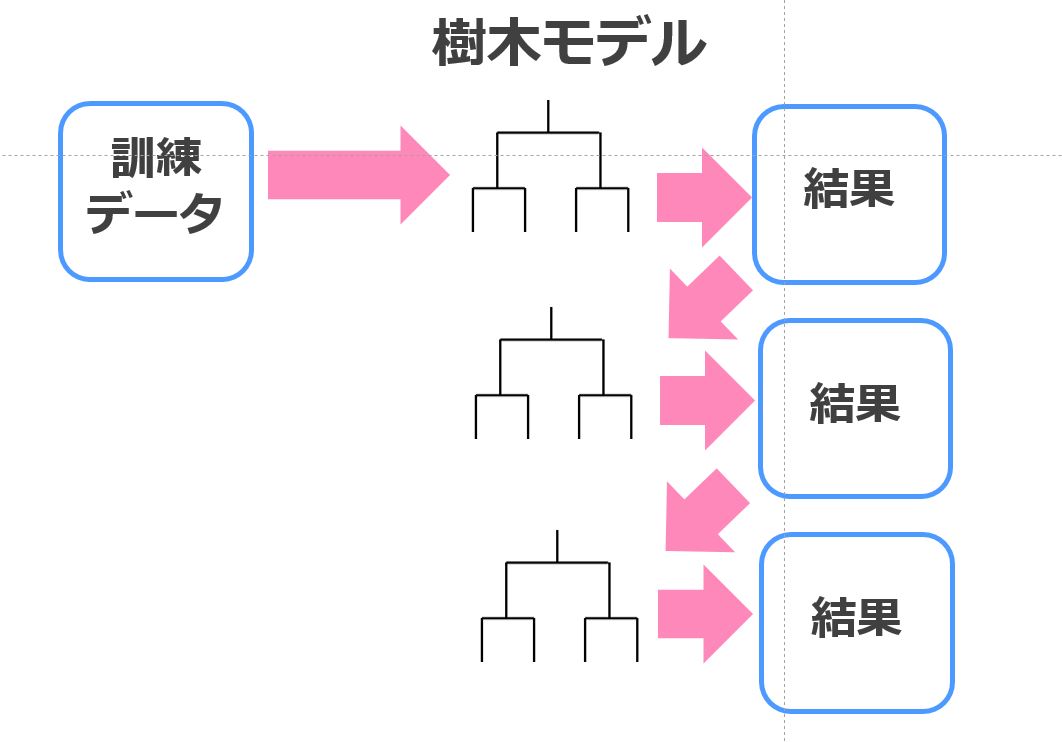
XGboostは、決定木と勾配ブースティングを組み合わせた手法で相当高い精度が見込めます。
今回紹介した教師あり学習の中では最も高い精度が見込める優秀な手法になっております。
XGboostに関しては以下の記事をご覧ください!

時系列データ分析手法(ARIMAなど)
時系列データに対して、通常の回帰系の手法を適用するのは要注意!
見せかけの回帰という問題が時系列データには生じるため、一見寄与率が高いモデルでも全く無意味なモデルであることが多いです。
とはいえ、時系列要素を変数として取り入れて機械学習手法まわすと結構良い精度出すのでどちらを使うかは状況次第といったところでしょうか。
時系列データ分析については以下の記事で簡単にまとめています!

教師なし学習

教師なし学習は、教師あり学習の前手に次元圧縮を行ったり、データの構造を把握するために使ったりする手法です。
正解ラベルの付いた正解データがないのが特徴です。
クラスター分析
クラスター分析は教師なし学習の中でもっとも有名ですね!
クラスター分析では、正解となるラベルが与えられていません。膨大なデータの中からあるパターンを見つけ出す手法になります。
例えば、顧客の行動データなどをクラスター分析にかけることによって、そのままでは見えてこない顧客セグメントが浮かび上がってくることがあります。
クラスター分析には階層的クラスター分析と非階層的クラスター分析があります。非階層的クラスター分析ではあらかじめクラスター数を決めなくてはいけませんが膨大なデータでも比較的計算が早いです。
クラスター分析に関してはこちらの記事にまとめていますので良ければご覧ください!

クラスター分析の中でも特に実務に用いられることの多いk-means法について詳しくは以下の記事でまとめています!
主成分分析
主成分分析は次元削減のために用いられることが多い手法です。
イメージ的にはクラスター分析に近いのですが、クラスター分析がサンプルをカテゴライズしていたのに対して、主成分分析では、数ある変数をカテゴライズします。
例えば、各教科の点数があった時(数学・化学・物理・世界史・日本史・英語などなど)それらに主成分分析をかけることによって、変数をいくつかにまとめあげることができます。
この場合、理系・文系というように分けられることが想像できます。
主成分分析により次元圧縮をしてからクラスター分析をすることなども方法として考えられます。

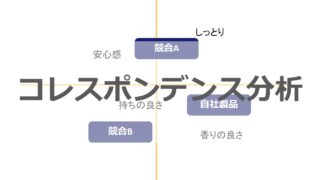
コレスポンデンス分析
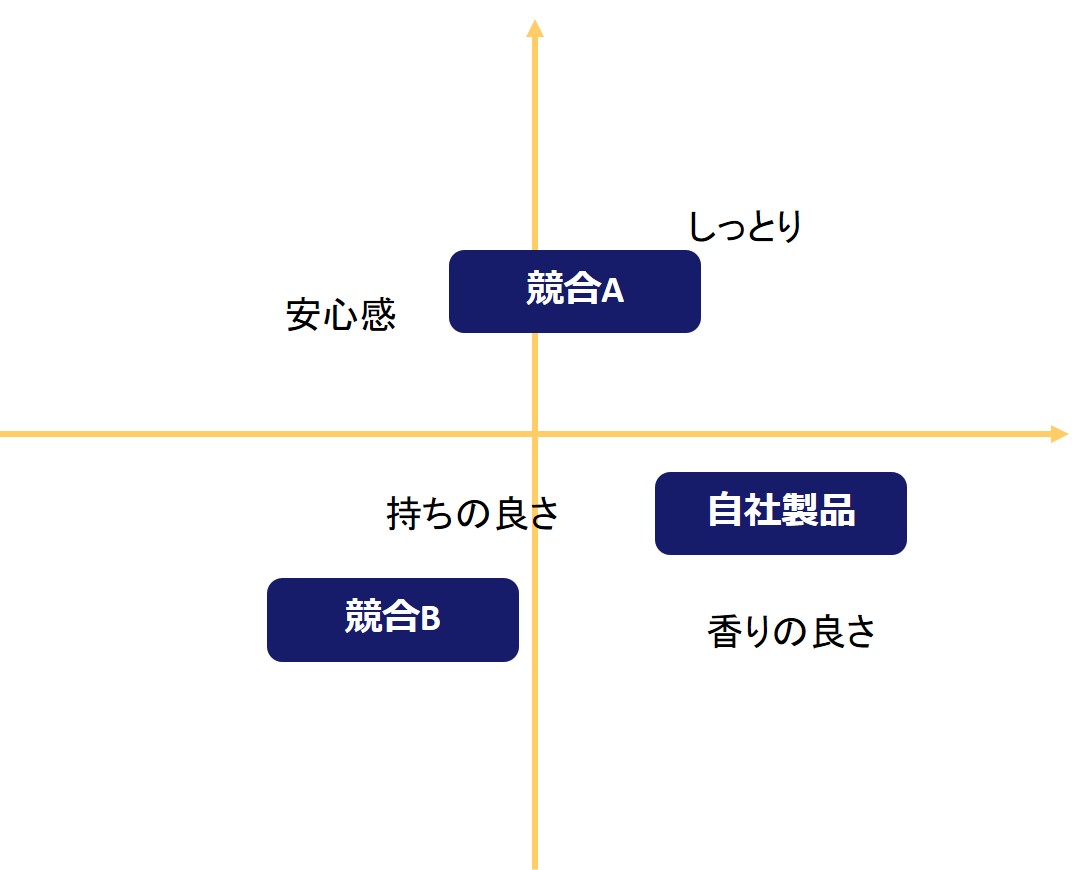
コレスポンデンス分析は、商品・サービスの特徴を可視化するのに優れた分析手法であり、マーケティングにおける調査に良く使われます。
多変量解析における数量化3類と考え方はほぼ同じです。
様々な商品に対するイメージを分析によってマッピングします。
詳しくは以下の記事でまとめています!
コンジョイント分析

商品やサービスのどの部分を改善すれば消費者に受け入れやすくなるのか(効用値の大小)を把握するための手法であるコンジョイント分析。
どこまでのスペックが欲しいのか・価格はどこまで許容できるのかに対して消費者は明確に意識しているわけではなく、なんとなく潜在的に感覚を持っています。
そんな消費者の潜在的な効用を把握するために、直接的に機能の良し悪しを聞くのではなく様々なスペックの商品に点数を付けてもらうことにより機能の効用値を算出するのがコンジョイント分析になります。
コンジョイント分析に関して詳しくは以下の記事でまとめています!

データ分析をPythonで実装してみよう

データ分析の考え方と手法について見てきました!
ここで、データ分析の定番プログラミング言語であるPythonを使って簡単なデータ分析をおこなっていきましょう!
先ほど登場した手法の中で高い精度が見込めるXGBoostについて実装していきますよー。
Mnistという文字の識別分類データを分類してみましょう!
Mnistのデータセットの特徴は以下です。
・0~9の手書き数字がまとめられたデータセット
・6万枚の訓練データ用(画像とラベル)
・1万枚のテストデータ用(画像とラベル)
・白「0」~黒「255」の256段階
・幅28×高さ28フィールド
それでは、コードをみていきましょう!
まずは、Mnistのデータをインポートして分類するために加工していきます!
続いて、Xgboost用のデータ構造に変換します。
最後にパラメータをセットしてXgboostで学習を行っていきます!
こんなにカンタンに実装できるんですよー!
結果は・・・
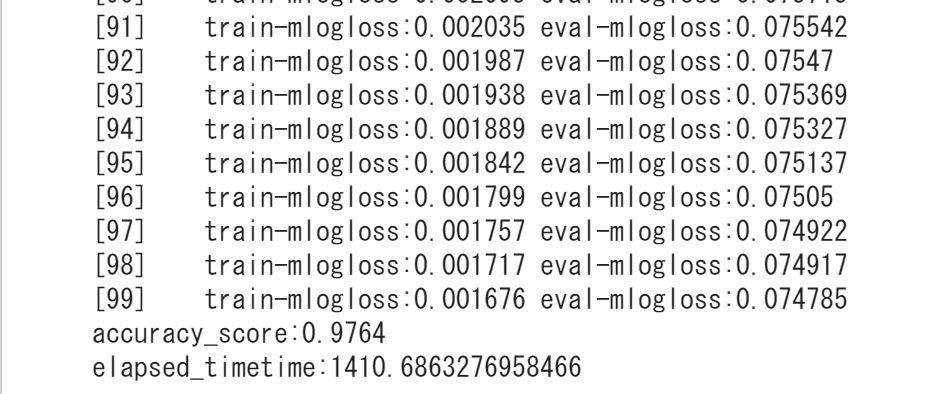
精度・・0.976!!非常に高い!
学習データをインプットして、XGBoostでモデルを構築してテストデータを分類してみると97.6%が正しい数字に分類されたということですねー!
手法にこだわりすぎない方がよい一方で機械学習手法の威力を実感いただけると幸いです。
Pythonの勉強法については以下の記事でまとめています!

データ分析の勉強法

データ分析について色々と見てきましたが、最後にデータ分析の勉強法について簡単にまとめておきましょう!
繰り返しになりますが、データ分析のインパクトを最大化するためには手法だけ知っていてもダメです。
データ分析前の仮説設定やデータ分析を結果を活かす打ち手の理解なども大事。
そんな視点から総合的にデータ分析の能力を底上げするために必要な勉強方法についてまとめていきます。
ビジネス課題の特定や打ち手の理解をする
まずは、ビジネスやマーケティングの全体感を理解して仮説の精度を上げること。
実践が一番大事ですが、座学でも学べることはたくさんあります。
手前味噌ですが、僕自身がデータ分析でビジネスを解決していくストーリーを書いているので是非そちらをチェックしてみてください。

勾配ブースティング木のXGBoostを使ったビジネスシーンでの実装についてストーリー形式で簡単にまとめていますのでイメージをふくらませてもらうのにちょうど良いかと思います!
またデータ分析後の打ち手として非常に重要なWebマーケティングについては以下の書籍で分かりやすく解説していますのでこちらも是非見てみてくださいー!

どちらの書籍も価格は300円ちょっとですし、Kindle unlimitedであれば無料で読めるのでぜひチェックしてみてくださいね!
またUdemyというサービスでマーケティングを網羅的に学びSEOのツールを作っていくマーケティング×データ×開発が学べる講座を用意しておりますので興味のある方はぜひチェックしてみてください!
【入門から実践まで】Webマーケティングの全体像とデータ活用を短時間で学び実際にSEO集客ツールを作ってみよう!
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「B3PS3TPL8ZWG」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 2.5時間 |
| 【レベル】 | 初級 |
Twitterアカウント(@statistics1012)にメンションいただければ2000円以下になる講師クーポンを発行できますよー!
以下の記事でWebマーケティングの勉強法について詳しくまとめています。

データ分析の実装と理論の理解
データ分析の手法について簡単に紹介した後、Pythonで実際にデータ分析を行いましたが、データ分析を行う際は理論・手法の理解をしつつ実際に実装できるエンジニアリング力も必要です。
こちらも手前味噌ですが、僕自身が公開している以下のコースが非常にオススメです!
| 【オススメ度】 | |
|---|---|
| 【講師】 | 僕自身!今なら購入時に「B3PS3TPL8ZWG」という講師クーポンコードを入れると90%オフ以上の割引価格になりますのでぜひご受講ください! |
| 【時間】 | 4時間 |
| 【レベル】 | 初級~中級 |
僕自身がUdemyの色んなコースを受けてみた中で、他のコースにはないこんなコースあったらいいなみたいなコースを作ってみました。
このコースは、なかなか勉強する時間がないという方に向けてコンパクトに分かりやすく必要最低限の時間で重要なエッセンスを学び取れるように作成しています。
アニメーションを使った概要編とハンズオン形式で進む実践編に分かれており、概要編ではYoutubeの内容をより体系的にデータ分析・機械学習導入の文脈でまとめています。
データサイエンスの基礎について基本のキから学びつつ、なるべく堅苦しい説明は抜きにしてイメージを掴んでいきます。
統計学・機械学習の基本的な内容を学び各手法の詳細についてもなるべく概念的に分かりやすく理解できるように学んでいきます。
そしてデータ分析の流れについては実務に即したCRISP-DMというフレームワークに沿って体系的に学んでいきます!
データ分析というと機械学習でモデル構築する部分にスポットがあたりがちですが、それ以外の工程についてもしっかりおさえておきましょう!
続いて実践編ではデータコンペの中古マンションのデータを題材にして、実際に手を動かしながら機械学習手法を実装していきます。
ここでは、探索的にデータを見ていきながらデータを加工し、その上でLight gbm という機械学習手法を使ってモデル構築までおこなっていきます。
是非興味のある方は受講してみてください!
Twitterアカウント(@statistics1012)にメンションいただければ2000円以下になる講師クーポンを発行いたします
ただUdemyに関しては独学になってしまいます。
もし独学での勉強が不安な方はデータ分析のコースがあるプログラミングスクールもオススメです。
実際に受講したことのあるプログラミングスクールは以下です。
公式サイト:https://techacademy.jp/
テックアカデミーは、オンライン学習ですが現役エンジニアのパーソナルメンターがつくので分からないところも解消しやすくUdemyなどで進めるよりは圧倒的に進みが早いです。
データ分析だと以下の2つのコースがおすすめ。
テックアカデミーについては以下の記事で体験談をまとめていますので是非チェックしてみてください!
無料体験は事前に出来るので不安な方は試してみることをオススメします!
一方でデータ分析をソリューションにしたAI開発まで踏み込んだ勉強を行いたいなら以下のAidemyもオススメです!
公式サイト:https://premium.aidemy.net
Aidemyとは、AIのソリューションを法人向けに提供していたりAIのプログラミングスクールを提供していたりする会社です。
テックアカデミーはプログラミング全般を網羅していますが、AidemyはAI・Pythonまわりのみに特化したスクールです。
自分に合った完璧オーダーメイドのカリキュラムを作ってくれます。
内容はテックアカデミーよりも濃く深いですが、価格はその分割高です。
無料相談が出来るのと本コース申し込んでも2週間は返金無料です!
実際に受講してみた体験談を以下にまとめています!
ただテックアカデミーもAidemyも高額すぎる・・・
ということで価格がリーズナブルな業界最安級のデータサイエンス特化スクールを自らの経験を活かして作成いたしました。
 公式サイト:https://toukei-lab.com/achademy/
公式サイト:https://toukei-lab.com/achademy/
| 【価格】 | 98,000円 |
|---|---|
| 【オススメ度】 | |
| 【サポート体制】 | |
| 【データサイエンティスト範囲】 | Python、機械学習、統計学、ディープラーニングからDXの考え方・機械学習のビジネス導入・SQLまで必要な要素を全て網羅 |
データサイエンティストに必要なエッセンスを詰め込んでいるので、ぜひチェックしてみてください!
データサイエンスやAI系のスクールに関しては以下の記事でまとめていますのでこちらもあわせてチェックしてみてください!

まとめ
ここまでご覧いただきありがとうございました。
データ分析に関するお話をツラツラとしてきましたが、あくまで手法やプログラミング言語は手段であるということを念頭において、データ分析の目的を明確化することが大事だと思います。
とは言え、目的ばかり考えて頭でっかちになって全く動かないというのもよくないので、とりあえず手を動かしてみるというのも大事なんですよね。
手段の目的化は避けなくてはいけないなと思いつつ、それでもとにかくDoして手段を高速化させていくフローも大事ですよね!
というわけで、データ分析に関するボリュームたっぷりのお話でした!
以下の記事で統計学・機械学習・ディープラーニングの勉強法、そしてデータサイエンティストへのロードマップをまとめていますので、重複している部分も多いですがぜひ見てみてください!




イラスト出典:Illustration by Stories by Freepik
 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!