
ディープラーニングでできることとできないこと!Pythonでの実装例とともに見ていこう!


こんにちは!
データサイエンティストのウマたん(@statistics1012)です。
最近はどっぷりディープラーニングに浸かっています。
ディープラーニングと聞くとどんなイメージを持ちますか?
なんでもできる魔法のような技術?
いえいえそんなことはありません。
ディープラーニングは何でもできるように世間でもてはやされていますが、もちろん出来ることと出来ないことがあります。

少しでもディープラーニングについて多くの人に理解して欲しい!
ということで、この記事ではディープラーニングができることとできないことについてまとめていきます!
ところどころで実装例も一緒に紹介していきますよー!
目次
ディープラーニングとは
まずは、ディープラーニングとは一体何なのか、大枠からとらえていきましょう!
ディープラーニングの原型となる「ニューラルネットワーク」の理論は実は1940年~1950年の間に既に確立されているんです。
人間の神経が信号を伝播させていくように、ある入力を次の層へと重み付けをして伝播させていき出力を求めます。 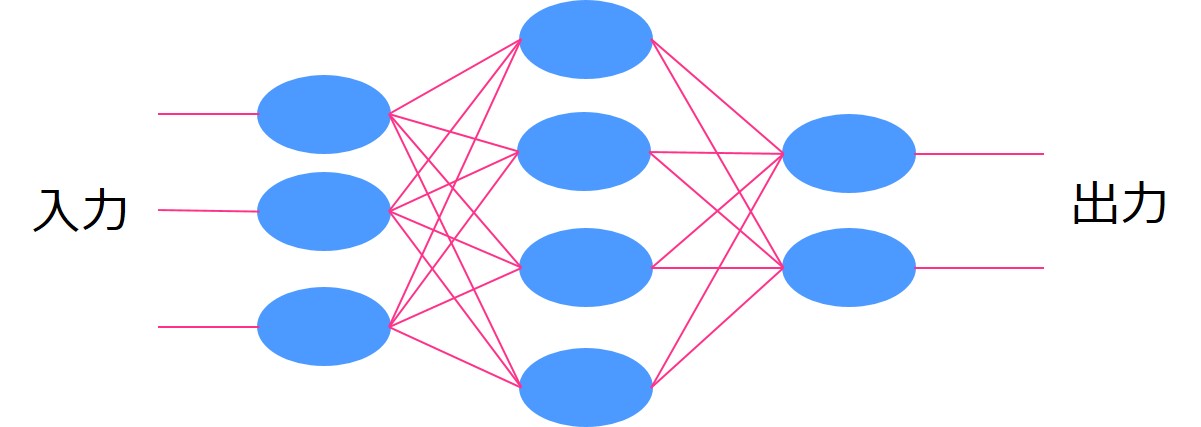
この層を多層にしていくのがディープラーニングなのですが、当時のマシンパワーでは計算量が膨大過ぎて実現不可能でした。
計算負荷を軽減する誤差逆伝播法(バックプロパゲーション)などの計算手法の登場やマシンパワーの増強により現在に至ります。
そんな計算負荷の問題が解消され深層ニューラルネットワーク(ディープラーニング)が日の目を浴びたのは2006年。
このブレークスルーによって再びAIのブームが巻き起こり、第3次AIブームへと突入していくのです。
AIの歴史については以下の記事でまとめていますのでよければご覧ください!

実は、ディープラーニングはアルゴリズム自体は非常にシンプルで昔からある手法なんですねー。
ディープラーニングの詳しくアルゴリズムや仕組みに関しては以下の記事でまとめていますのでチェックしてみてください!

ディープラーニングと機械学習・AIの違いは?
さて、ではそんなディープラーニングと機械学習やAIは何が違うのでしょうか?
結構違いがあやふやで間違った使われ方をしていることもあるのですが、定義は以下のような図のようになっています。
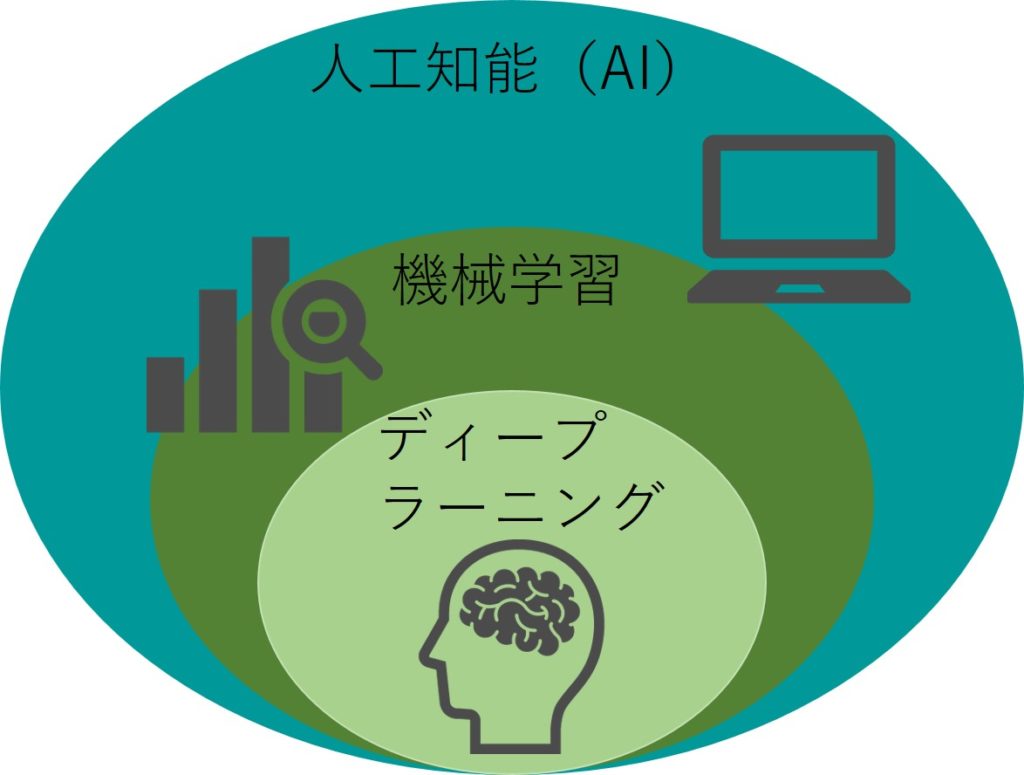
実はAIの中に機械学習があって機械学習の中にディープラーニングがあるという関係なんですねー。
AIというとディープラーニングを思い浮かべるという場合もありますが、本来の定義ではAI=ディープラーニングではないのです。
もちろんAIがディープラーニングを指している文脈もありますので注意が必要です。
機械学習の中には大きく分けて
・教師あり学習 ・教師なし学習 ・強化学習
の3つがありますが、それぞれに属する可能性があるのがディープラーニング。
ディープラーニングは深層学習とも言われるので教師ありなし学習などと並列かと思いきや、別なんですねー。

教師あり学習・教師なし学習については以下の記事でまとめています。

ディープラーニングと機械学習・AIはごっちゃにされてしまうことが多いので、違いを明確に理解しておきましょう!
以下の記事でディープラーニングと機械学習の違いをより詳しくまとめていますのでぜひチェックしてみてください!

ディープラーニングでできることを事例と共に紹介
ディープラーニングの概念や機械学習やAIとの違いが分かったところで、ディープラーニングを用いて実際にどんなことが実現できるのかまとめていきたいと思います!
画像を識別
ディープラーニングと言えば、画像認識!!
犬と猫の画像を大量にインプットさせて学習することで、人間と同程度の識別能力を発揮することができるという例はよく耳にするディープラーニングの定番ですね。
画像のピクセルを特徴量としてインプットさせるので、基本的な機械学習手法の分類問題として解くことも可能です。
ただ、ディープラーニングに畳み込み層と組み合わせたCNN(畳み込みニューラルネットワーク)によって、複雑な画像に対してもより高い精度を出力することが可能になっています。
実際にCNNをPythonで実装してみましょう!
ここで使用するのはMnistという手書き文字のデータセット。 Mnistは「Gradient-based learning applied to document recognition」で用いられたデータセットであり、現在でも多くの論文で用いられています。
Modified National Institute of Standards and Technologyの略であり、0~9の数字が手書き文字として格納されているデータセットです。
学習用に60000枚、検証用に10000枚のデータセットが格納されています。
詳細は省きますが、最終的にテストデータに対して96.96%の精度を算出することができました。
なかなか判別の難しい手書き文字も入っているのでなかなかの精度。
パラメータチューニングを頑張ることで精度を99%くらいまで持っていくことが可能です。
以下の記事で詳しくまとめています。
ちなみに機械学習手法の中でデータ解析コンペでよく使われる勾配ブースティング手法でも同様のMnistのデータを分類させて精度を比較しているのでぜひチェックしてみてください!


結果だけ見ると、
Xgboost>LightGBM>ディープラーニング(CNN)>Catboost
となってます。
どれも非常に高い精度を誇っており、シンプルに実装しているのでもう少しパラメータチューニングをすることで精度の逆転は全然あり得ます。
体感としてはライトに実装するならLightGBM、本気で精度求めるならCNNかなーという感じ。
文脈を読み取る
ディープラーニングを用いて文章を予測したり文脈を読み取ることが可能です。
そしてそのような手法群は専門用語では自然言語処理と言われます。
実は、文脈を読み取ることは過去データの流れから未来のデータを予測することになるので、広義では時系列問題となるんですねー!
そこで登場するのがRecurrent neural network(再帰型ニューラルネットワーク)。
RNNと略されて呼ばれます。
今までのディープラーニングでは、時系列要素はなくシンプルにいくつかの同列要素のインプットに対して重みパラメータを変化させて出力を調整します。
RNNでは同一の中間層を用いて再帰的にインプットが行われます。
再帰的という部分がReccurentと言われるゆえんです。
こんなイメージ
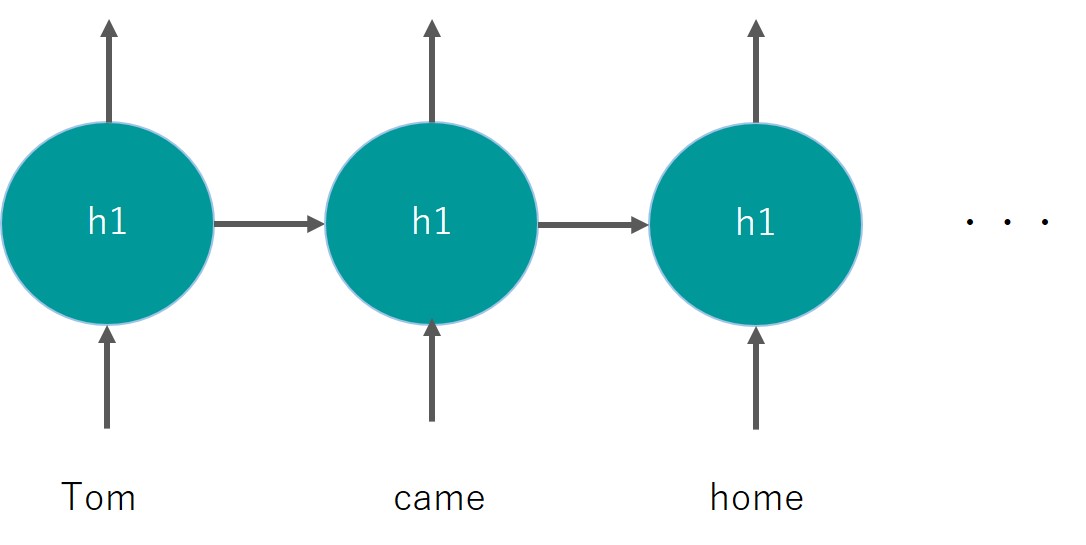
同じレイヤーh1を用いているのがミソです。
なんとなーく、こんなもんなんだなーくらいの理解で大丈夫です。
Google翻訳や音声AIなどにもRNNの概念が用いられています。
テキストであろうが音声であろうが、文脈を読み取る技術にディープラーニングが用いられているんですね。
RNNを用いて時系列問題を解いてみましょう!
使うデータセットはKaggleのホームページが落とせる航空会社の乗客数データ!
1949年から1960年までの月別乗客数がデータとして入っています。
149行2列のシンプルなデータセット。
1変数の時系列データを基に過去のデータから未来の値を予測します。
この時、tflearnというライブラリを使ってRNN(正確にはLSTM)を実装していきます。tflearnはkerasと似たようなライブラリでディープラーニングの実装が感覚的に容易にできます。
実際にモデルを構築していきましょう!
最終的な評価はRMSE(Root Mean Square Error)で算出しています。
RMSEは0.10079201となりました。
それなりに良い予測ができてる!
RNNについては以下の記事で詳しくまとめていますのでチェックしてみてください!

自然言語処理では、Googleが2019年に正式にアルゴリズム導入を決めたBERTについてもあわせてチェックしておくと理解が深まるでしょう!
Pythonで実際に文章予測を行ってます。

画像→テキスト生成
そんなディープラーニングの画像識別の技術と文脈予測の技術を組み合わせることで、画像から自動的にテキストを生成することが可能です。
 (引用元:Google-“Show and Tell: A Neural Image Caption Generator“)
(引用元:Google-“Show and Tell: A Neural Image Caption Generator“)
これを見るとかなりの高精度で画像データを読み取りテキスト変換することが出来ていることが分かります。
フェイク画像生成
続いて、GAN(敵対的生成ネットワーク)という手法によって存在しない画像を生成することが可能です。
実際に存在しないホテルの部屋の画像を生成したのが以下になります。

(引用元: Google-“UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS” )
GANでは2つのニューラルネットワークを使います。片方がGenerator、もう片方がDiscriminator。
Generatorが生成した偽物のデータと実際に存在する本物のデータをDiscriminatorに判別させ、 Discriminatorが上手く判別できないようなデータを Generator が生成していきます。
Discriminatorはどんどん判別の難しくなるデータを上手く判別できるようにしていきます。
この学習が進むと最終的にGeneratorが生成される画像は本物にきわめて近くなっているという手法です。
実際の写真にゴッホのタッチを合成することも可能なんです。

(引用元:https://github.com/jcjohnson/neural-style)
GANについて詳しくは以下の記事で解説しています!

最適化
囲碁でAIが人間を負かしたのは記憶に新しいと思います。
そのAIのアルゴリズムに搭載されているのがこの「Deep Q Network」。
強化学習であるQ-Learningにディープラーニングを応用した作りになっています。
強化学習自体は、ゲームのCPUの動きに適応されるなど既に様々な分野で実装されていました。
しかし、強化学習はそもそも学習に時間がかかるため行動パターンが複雑だと解を導くことができません。
囲碁は19×19もの数の交点があり、状態(s)と行動(a)のパターンが膨大です。
そこで登場したのがディープラーニング。
ディープラーニングとQ学習を組み合わせたDeep-Q-networkという手法が開発され、それを基にプロ棋士をも凌駕する人工知能Alpha Goが作られたのです。

ディープラーニングができないこと
ここまででディープラーニングができることについて徹底的にまとめてきましたが、まだまだディープラーニングができないことは多くあります。
現在の延長線上では、ディープラーニングが真の人工知能を実現できるとは思えません。
ダーウィンの進化論は、
・生物は突然変異(一種のエラー)が稀に起きる
・その変異が現環境に優位だとその種が生き残る優位な特性が得られるように変異してきたわけじゃなくて、悪い変異もめちゃくちゃ起こるんです。
つまり、様々な変異が起きるようにプログラムしないと真の人工知能はあり得ない
— ウマたん@スタビジ (@statistics1012) January 13, 2020
そのため論点として、ディープラーニングができないことは、
・現在のディープラーニングの延長線上で実現可能だけど現在できていないこと
・現在のディープラーニングの延長線上では実現不可能なこと
の2つに分けて考えた方がいいです。
延長線上で実現可能だけど現在できていないこと
この領域に関してはいろいろとあると思います。
例えば、音声分離の問題がありますねー。
現在音声AIの技術は日々進歩していますが、複数人が話している音声を上手く分離して聞き取ることはほぼ不可能です。
音声認識の課題は話者分離
単独話者のスピーチなどは相当精度が上がってきてるけど、多数での会話を話者分離して音声認識するのはまだまだハードルが高い
— ウマたん@スタビジ (@statistics1012) January 30, 2020
また、自動運転や翻訳などの精度もまだまだ完璧ではありません。
ただここら辺の技術は精度が向上していけば実現するのは時間の問題ですね。
延長線上では実現不可能なこと
現在の延長線上では、ディープラーニングはどう考えても人間以上の知能を得ることはできません。
ある種、過去にデータのあることは見通すことが出来ても過去に事例のないケースはディープラーニングでは予測不可能なんです。
さらにあえて過去の成功を踏襲せず失敗に踏み込むことが大きな成功につながることがあります。
前のアリが辿った経路を完璧に辿れる優秀なアリだけのアリ塚と、ランダムで経路を間違えるダメアリが混ざったアリ塚で、どっちがエサを効率的に運べるか・・・実は後者
思わぬミスが最適経路の発見に繋がるんです
一定のエラーは全体最適になる
完璧な個体だけの人工知能は全体最適にならない
— ウマたん@スタビジ (@statistics1012) January 13, 2020
アリの世界でさえ局所的な失敗は大局的な成功につながるんです。
そんな観点から考えると、クリエイティブな職能に関してはどれもディープラーニングでは実現できないでしょう。
例えば、起業家・経営者・クリエイティブディレクターなどなど・・・
そして音楽家・芸術家・政治家などの職能もディープラーニングで実現することは難しいです。
しかし、それらの職能の一部はどんどんディープラーニングで代替されていくでしょうねー!
ディープラーニングを学ぶ方法
さて、ここまでディープラーニングができることとできないことについて見てきましたが、そんなディープラーニングを学ぶにはどうすればよいでしょうか?
まずは、機械学習や統計学そしてPythonの土台が必要ですがそれをクリアしている前提なら・・・
理論は以下の書籍が圧倒的に分かりやすいんでぜひチェック!

目から鱗の内容です。アルゴリズムを1からわかりやすーく教えてくれます。
ディープラーニングをちゃんと理解したいなら必読です。

書籍では、Pythonを使ってディープラーニングのアルゴリズムを0から組み立てていくのですが、実際に使う時はライブラリが多数用意されているのでライブラリを使った実データ分析も一緒に学んでいくとよいでしょう!
ライブラリ実装はオンラインスクールもしくはオンライン動画がおすすめ!
オンラインスクールはいくつかありますが、Techacademy(テックアカデミー)のAIコースを受講してみてパーソナルメンターのクオリティが高かったのでおすすめです!
以下にテックアカデミーの体験談をまとめています!
ちなみに当メディアが運営するスクール「スタアカ」でもディープラーニングについてアニメーションを使いながら分かりやすく学べるようになっているので是非チェックしてみてください!
24時間以内の質問対応と現役データサイエンティストによる1週間に1回のメンタリングを実施します!
カリキュラム自体は、他のスクールと比較して圧倒的に良い自信があるのでぜひ受講してみてください!
理論を深めるには先ほどの書籍「ゼロから作るディープラーニング」と並行して進めるのがオススメです。
ディープラーニングのプログラミングスクールは以下の記事で詳しく解説していますのであわせてチェックしてみてください!

ディープラーニングができること まとめ
本記事では、ディープラーニングができることとできないことを徹底的にまとめてきました!
最後にできることについてもう一度まとめておきましょう!
しっかりディープラーニングについて理解しておくことで、これからの時代を生き抜く糧になります!
機械学習や統計学の知識は以下の記事をチェック!


ディープラーニング実装に必要なPythonに関しては以下の記事で勉強方法をまとめているのであわせてチェックしてみてくださいね!

 スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
スタビジのコンテンツをさらに深堀りしたコンテンツが動画と一緒に学べるスクールです。
プレミアムプランでは私がマンツーマンで伴走させていただきます!ご受講お待ちしております!



















